v2.0: image10.png
v2.1: image10.png
Image not present in this version
| @@ -1,3354 +1,105 @@ | |||
| 1 | 1 | <div style="font-size: 0.85em; color: #656d76; margin-bottom: 1em; padding: 0.5em; background: #f6f8fa; border-radius: 4px;"> | |
| 2 | -📄 Source: <a href="https://github.com/chipsalliance/adams-bridge/blob/c6eacc84c4466348950d7a6a449efb913596795c/docs/AdamsBridgeHardwareSpecification.md" target="_blank">chipsalliance/adams-bridge/docs/AdamsBridgeHardwareSpecification.md</a> @ <code>c6eacc8</code> | ||
| 2 | +📄 Source: <a href="https://github.com/chipsalliance/adams-bridge/blob/96cdd1dccadb516d55a990e21c38b897abc648c3/docs/AdamsBridgeHardwareSpecification.md" target="_blank">chipsalliance/adams-bridge/docs/AdamsBridgeHardwareSpecification.md</a> @ <code>96cdd1d</code> | ||
| 3 | 3 | </div> | |
| 4 | 4 | ||
| 5 | 5 |  | |
| 6 | 6 | ||
| 7 | 7 | <p style="text-align: center;">Adam's Bridge Hardware Specification</p> | |
| 8 | 8 | ||
| 9 | -<p style="text-align: center;">Version 1.0.2</p> | ||
| 9 | +<p style="text-align: center;">Version 1.0</p> | ||
| 10 | 10 | ||
| 11 | 11 | <div style="page-break-after: always"></div> | |
| 12 | 12 | ||
| 13 | 13 | # Scope | |
| 14 | 14 | ||
| 15 | -This document defines technical specifications for a Adam's Bridge Post-Quantum Cryptography (PQC ML-DSA) subsystem used in the Open Compute Project (OCP). This document shall comprise the Adam's Bridge technical specification. | ||
| 15 | +This document defines technical specifications for a Adam's Bridge Post-Quantum Cryptography (PQC ML-DSA and ML-KEM) subsystem used in the Open Compute Project (OCP). This document shall comprise the Adam's Bridge technical specification. | ||
| 16 | 16 | ||
| 17 | 17 | # Overview | |
| 18 | 18 | ||
| 19 | -This document provides definitions and requirements for a Adam's Bridge Post-Quantum Cryptography (PQC ML-DSA) subsystem. The document then relates these definitions to existing technologies, enabling device and platform vendors to better understand those technologies in trusted computing terms. | ||
| 19 | +This document provides definitions and requirements for a Adam's Bridge Post-Quantum Cryptography (PQC ML-DSA and ML-KEM) subsystem. The document then relates these definitions to existing technologies, enabling device and platform vendors to better understand those technologies in trusted computing terms. | ||
| 20 | 20 | ||
| 21 | 21 | # Introduction | |
| 22 | 22 | ||
| 23 | 23 | The advent of quantum computers poses a serious challenge to the security of cloud infrastructures and services, as they can potentially break the existing public-key cryptosystems, such as RSA and elliptic curve cryptography (ECC). Even though the gap between today’s quantum computers and the threats they pose to current public-key cryptography is large, the cloud landscape should act proactively and initiate the transition to the post-quantum era as early as possible. To comply with that, the U.S. government issued a National Security Memorandum in May 2022 that mandated federal agencies to migrate to PQC by 2035 \[1\]. | |
| 24 | 24 | ||
| 25 | -The long-term security of cloud computing against quantum attacks depends on developing lattice-based cryptosystems, which are among the most promising PQC algorithms that are believed to be hard for both classical and quantum computers. The American National Institute of Standards and Technology (NIST) recognized this and selected CRYSTALS-KYBER (ML-KEM) and CRYSTALS-Dilithium (ML-DSA) \[2\], two lattice-based algorithms, as standards for post-quantum key-establishment and digital signatures, respectively, in July 2022\. These cryptosystems are constructed on the hardness of the module learning-with-errors problem (M-LWE) in module lattices. | ||
| 25 | +The long-term security of cloud computing against quantum attacks depends on developing lattice-based cryptosystems, which are among the most promising PQC algorithms that are believed to be hard for both classical and quantum computers. The American National Institute of Standards and Technology (NIST) recognized this and selected CRYSTALS-KYBER (ML-KEM) \[2\] and CRYSTALS-Dilithium (ML-DSA) \[3\], two lattice-based algorithms, as standards for post-quantum key-establishment and digital signatures, respectively, in July 2022\. These cryptosystems are constructed on the hardness of the module learning-with-errors problem (M-LWE) in module lattices. | ||
| 26 | 26 | ||
| 27 | 27 | To transition to PQC, we must develop hybrid cryptosystems to maintain industry or government regulations, while PQC updates will be applied thoroughly. Therefore, classical cryptosystems, e.g. ECC, cannot be eliminated even if PQC will significantly be developed. | |
| 28 | 28 | ||
| 29 | 29 | Adam’s bridge was a mythological structure that existed to cross the formidable gulf that existed between two land masses. Asymmetric cryptography to post quantum is a similar formidable gap that exists in the world of cryptography and Adam’s bridge is the work undertaken to bridge the gap by building post quantum cryptographic accelerators. | |
| 30 | 30 | ||
| 31 | -In this presentation, we share the architectural characteristics of our post-quantum Adams Bridge implementation. Our proposed work divides the operations in the algorithms into multiple stages and executes them using pipelined processing architecture. We use an optimized cascading method within each stage and fine-tune each module individually to exploit multi-levels of parallelism to accelerate post-quantum Dilithium computation on hardware platforms to address performance and complexity challenges of PQC implementation. Our proposed architecture uses various optimization techniques, including multi-levels of parallelism, designing reconfigurable cores, and implementing interleaved and pipelined architecture achieving significant speedup while maintaining high security and scalability. Our work can facilitate the adoption and deployment of PQC in cloud computing and enhance the security and efficiency of cloud services and applications in the post-quantum era. | ||
| 31 | +This document shares the architectural characteristics of the proposed post-quantum Adams Bridge implementation. The proposed work divides the operations in the algorithms into multiple stages and executes them using pipelined processing architecture. An optimized cascading method is used within each stage and fine-tune each module individually to exploit multi-levels of parallelism to accelerate post-quantum Dilithium computation on hardware platforms to address performance and complexity challenges of PQC implementation. The proposed architecture uses various optimization techniques, including multi-levels of parallelism, designing reconfigurable cores, and implementing interleaved and pipelined architecture achieving significant speedup while maintaining high security and scalability. This work can facilitate the adoption and deployment of PQC in cloud computing and enhance the security and efficiency of cloud services and applications in the post-quantum era. | ||
| 32 | 32 | ||
| 33 | -# High-Level Overview | ||
| 33 | +# Documentation | ||
| 34 | 34 | ||
| 35 | -Adam’s Bridge accelerator has all the necessary components to execute a pure hardware PQC operation. The main operations that involve more computational complexity, such as NTT, hashing, and sampling units, are explained as follows. | ||
| 35 | +The project contains comprehensive documentation of all submodules for ML-DSA and ML-KEM: | ||
| 36 | 36 | ||
| 37 | -  | ||
| 37 | +- [ML-DSA Documentation](./AdamsBridge_MLDSA.md) | ||
| 38 | +- [ML-KEM Documentation](./AdamsBridge_MLKEM.md) | ||
| 39 | +- [Side-Channel Analysis countermeasures](./AdamsBridgeSCA.md) | ||
| 38 | 40 | ||
| 39 | -The security level of ML-DSA defined by NIST are as follows: | ||
| 41 | +# Memory requirement | ||
| 40 | 42 | ||
| 41 | -| Algorithm Name | Security Level | | ||
| 42 | -| :------------- | :------------- | | ||
| 43 | -| ML-DSA-44 | Level-2 | | ||
| 44 | -| ML-DSA-65 | Level-3 | | ||
| 45 | -| **ML-DSA-87** | **Level-5** | | ||
| 46 | - | ||
| 47 | - | ||
| 48 | -CNSA 2.0 only allows the highest security level (Level-5) for PQC which is ML-DSA-87, and **Adams Bridge only supports ML-DSA-87 parameter set.** | ||
| 49 | - | ||
| 50 | -# API | ||
| 51 | - | ||
| 52 | -The ML-DSA-87 architecture inputs and outputs are described in the following table. | ||
| 53 | - | ||
| 54 | - | ||
| 55 | -| Name | Input/Output | Operation | Size (Byte) | | ||
| 56 | -| --------------------------- | --------------- | --------------- | ------------- | | ||
| 57 | -| name | Output | All | 8 | | ||
| 58 | -| version | Output | All | 8 | | ||
| 59 | -| ctrl | Input | All | 4 | | ||
| 60 | -| status | Output | All | 4 | | ||
| 61 | -| entropy (SCA) | Input | All | 64 | | ||
| 62 | -| seed | Input | Keygen | 32 | | ||
| 63 | -| sign\_rnd | Input | Sign | 32 | | ||
| 64 | -| message | Input | Sign/Verify | 64 | | ||
| 65 | -| verification result | Output | Verify | 64 | | ||
| 66 | -| External_Mu | Input | Sign/Verify | 64 | | ||
| 67 | -| message strobe | Input | Sign/Verify | 1 | | ||
| 68 | -| ctx size | Input | Sign/Verify | 1 | | ||
| 69 | -| ctx | Input | Sign/Verify | 255 (+1) | | ||
| 70 | -| pk | Input/Output | Keygen/Verify | 2592 | | ||
| 71 | -| signature | Input/Output | Sign/Verify | 4627 (+1) | | ||
| 72 | -| sk\_out (software only) | Output | Keygen | 4896 | | ||
| 73 | -| sk\_in | Input | Signing | 4896 | | ||
| 74 | -| Interrupt | Output | All | 520 | | ||
| 75 | -| --------------------------- | --------------- | --------------- | ------------- | | ||
| 76 | -| Total ||| 18440 | | ||
| 77 | - | ||
| 78 | - | ||
| 79 | -## name | ||
| 80 | - | ||
| 81 | -Read-only register consists of the name of component. | ||
| 82 | - | ||
| 83 | -## version | ||
| 84 | - | ||
| 85 | -Read-only register consists of the version of component. | ||
| 86 | - | ||
| 87 | -## CTRL | ||
| 88 | - | ||
| 89 | -The control register consists of the following flags: | ||
| 90 | - | ||
| 91 | -| Bits | Identifier | Access | Reset | Decoded | Name | | ||
| 92 | -| :------- | :---------- | :----- | :---- | :------ | :--- | | ||
| 93 | -| \[31:7\] | \- | \- | \- || \- | | ||
| 94 | -| \[6\] | STREAM_MSG | w | 0x0 || \- | | ||
| 95 | -| \[5\] | EXTERNAL_MU | w | 0x0 || \- | | ||
| 96 | -| \[4\] | PCR_SIGN | w | 0x0 || \- | | ||
| 97 | -| \[3\] | ZEROIZE | w | 0x0 || \- | | ||
| 98 | -| \[2:0\] | CTRL | w | 0x0 || \- | | ||
| 99 | - | ||
| 100 | - | ||
| 101 | -### CTRL | ||
| 102 | - | ||
| 103 | -CTRL command field contains two bits indicating: | ||
| 104 | - | ||
| 105 | -* Ctrl \= 0b000 | ||
| 106 | - | ||
| 107 | -No Operation. | ||
| 108 | - | ||
| 109 | -* Ctrl \= 0b001 | ||
| 110 | - | ||
| 111 | -Trigs the core to start the initialization and perform keygen operation. | ||
| 112 | - | ||
| 113 | -* Ctrl \= 0b010 | ||
| 114 | - | ||
| 115 | -Trigs the core to start the signing operation for a message block. | ||
| 116 | - | ||
| 117 | -* Ctrl \= 0b011 | ||
| 118 | - | ||
| 119 | -Trigs the core to start verifying a signature for a message block. | ||
| 120 | - | ||
| 121 | -* Ctrl \= 0b100 | ||
| 122 | - | ||
| 123 | -Trigs the core to start the keygen+signing operation for a message block. This mode decreases storage costs for the secret key (SK) by recalling keygen and using an on-the-fly SK during the signing process. | ||
| 124 | - | ||
| 125 | -### ZEROIZE | ||
| 126 | - | ||
| 127 | -Zeroize all internal registers: Zeroize all internal registers after process to avoid SCA leakage. | ||
| 128 | -Firmware write generates only a single-cycle pulse on the hardware interface and then will be erased. | ||
| 129 | -Zeroization operation requires 1,408 clock cycles to clear the SRAMs. Firmware must query for the ready status bit to be asserted before issuing another command. | ||
| 130 | - | ||
| 131 | -### PCR_SIGN | ||
| 132 | - | ||
| 133 | -Run PCR Signing flow: Run MLDSA KeyGen+Signing flow to sign PCRs. | ||
| 134 | - | ||
| 135 | -### EXTERNAL_MU | ||
| 136 | - | ||
| 137 | -Enable External_Mu Mode. (this mode is hard turned off for now.) | ||
| 138 | -The External_mu variant of ML-DSA modifies the standard signing and verifying process by allowing the precomputed mu to be externally provided instead of being internally derived from the message and public key. In this variant, the signing procedure accepts mu as an explicit input, making it suitable for environments where mu is generated offline for efficiency. While the core signing and verifying algorithm remains unchanged, the message input register is ignored in this mode. | ||
| 139 | - | ||
| 140 | -### STREAM_MSG | ||
| 141 | - | ||
| 142 | -Enable streaming message mode. | ||
| 143 | - | ||
| 144 | -In this mode, the controller will wait until it requires the message data and will assert the MSG_STREAM_READY bit in the status register. Once MSG_STREAM_READY is observed, the user should first set MSG_STROBE to 0xF. | ||
| 145 | - | ||
| 146 | -The user can then write the message, one dword at a time, by writing to dword 0 of the message register. If the last dword is partial, the user must set the MSG_STROBE register to appropriately indicate the valid bytes. If the message is dword-aligned, a value of 0x0 must be written to the MSG_STROBE register to indicate the last dword, followed by a dummy write to the message register. | ||
| 147 | - | ||
| 148 | -The flow must be terminated by writing to the message register after setting the MSG_STROBE to a non 0xF value. | ||
| 149 | -No partial dwords are allowed before the last dword indication. | ||
| 150 | -MSG_STROBE only needs to be programmed before the stream of full dwords, and before the final dword. | ||
| 151 | -Valid values of MSG_STROBE include 4'b1111, 4'b0111, 4'b0011, 4'b0001, and 4'b0000. | ||
| 152 | - | ||
| 153 | -## status | ||
| 154 | - | ||
| 155 | -The read-only status register consists of the following flags: | ||
| 156 | - | ||
| 157 | -| Bits | Identifier | Access | Reset | Decoded | Name | | ||
| 158 | -| :------- | :--------- | :----- | :---- | :------ | :--- | | ||
| 159 | -| \[31:3\] | \- | \- | \- || \- | | ||
| 160 | -| \[2\] | MSG_STREAM_READY | r | 0x0 || \- | | ||
| 161 | -| \[1\] | VALID | r | 0x0 || \- | | ||
| 162 | -| \[0\] | READY | r | 0x0 || \- | | ||
| 163 | - | ||
| 164 | - | ||
| 165 | -### READY | ||
| 166 | - | ||
| 167 | -Indicates if the core is ready to process the inputs. | ||
| 168 | - | ||
| 169 | -### VALID | ||
| 170 | - | ||
| 171 | -Indicates if the process is computed and the output is valid. | ||
| 172 | - | ||
| 173 | -### MSG_STREAM_READY | ||
| 174 | - | ||
| 175 | -Indicates if the core is ready to process the message. | ||
| 176 | - | ||
| 177 | -## entropy | ||
| 178 | - | ||
| 179 | -Entropy is required for SCA countermeasures to randomize the inputs with no change in the outputs. The entropy can be any 512-bit value in \[0 : 2^512-1\]. | ||
| 180 | - | ||
| 181 | -The ML-DSA-87 countermeasure requires several random vectors to randomize the intermediate values. An internal mechanism is considered to take one random vector of 512-bit (i.e., entropy register) and generate the required random vectors for different countermeasures. | ||
| 182 | - | ||
| 183 | -## seed | ||
| 184 | - | ||
| 185 | -Adams Bridge component seed register type definition 8 32-bit registers storing the 256-bit seed for keygen. The seed can be any 256-bit value in \[0 : 2^256-1\]. | ||
| 186 | - | ||
| 187 | -## sign\_rnd | ||
| 188 | - | ||
| 189 | -This register is used to support both deterministic and hedge variants of ML-DSA. The content of this register is the only difference between the deterministic and hedged variant of ML-DSA. | ||
| 190 | - | ||
| 191 | -- In the “hedged” variant, sign\_rnd is the output of an RBG. | ||
| 192 | -- In the “deterministic” variant, sign\_rnd is a 256-bit string consisting entirely of zeroes. | ||
| 193 | - | ||
| 194 | -## message | ||
| 195 | - | ||
| 196 | -When not in streaming message mode, this architecture supports PureML-DSA defined by NIST with an empty ctx. | ||
| 197 | -When streaming message mode is enabled, this field is ignored except for dword 0 which is used to stream in the message. | ||
| 198 | - | ||
| 199 | -## verification result | ||
| 200 | - | ||
| 201 | -To mitigate a possible fault attack on Boolean flag verification result, a 64-byte register is considered. Firmware is responsible for comparing the computed result with a certain segment of signature (segment c\~), and if they are equal the signature is valid. | ||
| 202 | - | ||
| 203 | -## msg strobe | ||
| 204 | - | ||
| 205 | -A 4-bit indication of enabled bytes in the next dword of the streamed message. | ||
| 206 | -Users must first program this to 0xF after observing MSG_STREAM_READY, unless the message is less than 1 dword. | ||
| 207 | -If the final dword is partial, MSG_STROBE must be programmed appropriately before writing the final bytes. | ||
| 208 | -Dword aligned messages must program MSG_STROBE to 0x0 to indicate the message is done being streamed. | ||
| 209 | - | ||
| 210 | -## ctx size | ||
| 211 | - | ||
| 212 | -A 8-bit indication of the size in bytes of the ctx to be used. | ||
| 213 | - | ||
| 214 | -## ctx | ||
| 215 | - | ||
| 216 | -This register stores the ctx field. It is applied only during streaming message mode. | ||
| 217 | - | ||
| 218 | -## sk\_out | ||
| 219 | - | ||
| 220 | -This register stores the private key for keygen if seed is given by software. This register can be read by ML-DSA user, i.e., software, after keygen operation. | ||
| 221 | - | ||
| 222 | -If seed comes from the key vault, this register will not contain the private key to avoid exposing secret assets to software. | ||
| 223 | - | ||
| 224 | -## sk\_in | ||
| 225 | - | ||
| 226 | -This register stores the private key for signing. This register should be set before signing operation. | ||
| 227 | - | ||
| 228 | -## pk | ||
| 229 | - | ||
| 230 | -ML-DSA component public key register type definition storing the public key. This register can be read by Adams Bridge user after keygen operation, or be set before verifying operation. | ||
| 231 | - | ||
| 232 | -## signature | ||
| 233 | - | ||
| 234 | -ML-DSA component signature register type definition storing the signature of the message. This register is read by Adams Bridge user after signing operation, or be set before verifying operation. | ||
| 235 | - | ||
| 236 | -# Pseudocode | ||
| 237 | - | ||
| 238 | -## Keygen | ||
| 239 | - | ||
| 240 | -```cpp | ||
| 241 | -Input: | ||
| 242 | - seed | ||
| 243 | - entropy | ||
| 244 | - | ||
| 245 | -Output: | ||
| 246 | - sk_out | ||
| 247 | - pk | ||
| 248 | - | ||
| 249 | -// Wait for the core to be ready (STATUS flag should be 2'b01 or 2'b11) | ||
| 250 | -read_data = 0 | ||
| 251 | -while read_data == 0: | ||
| 252 | - read_data = read(ADDR_STATUS) | ||
| 253 | - | ||
| 254 | -// Feed the required inputs | ||
| 255 | -write(ADDR_SEED, seed) | ||
| 256 | -write(ADDR_ENTROPY, entropy) | ||
| 257 | - | ||
| 258 | -// Trigger the core for performing Keygen | ||
| 259 | -write(ADDR_CTRL, KEYGEN_CMD) // (STATUS flag will be changed to 2'b00) | ||
| 260 | - | ||
| 261 | -// Wait for the core to be ready and valid (STATUS flag should be 2'b11) | ||
| 262 | -read_data = 0 | ||
| 263 | -while read_data == 0: | ||
| 264 | - read_data = read(ADDR_STATUS) | ||
| 265 | - | ||
| 266 | -// Reading the outputs | ||
| 267 | -sk_out = read(ADDR_SK) | ||
| 268 | -pk = read(ADDR_PK) | ||
| 269 | - | ||
| 270 | -// Return the outputs | ||
| 271 | -return sk_out, pk | ||
| 272 | -``` | ||
| 273 | - | ||
| 274 | -## Signing | ||
| 275 | - | ||
| 276 | -```cpp | ||
| 277 | -Input: | ||
| 278 | - msg | ||
| 279 | - sk_in | ||
| 280 | - sign_rnd | ||
| 281 | - entropy | ||
| 282 | - | ||
| 283 | -Output: | ||
| 284 | - signature | ||
| 285 | - | ||
| 286 | -// Wait for the core to be ready (STATUS flag should be 2'b01 or 2'b11) | ||
| 287 | -read_data = 0; | ||
| 288 | -while (read_data == 0) { | ||
| 289 | - read_data = read(ADDR_STATUS); | ||
| 290 | -} | ||
| 291 | - | ||
| 292 | -// Feed the required inputs | ||
| 293 | -write(ADDR_MSG, msg); | ||
| 294 | -write(ADDR_SK_IN, sk_in); | ||
| 295 | -write(ADDR_SIGN_RND, sign_rnd); | ||
| 296 | -write(ADDR_ENTROPY, entropy); | ||
| 297 | - | ||
| 298 | -// Trigger the core for performing Signing | ||
| 299 | -write(ADDR_CTRL, SIGN_CMD); // (STATUS flag will be changed to 2'b00) | ||
| 300 | - | ||
| 301 | -// Wait for the core to be ready and valid (STATUS flag should be 2'b11) | ||
| 302 | -read_data = 0; | ||
| 303 | -while (read_data == 0) { | ||
| 304 | - read_data = read(ADDR_STATUS); | ||
| 305 | -} | ||
| 306 | - | ||
| 307 | -// Reading the outputs | ||
| 308 | -signature = read(ADDR_SIGNATURE); | ||
| 309 | - | ||
| 310 | -// Return the output (signature) | ||
| 311 | -return signature; | ||
| 312 | -``` | ||
| 313 | - | ||
| 314 | -## Verifying | ||
| 315 | - | ||
| 316 | -```cpp | ||
| 317 | -Input: | ||
| 318 | - msg | ||
| 319 | - pk | ||
| 320 | - signature | ||
| 321 | - | ||
| 322 | -Output: | ||
| 323 | - verification_result | ||
| 324 | - | ||
| 325 | -// Wait for the core to be ready (STATUS flag should be 2'b01 or 2'b11) | ||
| 326 | -read_data = 0; | ||
| 327 | -while (read_data == 0) { | ||
| 328 | - read_data = read(ADDR_STATUS); | ||
| 329 | -} | ||
| 330 | - | ||
| 331 | -// Feed the required inputs | ||
| 332 | -write(ADDR_MSG, msg); | ||
| 333 | -write(ADDR_PK, pk); | ||
| 334 | -write(ADDR_SIGNATURE, signature); | ||
| 335 | - | ||
| 336 | -// Trigger the core for performing Verifying | ||
| 337 | -write(ADDR_CTRL, VERIFY_CMD); // (STATUS flag will be changed to 2'b00) | ||
| 338 | - | ||
| 339 | -// Wait for the core to be ready and valid (STATUS flag should be 2'b11) | ||
| 340 | -read_data = 0; | ||
| 341 | -while (read_data == 0) { | ||
| 342 | - read_data = read(ADDR_STATUS); | ||
| 343 | -} | ||
| 344 | - | ||
| 345 | -// Reading the outputs | ||
| 346 | -verification_result = read(ADDR_VERIFICATION_RESULT); | ||
| 347 | - | ||
| 348 | -// Return the output (verification_result) | ||
| 349 | -return verification_result; | ||
| 350 | -``` | ||
| 351 | - | ||
| 352 | -## Keygen \+ Signing | ||
| 353 | - | ||
| 354 | -This mode decreases storage costs for the secret key (SK) by recalling keygen and using an on-the-fly SK during the signing process. | ||
| 355 | - | ||
| 356 | -```cpp | ||
| 357 | -Input: | ||
| 358 | - seed | ||
| 359 | - msg | ||
| 360 | - sign_rnd | ||
| 361 | - entropy | ||
| 362 | - | ||
| 363 | -Output: | ||
| 364 | - signature | ||
| 365 | - | ||
| 366 | -// Wait for the core to be ready (STATUS flag should be 2'b01 or 2'b11) | ||
| 367 | -read_data = 0; | ||
| 368 | -while (read_data == 0) { | ||
| 369 | - read_data = read(ADDR_STATUS); | ||
| 370 | -} | ||
| 371 | - | ||
| 372 | -// Feed the required inputs | ||
| 373 | -write(ADDR_SEED, seed); | ||
| 374 | -write(ADDR_MSG, msg); | ||
| 375 | -write(ADDR_SIGN_RND, sign_rnd); | ||
| 376 | -write(ADDR_ENTROPY, entropy); | ||
| 377 | - | ||
| 378 | -// Trigger the core for performing Keygen + Signing | ||
| 379 | -write(ADDR_CTRL, KEYGEN_SIGN_CMD); // (STATUS flag will be changed to 2'b00) | ||
| 380 | - | ||
| 381 | -// Wait for the core to be ready and valid (STATUS flag should be 2'b11) | ||
| 382 | -read_data = 0; | ||
| 383 | -while (read_data == 0) { | ||
| 384 | - read_data = read(ADDR_STATUS); | ||
| 385 | -} | ||
| 386 | - | ||
| 387 | -// Reading the outputs | ||
| 388 | -signature = read(ADDR_SIGNATURE); | ||
| 389 | - | ||
| 390 | -// Return the output (signature) | ||
| 391 | -return signature; | ||
| 392 | -``` | ||
| 393 | - | ||
| 394 | -# Performance and Area Results | ||
| 395 | - | ||
| 396 | -## ML-DSA-87 | ||
| 397 | - | ||
| 398 | -The performance results for two operational frequencies, 400 MHz and 600 MHz, are presented in terms of latency (clock cycles [CCs]), time [ms], and performance [IOPS] as follows: | ||
| 399 | - | ||
| 400 | -|| Freq [MHz] | 400 ||| 600 || | ||
| 401 | -| --------------------- | ---------------- | ------------: | ---------------------- | --- | ------------: | ---------------------- | | ||
| 402 | -| **"Unprotected"** | **Latency [CC]** | **Time [ms]** | **Performance [IOPS]** || **Time [ms]** | **Performance [IOPS]** | | ||
| 403 | -| **Keygen** | 15,600 | 0.039 | 25,641 || 0.026 | 38,462 | | ||
| 404 | -| **Signing (1 round)** | 26,600 | 0.067 | 15,038 || 0.044 | 22,556 | | ||
| 405 | -| **Signing (Ave)** | 106,400 | 0.266 | 3,759 || 0.177 | 5,639 | | ||
| 406 | -| **Verifying** | 18,800 | 0.047 | 21,277 || 0.031 | 31,915 | | ||
| 407 | - | ||
| 408 | - | ||
| 409 | - | ||
| 410 | -**NOTE:** Masking and shuffling countermeasures are integrated into the architecture and there is a work-in-progress to make it configureble to be enabled or disabled at synthesis time. | ||
| 411 | - | ||
| 412 | -The area overhead associated with enabling these countermeasures is as follows: | ||
| 413 | - | ||
| 414 | -|| Freq [MHz] | 400 ||| 600 || | ||
| 415 | -| --------------------- | ---------------- | ------------: | ---------------------- | --- | ------------: | ---------------------- | | ||
| 416 | -| **"Protected"** | **Latency [CC]** | **Time [ms]** | **Performance [IOPS]** || **Time [ms]** | **Performance [IOPS]** | | ||
| 417 | -| **keygen** | 15,600 | 0.039 | 25,641 || 0.026 | 38,462 | | ||
| 418 | -| **Signing (1 round)** | 36,700 | 0.092 | 10,899 || 0.061 | 16,349 | | ||
| 419 | -| **Signing (Ave)** | 146,800 | 0.367 | 2,725 || 0.245 | 4,087 | | ||
| 420 | -| **Verifying** | 18,800 | 0.047 | 21,277 || 0.031 | 31,915 | | ||
| 421 | - | ||
| 422 | - | ||
| 423 | - | ||
| 424 | - | ||
| 425 | -- CNSA 2.0 only allows the highest security level (Level-5) for PQC which is ML-DSA-87, and **Adams Bridge only supports ML-DSA-87 parameter set.** | ||
| 426 | -- The requried area for the unprotected ML-DSA-87 is 0.0366mm2 @5nm: | ||
| 427 | - - 0.0146mm2 for stdcell | ||
| 428 | - - 0.0220mm2 for ram area for 57.38 KB memory. | ||
| 429 | - | ||
| 430 | -- The requried area for the protected ML-DSA-87 is 0.114mm2 @5nm: | ||
| 431 | - - 0.0921mm2 for stdcell | ||
| 432 | - - 0.0220mm2 for ram area for 57.38 KB memory. | ||
| 433 | - | ||
| 434 | -- The design is converging today at 600MHz at low, med & high voltage corners. (We have noticed the design converging to 1 GHz on a latest process node.) | ||
| 435 | - | ||
| 436 | -### Memory requirement | ||
| 437 | - | ||
| 438 | -The following table shows the required memory instances for ML-DSA-87: | ||
| 43 | +The following table shows the required memory instances for Adam's Bridge: | ||
| 439 | 44 | ||
| 440 | 45 | | Instance | Depth | Data Width | Strobe Width | | |
| 441 | -| -------------------------------------------- | ----- | ---------- | ------------ | | ||
| 442 | -| mldsa_top.mldsa_ctrl_inst.mldsa_sk_ram_bank0 | 596 | 32 || | ||
| 443 | -| mldsa_top.mldsa_ctrl_inst.mldsa_sk_ram_bank1 | 596 | 32 || | ||
| 444 | -| mldsa_top.mldsa_w1_mem_inst | 512 | 4 || | ||
| 445 | -| mldsa_top.mldsa_ram_inst0_bank0 | 832 | 96 || | ||
| 446 | -| mldsa_top.mldsa_ram_inst0_bank1 | 832 | 96 || | ||
| 447 | -| mldsa_top.mldsa_ram_inst1 | 576 | 96 || | ||
| 448 | -| mldsa_top.mldsa_ram_inst2 | 1408 | 96 || | ||
| 449 | -| mldsa_top.mldsa_ram_inst3 | 128 | 96 || | ||
| 450 | -| mldsa_top.mldsa_ctrl_inst.mldsa_sig_z_ram | 224 | 160 | 8 | | ||
| 451 | -| mldsa_top.mldsa_ctrl_inst.mldsa_pubkey_ram | 64 | 320 | 8 | | ||
| 46 | +| -------------------- | ----- | ---------- | ------------ | | ||
| 47 | +| abr_sk_mem_bank0 | 596 | 32 || | ||
| 48 | +| abr_sk_mem_bank1 | 596 | 32 || | ||
| 49 | +| abr_w1_mem | 512 | 4 || | ||
| 50 | +| abr_mem_inst0_bank0 | 800 | 96 || | ||
| 51 | +| abr_mem_inst0_bank1 | 800 | 96 || | ||
| 52 | +| abr_mem_inst1 | 64 | 96 || | ||
| 53 | +| abr_mem_inst2 | 1536 | 96 || | ||
| 54 | +| abr_sig_z_mem | 224 | 160 | 20 | | ||
| 55 | +| abr_pk_mem | 64 | 320 | 40 | | ||
| 452 | 56 | ||
| 453 | 57 | ||
| 454 | 58 | All memories are modeled as 1 read 1 write port RAMs with a flopped read data. | |
| 455 | 59 | See abr_1r1w_ram.sv and abr_1r1w_be_ram.sv for examples. | |
| 60 | +Strobe width describes the number of bits enabled by each strobe. All strobed memories are byte enabled in the design. | ||
| 456 | 61 | ||
| 457 | -### Signing perofrmance | ||
| 62 | +## Masking-protected memory (MASKING_EN = 1) | ||
| 458 | 63 | ||
| 459 | -The signing operation is the most time-consuming part of the MLDSA algorithm. However, it is not constant-time due to the inherent nature of ML-DSA. The signing process involves a loop that continues until all validity checks are passed. The number of iterations depends on the provided privkey, message, and sign_rnd. | ||
| 64 | +When the top-level `MASKING_EN` parameter is set to 1, four additional SRAM instances are generated to hold the second share of all masked operands. These mirror the dimensions of the corresponding regular memory instances: | ||
| 460 | 65 | ||
| 461 | -According to FIPS 204 recommendations, there is no mechanism to interrupt the signing loop. Nevertheless, for the ML-DSA-87 parameter set, the average number of required loops is 3.85. | ||
| 462 | - | ||
| 463 | -# Proposed architecture | ||
| 464 | - | ||
| 465 | -The value of k and l is determined based on the security level of the system defined by NIST as follows: | ||
| 466 | - | ||
| 467 | -| Algorithm Name | Security Level | k | l | | ||
| 468 | -| :------------- | :------------- | :-- | :-- | | ||
| 469 | -| ML-DSA-87 | Level-5 | 8 | 7 | | ||
| 66 | +| Instance | Depth | Data Width | Strobe Width | | ||
| 67 | +| -------------------------- | ----- | ---------- | ------------ | | ||
| 68 | +| abr_mem_inst0_bank0_masked | 800 | 96 || | ||
| 69 | +| abr_mem_inst0_bank1_masked | 800 | 96 || | ||
| 70 | +| abr_mem_inst1_masked | 64 | 96 || | ||
| 71 | +| abr_mem_inst2_masked | 1536 | 96 || | ||
| 470 | 72 | ||
| 471 | 73 | ||
| 472 | -In the hardware design, using an instruction-set processor yields a smaller, simpler, and more controllable design. By fine-tuning hardware acceleration, we achieve efficiency without excessive logic overhead. We implement all computation blocks in hardware while maintaining flexibility for future extensions. This adaptability proves crucial in a rapidly evolving field like post-quantum cryptography (PQC), even amidst existing HW architectures. | ||
| 74 | +Regular and masked SRAMs together carry the two-share representation of each coefficient: the regular memory holds `share0` (uniform random) and the masked memory holds `share1` where `share0 + share1 = data`. When `MASKING_EN = 0` the masked instances are not instantiated and their interface read data is tied to zero. | ||
| 473 | 75 | ||
| 474 | -The Customized Instruction-Set Cryptography Engine is designed to provide efficient cryptographic operations while allowing flexibility for changes in NIST ML-DSA standards and varying security levels. This proposal outlines the architecture, instruction set design, sequencer functionality, and hardware considerations for the proposed architecture. This architecture is typically implemented as an Intellectual Property (IP) core within an FPGA or ASIC, featuring a pipelined design for streamlined execution and interfaces for seamless communication with the host processor. | ||
| 76 | +# Zeroize | ||
| 475 | 77 | ||
| 476 | -In our proposed architecture, we define specific instructions for various submodules, including SHAKE256, SHAKE128, NTT, INTT, etc. Each instruction is associated with an opcode and operands. By customizing these instructions, we can tailor the engine's behavior to different security levels. | ||
| 78 | +The ZEROIZE bit in the control register clears all internal data-path registers that hold or have held secret-derived values. This prevents residual sensitive data from leaking through side-channel analysis or from being consumed by a subsequent operation. | ||
| 477 | 79 | ||
| 478 | -To execute the required instructions, a high-level controller acts as a sequencer, orchestrating a precise sequence of operations. Within the architecture, several memory blocks are accessible to submodules. However, it's the sequencer's responsibility to provide the necessary memory addresses for each operation. Additionally, the sequencer handles instruction fetching, decoding, operand retrieval, and overall data flow management. | ||
| 80 | +Firmware must issue zeroize: | ||
| 81 | +- After every completed operation, before starting the next command. | ||
| 82 | +- After any error or aborted operation, before re-issuing a command or reading results. | ||
| 479 | 83 | ||
| 480 | -The high-level architecture of Adams Bridge controller is illustrated as follows: | ||
| 84 | +Hardware behavior: | ||
| 85 | +- Zeroize takes the highest priority after reset. | ||
| 86 | +- The ZEROIZE control-register field is a pulse command: firmware writes a 1; the register auto-clears after one clock cycle. However, the hardware zeroize operation itself takes multiple cycles because on-chip SRAM is scrubbed one address per cycle. Firmware must poll the STATUS register and wait for ready before issuing the next command. | ||
| 87 | +- After zeroize completes, the STATUS register returns to ready, and the engine accepts a new command. | ||
| 481 | 88 | ||
| 482 | - | ||
| 89 | +# Area Results | ||
| 483 | 90 | ||
| 484 | -## Keccak architecture | ||
| 91 | +**TODO: Area numbers predate the architectural masking refactor. Re-synth required to refresh stdcell + RAM area.** | ||
| 92 | +- The required area for the protected Adams Bridge (ML-DSA-87 + ML-KEM-1024) is 0.1096mm2 @5nm: | ||
| 93 | + - 0.0860mm2 for stdcell | ||
| 94 | + - 0.0236mm2 for ram area. | ||
| 485 | 95 | ||
| 486 | -Hashing operation takes a significant portion of PQC latency. All samplers need to be fed by hashing functions. i.e., SHAKE128 and SHAKE256. Therefore, to improve the efficiency of the implementation, one should increase efficiency on the Keccak core, providing higher throughput using fewer hardware resources. Keccak core requires 24 rounds of the sponge function computation. We develop a dedicated SIPO (serial-in, parallel-out) and PISO (parallel-in, serial-out) for interfacing with this core in its input and output, respectively. | ||
| 96 | +For per-algorithm performance breakdowns, see the Performance and Area Results sections in [AdamsBridge\_MLDSA.md](AdamsBridge_MLDSA.md) and [AdamsBridge\_MLKEM.md](AdamsBridge_MLKEM.md). | ||
| 487 | 97 | ||
| 488 | -We propose an approach to design hardware rejection sampling architecture, which can offer more efficiency. This approach enables us to cascade the Keccak unit to rejection sampler and polynomial multiplication units that results in avoiding the memory access. | ||
| 489 | - | ||
| 490 | -In our optimized architecture, to reduce the failure probability due to the non-deterministic pattern of rejection sampling and avoid any stall cycle in polynomial multiplication, we use a FIFO to store sampled coefficients that match the speed of polynomial multiplication. The proposed sampler works in parallel with the Keccak core. Therefore, the latency for sampling unit is absorbed within the latency for a concurrently running Keccak core. | ||
| 491 | - | ||
| 492 | -In the input side, there are two different situations: | ||
| 493 | - | ||
| 494 | -1) The given block from SIPO is the last absorbing round. | ||
| 495 | - In this situation, the output PISO buffer should receive the Keccak state. | ||
| 496 | -2) The given block from SIPO is not the last absorbing round. | ||
| 497 | - In this situation, the output PISO buffer should not receive the Keccak state. However, the next input block from SIPO needs to be XORed with the Keccak state. | ||
| 498 | - | ||
| 499 | -There are two possible scenarios when the Keccak state has to be saved in the PISO buffer on the output side: | ||
| 500 | - | ||
| 501 | -1) PISO buffer EMPTY flag is not set. | ||
| 502 | - In this situation, Keccak should hold on and maintain the current state until EMPTY is activated and transfer the state into PISO buffer. | ||
| 503 | -2) PISO buffer EMPTY flag is set. | ||
| 504 | - In this situation, the state can be transferred to PISO buffer and the following round of Keccak (if any) can be started. | ||
| 505 | - | ||
| 506 | -### PISO Buffer | ||
| 507 | - | ||
| 508 | -The output of the Keccak unit is used to feed four different samplers at varying data rates. The Parallel in Serial out buffer is a generic buffer that can take the full width of the Keccak state and deliver it to the sampler units at the appropriate data rates. | ||
| 509 | - | ||
| 510 | -Input data from the Keccak can come at 1088 or 1344 bits per clock. During expand mask operation, the buffer needs to be written from a write pointer while valid data remains in the buffer. All other modes only require writing the full Keccak state into the buffer when it is empty. | ||
| 511 | - | ||
| 512 | -Output data rate varies \- 32 bits for RejBounded and SampleInBall, 80 bits for Expand Mask and 120 bits for SampleRejq. | ||
| 513 | - | ||
| 514 | -## Expand Mask architecture | ||
| 515 | - | ||
| 516 | -Dilithium samples the polynomials that make up the vectors and matrices independently, using a fixed seed value and a nonce value that increases the security as the input for Keccak. Keccak is used to take these seed and nonce and generate random stream bits. | ||
| 517 | - | ||
| 518 | -Expand Mask takes γ\-bits (20-bit for ML-DSA-87) and samples a vector such that all coefficients are in range of \[-γ\+1, γ\]. It continues to sample all required coefficients, n=256, for a polynomial. | ||
| 519 | - | ||
| 520 | -After sampling a polynomial with 256 coefficients, nonce will be changed and a new random stream will be generated using Keccak core and will be sampled by expand mask unit. | ||
| 521 | - | ||
| 522 | -The output of this operation results in a l different polynomial while each polynomial includes 256 coefficients. | ||
| 523 | - | ||
| 524 | -y1,0 y1,l-1 | ||
| 525 | - | ||
| 526 | -Expand Mask is used in signing operation of Dilithium. The output of expand mask sampler is stored into memory and will be used as an input for NTT module. | ||
| 527 | - | ||
| 528 | -We propose an architecture to remove the cost of memory access since NTT needs input in a specific format, i.e., 4 coefficients per each memory address. To achieve this, we need to have a balanced throughput between all these modules to avoid large buffering or conflict between them. | ||
| 529 | - | ||
| 530 | -High-level architecture is illustrated as follows: | ||
| 531 | - | ||
| 532 | - | ||
| 533 | - | ||
| 534 | -### Keccak interface to Expand Mask | ||
| 535 | - | ||
| 536 | -Keccak is used in SHAKE-256 configuration for expand mask operation. Hence, it will take the input data and generate 1088-bit output after each round. We propose implementing of Keccak while each round takes 12 cycles. The format of input data is as follows: | ||
| 537 | - | ||
| 538 | -Input data \= ρ' | n | ||
| 539 | - | ||
| 540 | -Where ρ' is seed with 512-bits, n=κ+r is the 16-bit nonce that will be incremented for each polynomial (r++) or if the signature is rejected by validity checks (\++). | ||
| 541 | - | ||
| 542 | -Since each bits (20-bit in for ML-DSA-87) is used for one coefficient, 256\*20=5120 bits are required for one polynomial which needs 5 rounds (5120/1088=4.7) of Keccak. | ||
| 543 | - | ||
| 544 | -To sample l polynomial (l=7 for ML-DSA-87), we need a total of 5\*7 \= 35 rounds of Keccak. | ||
| 545 | - | ||
| 546 | -There are two paths for Keccak input. While the input can be set by controller for new nonce in the case of next polynomial or rejected signature, the loop path is used to rerun Keccak for completing the current sampling process with l polynomial. | ||
| 547 | - | ||
| 548 | -Expand mask cannot take all 1088-bit output parallelly since it makes hardware architecture too costly and complex, and also there is no other input from Keccak for the next 12 cycles. Therefore, we propose a parallel-input serial-output (PISO) unit in between to store the Keccak output and feed rejection unit sequentially. | ||
| 549 | - | ||
| 550 | -### Expand Mask | ||
| 551 | - | ||
| 552 | -This unit takes data from the output of SHAKE-256 stored in a PISO buffer. The required cycles for this unit is 4.7 rounds of Keccak for one polynomial and 35 rounds of Keccak for all required polynomial (l polynomial which l=7 for ML-DSA-87). | ||
| 553 | - | ||
| 554 | -In our optimized architecture, this unit works in parallel with the Keccak core. Therefore, the latency for expand mask is absorbed within the latency for a concurrently running Keccak core. | ||
| 555 | - | ||
| 556 | -Our proposed NTT unit takes four coefficients per cycle from one memory address. It helps to avoid memory access challenges and make the control logic too complicated. This implies that the optimal speed of the expand mask module is to sample four coefficients per cycle. | ||
| 557 | - | ||
| 558 | -There are 4 rejection sampler circuits corresponding to each 20-bit input. The total coefficient after each round of Keccak is 1088/20 \= 54.4 coefficients. We keep expand mask unit working in all cycles and generating 4 coefficients per cycle without any interrupt. That means 12\*4=48 coefficients can be processed during each Keccak round. | ||
| 559 | - | ||
| 560 | - | ||
| 561 | - | ||
| 562 | -After 12 cycles, 48 coefficients are processed by the expand mask unit, and there are still 128-bit inside PISO. To maximize the utilization factor of our hardware resources, Keccak core will check the PISO status. If PISO contains 4 coefficients or more (the required inputs for expand mask unit), EMPTY flag will not be set, and Keccak will wait until the next cycle. Hence, expand mask unit takes 13 cycles to process 52 coefficients, and the last 48-bit will be combined with the next Keccak round to be processed. | ||
| 563 | - | ||
| 564 | - | ||
| 565 | - | ||
| 566 | -### Performance of Expand Mask | ||
| 567 | - | ||
| 568 | -Sampling a polynomial with 256 coefficients takes 256/4=64 cycles. The first round of Keccak needs 12 cycles, and the rest of Keccak operation will be parallel with expand mask operation. | ||
| 569 | - | ||
| 570 | -For a complete expand mask for Dilithium ML-DSA-87 with 7 polynomials, 7\*64+12=460 cycles are required using sequential operation. However, our design can be duplicated to enable parallel sampling for two different polynomials. Having two parallel design results in 268 cycles, while three parallel design results in 204 cycles at the cost of more resource utilization. | ||
| 571 | - | ||
| 572 | -## NTT architecture | ||
| 573 | - | ||
| 574 | -The most computationally intensive operation in lattice-based PQC schemes is polynomial multiplication which can be accelerated using NTT. However, NTT is still a performance bottleneck in lattice-based cryptography. We propose improved NTT architecture with highly efficient modular reduction. This architecture supports NTT, INTT, and point-wise multiplication (PWM) to enhance the design from resource sharing point-of-view while reducing the pre-processing cost of NTT and post-processing cost of INTT. | ||
| 575 | - | ||
| 576 | -Our NTT architecture exploits a merged-layer NTT technique using two pipelined stages with two parallel cores in each stage level, making 4 butterfly cores in total. Our proposed parallel pipelined butterfly cores enable us to perform Radix-4 NTT/INTT operation with 4 parallel coefficients. While memory bandwidth limits the efficiency of the butterfly operation, we use a specific memory pattern to store four coefficients per address. | ||
| 577 | - | ||
| 578 | -An NTT operation can be regarded as an iterative operation by applying a sequence of butterfly operations on the input polynomial coefficients. A butterfly operation is an arithmetic operation that combines two coefficients to obtain two outputs. By repeating this process for different pairs of coefficients, the NTT operation can be computed in a logarithmic number of steps. | ||
| 579 | - | ||
| 580 | -Cooley-Tukey (CT) and Gentleman-Sande (GS) butterfly configurations can be used to facilitate NTT/INTT computation. The bit-reverse function reverses the bits of the coefficient index. However, the bit-reverse permutation can be skipped by using CT butterfly for NTT and GS for INTT. | ||
| 581 | - | ||
| 582 | - | ||
| 583 | - | ||
| 584 | -We propose a merged NTT architecture using dual radix-4 design by employing four pipelined stages with two parallel cores at each stage level. | ||
| 585 | - | ||
| 586 | -The following presents the high-level architecture of our proposed NTT to take advantage of Merged architectural design: | ||
| 587 | - | ||
| 588 | - | ||
| 589 | - | ||
| 590 | -The following figure illustrates a 16-point NTT data flow based on our proposed architecture: | ||
| 591 | - | ||
| 592 | - | ||
| 593 | - | ||
| 594 | -A merged-layer NTT technique uses two pipelined stages with two parallel cores in each stage level, making 4 butterfly cores in total. The parallel pipelined butterfly cores enable us to perform Radix-4 NTT/INTT operation with 4 parallel coefficients. | ||
| 595 | - | ||
| 596 | -However, NTT requires a specific memory pattern that may limit the efficiency of the butterfly operation. For Dilithium use case, there are n=256 coefficients per polynomial that requires log n=8 layers of NTT operations. Each butterfly unit takes two coefficients while difference between the indexes is 28-i in ith stage. That means for the first stage, the given indexes for each butterfly unit are (k, k+128): | ||
| 597 | - | ||
| 598 | -Stage 1 input indexes: {(0, 128), {1, 129), (2, 130), …, (127, 255)} | ||
| 599 | - | ||
| 600 | -Stage 2 input indexes: {(0, 64), {1, 65), (2, 66), …, (63, 127), (128, 192), (129, 193), …, (191, 255)} | ||
| 601 | - | ||
| 602 | -… | ||
| 603 | - | ||
| 604 | -Stage 8 input indexes: {(0, 1), {2, 3), (4, 5), …, (254, 255)} | ||
| 605 | - | ||
| 606 | -There are several considerations for that: | ||
| 607 | - | ||
| 608 | -- We need access to 4 coefficients per cycle to match the throughput into 2×2 butterfly units. | ||
| 609 | -- An optimized architecture provides a memory with only one reading port, and one writing port. | ||
| 610 | -- Based on the previous two notes, each memory address contains 4 coefficients. | ||
| 611 | -- The initial coefficients are produced sequentially by Keccak and samplers. Specifically, they begin with 0 and continue incrementally up to 255\. Hence, at the very beginning cycle, the memory contains (0, 1, 2, 3\) in the first address, (4, 5, 6, 7\) in second address, and so on. | ||
| 612 | -- The cost of in-place memory relocation to align the memory content is not negligible. Particularly, it needs to be repeated for each stage. | ||
| 613 | - | ||
| 614 | -While memory bandwidth limits the efficiency of the butterfly operation, we use a specific memory pattern to store four coefficients per address. | ||
| 615 | - | ||
| 616 | -We propose a pipeline architecture the read memory in a particular pattern and using a set of buffers, the corresponding coefficients are fed into NTT block. | ||
| 617 | - | ||
| 618 | -The initial memory contains the indexes as follows: | ||
| 619 | - | ||
| 620 | -| Address | Initial Memory Content |||| | ||
| 621 | -| ------- | ---------------------- | --- | --- | --- | | ||
| 622 | -|||||| | ||
| 623 | -| 0 | 0 | 1 | 2 | 3 | | ||
| 624 | -| 1 | 4 | 5 | 6 | 7 | | ||
| 625 | -| 2 | 8 | 9 | 10 | 11 | | ||
| 626 | -| 3 | 12 | 13 | 14 | 15 | | ||
| 627 | -| 4 | 16 | 17 | 18 | 19 | | ||
| 628 | -| 5 | 20 | 21 | 22 | 23 | | ||
| 629 | -| 6 | 24 | 25 | 26 | 27 | | ||
| 630 | -| 7 | 28 | 29 | 30 | 31 | | ||
| 631 | -| 8 | 32 | 33 | 34 | 35 | | ||
| 632 | -| 9 | 36 | 37 | 38 | 39 | | ||
| 633 | -| 10 | 40 | 41 | 42 | 43 | | ||
| 634 | -| 11 | 44 | 45 | 46 | 47 | | ||
| 635 | -| 12 | 48 | 49 | 50 | 51 | | ||
| 636 | -| 13 | 52 | 53 | 54 | 55 | | ||
| 637 | -| 14 | 56 | 57 | 58 | 59 | | ||
| 638 | -| 15 | 60 | 61 | 62 | 63 | | ||
| 639 | -| 16 | 64 | 65 | 66 | 67 | | ||
| 640 | -| 17 | 68 | 69 | 70 | 71 | | ||
| 641 | -| 18 | 72 | 73 | 74 | 75 | | ||
| 642 | -| 19 | 76 | 77 | 78 | 79 | | ||
| 643 | -| 20 | 80 | 81 | 82 | 83 | | ||
| 644 | -| 21 | 84 | 85 | 86 | 87 | | ||
| 645 | -| 22 | 88 | 89 | 90 | 91 | | ||
| 646 | -| 23 | 92 | 93 | 94 | 95 | | ||
| 647 | -| 24 | 96 | 97 | 98 | 99 | | ||
| 648 | -| 25 | 100 | 101 | 102 | 103 | | ||
| 649 | -| 26 | 104 | 105 | 106 | 107 | | ||
| 650 | -| 27 | 108 | 109 | 110 | 111 | | ||
| 651 | -| 28 | 112 | 113 | 114 | 115 | | ||
| 652 | -| 29 | 116 | 117 | 118 | 119 | | ||
| 653 | -| 30 | 120 | 121 | 122 | 123 | | ||
| 654 | -| 31 | 124 | 125 | 126 | 127 | | ||
| 655 | -| 32 | 128 | 129 | 130 | 131 | | ||
| 656 | -| 33 | 132 | 133 | 134 | 135 | | ||
| 657 | -| 34 | 136 | 137 | 138 | 139 | | ||
| 658 | -| 35 | 140 | 141 | 142 | 143 | | ||
| 659 | -| 36 | 144 | 145 | 146 | 147 | | ||
| 660 | -| 37 | 148 | 149 | 150 | 151 | | ||
| 661 | -| 38 | 152 | 153 | 154 | 155 | | ||
| 662 | -| 39 | 156 | 157 | 158 | 159 | | ||
| 663 | -| 40 | 160 | 161 | 162 | 163 | | ||
| 664 | -| 41 | 164 | 165 | 166 | 167 | | ||
| 665 | -| 42 | 168 | 169 | 170 | 171 | | ||
| 666 | -| 43 | 172 | 173 | 174 | 175 | | ||
| 667 | -| 44 | 176 | 177 | 178 | 179 | | ||
| 668 | -| 45 | 180 | 181 | 182 | 183 | | ||
| 669 | -| 46 | 184 | 185 | 186 | 187 | | ||
| 670 | -| 47 | 188 | 189 | 190 | 191 | | ||
| 671 | -| 48 | 192 | 193 | 194 | 195 | | ||
| 672 | -| 49 | 196 | 197 | 198 | 199 | | ||
| 673 | -| 50 | 200 | 201 | 202 | 203 | | ||
| 674 | -| 51 | 204 | 205 | 206 | 207 | | ||
| 675 | -| 52 | 208 | 209 | 210 | 211 | | ||
| 676 | -| 53 | 212 | 213 | 214 | 215 | | ||
| 677 | -| 54 | 216 | 217 | 218 | 219 | | ||
| 678 | -| 55 | 220 | 221 | 222 | 223 | | ||
| 679 | -| 56 | 224 | 225 | 226 | 227 | | ||
| 680 | -| 57 | 228 | 229 | 230 | 231 | | ||
| 681 | -| 58 | 232 | 233 | 234 | 235 | | ||
| 682 | -| 59 | 236 | 237 | 238 | 239 | | ||
| 683 | -| 60 | 240 | 241 | 242 | 243 | | ||
| 684 | -| 61 | 244 | 245 | 246 | 247 | | ||
| 685 | -| 62 | 248 | 249 | 250 | 251 | | ||
| 686 | -| 63 | 252 | 253 | 254 | 255 | | ||
| 687 | - | ||
| 688 | - | ||
| 689 | -Suppose memory is read in this pattern: | ||
| 690 | - | ||
| 691 | -Addr: 0, 16, 32, 48, 1, 17, 33, 49, …, 15, 31, 47, 63 | ||
| 692 | - | ||
| 693 | -The input goes to the customized buffer architecture as follows: | ||
| 694 | - | ||
| 695 | -| 0 | → |||||||| | ||
| 696 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 697 | -| 1 ||||||||| | ||
| 698 | -| 2 ||||||||| | ||
| 699 | -| 3 ||||||||| | ||
| 700 | - | ||
| 701 | - | ||
| 702 | -Cycle 0 reading address 0 | ||
| 703 | - | ||
| 704 | -| 64 | → |||| 0 |||| | ||
| 705 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 706 | -| 65 |||| 1 ||||| | ||
| 707 | -| 66 ||| 2 |||||| | ||
| 708 | -| 67 || 3 ||||||| | ||
| 709 | - | ||
| 710 | - | ||
| 711 | -Cycle 1 reading address 16 | ||
| 712 | - | ||
| 713 | -| 128 | → |||| 64 | 0 ||| | ||
| 714 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 715 | -| 129 |||| 65 | 1 |||| | ||
| 716 | -| 130 ||| 66 | 2 ||||| | ||
| 717 | -| 131 || 67 | 3 |||||| | ||
| 718 | - | ||
| 719 | - | ||
| 720 | -Cycle 2 reading address 32 | ||
| 721 | - | ||
| 722 | -| 192 | → |||| 128 | 64 | 0 || | ||
| 723 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 724 | -| 193 |||| 129 | 65 | 1 ||| | ||
| 725 | -| 194 ||| 130 | 66 | 2 |||| | ||
| 726 | -| 195 || 131 | 67 | 3 ||||| | ||
| 727 | - | ||
| 728 | - | ||
| 729 | -Cycle 3 reading address 48 | ||
| 730 | - | ||
| 731 | -| 4 | → |||| 192 | 128 | 64 | 0 | | ||
| 732 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 733 | -| 5 |||| 193 | 129 | 65 | 1 || | ||
| 734 | -| 6 ||| 194 | 130 | 66 | 2 ||| | ||
| 735 | -| 7 || 195 | 131 | 67 | 3 |||| | ||
| 736 | - | ||
| 737 | - | ||
| 738 | -Cycle 4 reading address 1 | ||
| 739 | - | ||
| 740 | -| 68 | → |||| 4 | 192 | 128 | 64 | | ||
| 741 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 742 | -| 69 |||| 5 | 193 | 129 | 65 | 1 | | ||
| 743 | -| 70 ||| 6 | 194 | 130 | 66 | 2 || | ||
| 744 | -| 71 || 7 | 195 | 131 | 67 | 3 ||| | ||
| 745 | - | ||
| 746 | - | ||
| 747 | -Cycle 5 reading address 17 | ||
| 748 | - | ||
| 749 | -The highlighted value in the first buffer contains the required coefficients for our butterfly units, i.e., (0, 128\) and (64, 192). Since we merged the 1 and second layers of NTT stages, the output of the first parallel butterfly units need to exchange one coefficient and then the required input for the second parallel set of butterfly units is ready, i.e., (0, 64\) and (128, 192). | ||
| 750 | - | ||
| 751 | -After completing the first round of operation including NTT stage 1 and 2, the memory contains the following data: | ||
| 752 | - | ||
| 753 | -| Address | Memory Content after 1&2 stages |||| | ||
| 754 | -| ------- | ------------------------------- | --- | --- | --- | | ||
| 755 | -|||||| | ||
| 756 | -| 0 | 0 | 64 | 128 | 192 | | ||
| 757 | -| 1 | 1 | 65 | 129 | 193 | | ||
| 758 | -| 2 | 2 | 66 | 130 | 194 | | ||
| 759 | -| 3 | 3 | 67 | 131 | 195 | | ||
| 760 | -| 4 | 4 | 68 | 132 | 196 | | ||
| 761 | -| 5 | 5 | 69 | 133 | 197 | | ||
| 762 | -| 6 | 6 | 70 | 134 | 198 | | ||
| 763 | -| 7 | 7 | 71 | 135 | 199 | | ||
| 764 | -| 8 | 8 | 72 | 136 | 200 | | ||
| 765 | -| 9 | 9 | 73 | 137 | 201 | | ||
| 766 | -| 10 | 10 | 74 | 138 | 202 | | ||
| 767 | -| 11 | 11 | 75 | 139 | 203 | | ||
| 768 | -| 12 | 12 | 76 | 140 | 204 | | ||
| 769 | -| 13 | 13 | 77 | 141 | 205 | | ||
| 770 | -| 14 | 14 | 78 | 142 | 206 | | ||
| 771 | -| 15 | 15 | 79 | 143 | 207 | | ||
| 772 | -| 16 | 16 | 80 | 144 | 208 | | ||
| 773 | -| 17 | 17 | 81 | 145 | 209 | | ||
| 774 | -| 18 | 18 | 82 | 146 | 210 | | ||
| 775 | -| 19 | 19 | 83 | 147 | 211 | | ||
| 776 | -| 20 | 20 | 84 | 148 | 212 | | ||
| 777 | -| 21 | 21 | 85 | 149 | 213 | | ||
| 778 | -| 22 | 22 | 86 | 150 | 214 | | ||
| 779 | -| 23 | 23 | 87 | 151 | 215 | | ||
| 780 | -| 24 | 24 | 88 | 152 | 216 | | ||
| 781 | -| 25 | 25 | 89 | 153 | 217 | | ||
| 782 | -| 26 | 26 | 90 | 154 | 218 | | ||
| 783 | -| 27 | 27 | 91 | 155 | 219 | | ||
| 784 | -| 28 | 28 | 92 | 156 | 220 | | ||
| 785 | -| 29 | 29 | 93 | 157 | 221 | | ||
| 786 | -| 30 | 30 | 94 | 158 | 222 | | ||
| 787 | -| 31 | 31 | 95 | 159 | 223 | | ||
| 788 | -| 32 | 32 | 96 | 160 | 224 | | ||
| 789 | -| 33 | 33 | 97 | 161 | 225 | | ||
| 790 | -| 34 | 34 | 98 | 162 | 226 | | ||
| 791 | -| 35 | 35 | 99 | 163 | 227 | | ||
| 792 | -| 36 | 36 | 100 | 164 | 228 | | ||
| 793 | -| 37 | 37 | 101 | 165 | 229 | | ||
| 794 | -| 38 | 38 | 102 | 166 | 230 | | ||
| 795 | -| 39 | 39 | 103 | 167 | 231 | | ||
| 796 | -| 40 | 40 | 104 | 168 | 232 | | ||
| 797 | -| 41 | 41 | 105 | 169 | 233 | | ||
| 798 | -| 42 | 42 | 106 | 170 | 234 | | ||
| 799 | -| 43 | 43 | 107 | 171 | 235 | | ||
| 800 | -| 44 | 44 | 108 | 172 | 236 | | ||
| 801 | -| 45 | 45 | 109 | 173 | 237 | | ||
| 802 | -| 46 | 46 | 110 | 174 | 238 | | ||
| 803 | -| 47 | 47 | 111 | 175 | 239 | | ||
| 804 | -| 48 | 48 | 112 | 176 | 240 | | ||
| 805 | -| 49 | 49 | 113 | 177 | 241 | | ||
| 806 | -| 50 | 50 | 114 | 178 | 242 | | ||
| 807 | -| 51 | 51 | 115 | 179 | 243 | | ||
| 808 | -| 52 | 52 | 116 | 180 | 244 | | ||
| 809 | -| 53 | 53 | 117 | 181 | 245 | | ||
| 810 | -| 54 | 54 | 118 | 182 | 246 | | ||
| 811 | -| 55 | 55 | 119 | 183 | 247 | | ||
| 812 | -| 56 | 56 | 120 | 184 | 248 | | ||
| 813 | -| 57 | 57 | 121 | 185 | 249 | | ||
| 814 | -| 58 | 58 | 122 | 186 | 250 | | ||
| 815 | -| 59 | 59 | 123 | 187 | 251 | | ||
| 816 | -| 60 | 60 | 124 | 188 | 252 | | ||
| 817 | -| 61 | 61 | 125 | 189 | 253 | | ||
| 818 | -| 62 | 62 | 126 | 190 | 254 | | ||
| 819 | -| 63 | 63 | 127 | 191 | 255 | | ||
| 820 | - | ||
| 821 | - | ||
| 822 | -The same process can be applied in the next round to perform NTT stage 3 and 4\. | ||
| 823 | - | ||
| 824 | -| 0 | → |||||||| | ||
| 825 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 826 | -| 64 ||||||||| | ||
| 827 | -| 128 ||||||||| | ||
| 828 | -| 192 ||||||||| | ||
| 829 | - | ||
| 830 | - | ||
| 831 | -Cycle 0 reading address 0 | ||
| 832 | - | ||
| 833 | -| 16 | → |||| 0 |||| | ||
| 834 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 835 | -| 80 |||| 64 ||||| | ||
| 836 | -| 144 ||| 128 |||||| | ||
| 837 | -| 208 || 192 ||||||| | ||
| 838 | - | ||
| 839 | - | ||
| 840 | -Cycle 1 reading address 16 | ||
| 841 | - | ||
| 842 | -| 32 | → |||| 16 | 0 ||| | ||
| 843 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 844 | -| 96 |||| 80 | 64 |||| | ||
| 845 | -| 160 ||| 144 | 128 ||||| | ||
| 846 | -| 224 || 208 | 192 |||||| | ||
| 847 | - | ||
| 848 | - | ||
| 849 | -Cycle 2 reading address 32 | ||
| 850 | - | ||
| 851 | -| 48 | → |||| 32 | 16 | 0 || | ||
| 852 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 853 | -| 112 |||| 96 | 80 | 64 ||| | ||
| 854 | -| 176 ||| 160 | 144 | 128 |||| | ||
| 855 | -| 240 || 224 | 208 | 192 ||||| | ||
| 856 | - | ||
| 857 | - | ||
| 858 | -Cycle 3 reading address 48 | ||
| 859 | - | ||
| 860 | -| 1 | → |||| 48 | 32 | 16 | 0 | | ||
| 861 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 862 | -| 65 |||| 112 | 96 | 80 | 64 || | ||
| 863 | -| 129 ||| 176 | 160 | 144 | 128 ||| | ||
| 864 | -| 193 || 240 | 224 | 208 | 192 |||| | ||
| 865 | - | ||
| 866 | - | ||
| 867 | -Cycle 4 reading address 1 | ||
| 868 | - | ||
| 869 | -| 17 | → |||| 1 | 48 | 32 | 16 | | ||
| 870 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 871 | -| 81 |||| 65 | 112 | 96 | 80 | 64 | | ||
| 872 | -| 145 ||| 129 | 176 | 160 | 144 | 128 || | ||
| 873 | -| 209 || 193 | 240 | 224 | 208 | 192 ||| | ||
| 874 | - | ||
| 875 | - | ||
| 876 | -Cycle 5 reading address 17 | ||
| 877 | - | ||
| 878 | -After completing all stages, the memory contents would be as follows: | ||
| 879 | - | ||
| 880 | -| Address | Memory Content after Stage 7&8 |||| | ||
| 881 | -| ------- | ------------------------------ | --- | --- | --- | | ||
| 882 | -|||||| | ||
| 883 | -| 0 | 0 | 1 | 2 | 3 | | ||
| 884 | -| 1 | 4 | 5 | 6 | 7 | | ||
| 885 | -| 2 | 8 | 9 | 10 | 11 | | ||
| 886 | -| 3 | 12 | 13 | 14 | 15 | | ||
| 887 | -| 4 | 16 | 17 | 18 | 19 | | ||
| 888 | -| 5 | 20 | 21 | 22 | 23 | | ||
| 889 | -| 6 | 24 | 25 | 26 | 27 | | ||
| 890 | -| 7 | 28 | 29 | 30 | 31 | | ||
| 891 | -| 8 | 32 | 33 | 34 | 35 | | ||
| 892 | -| 9 | 36 | 37 | 38 | 39 | | ||
| 893 | -| 10 | 40 | 41 | 42 | 43 | | ||
| 894 | -| 11 | 44 | 45 | 46 | 47 | | ||
| 895 | -| 12 | 48 | 49 | 50 | 51 | | ||
| 896 | -| 13 | 52 | 53 | 54 | 55 | | ||
| 897 | -| 14 | 56 | 57 | 58 | 59 | | ||
| 898 | -| 15 | 60 | 61 | 62 | 63 | | ||
| 899 | -| 16 | 64 | 65 | 66 | 67 | | ||
| 900 | -| 17 | 68 | 69 | 70 | 71 | | ||
| 901 | -| 18 | 72 | 73 | 74 | 75 | | ||
| 902 | -| 19 | 76 | 77 | 78 | 79 | | ||
| 903 | -| 20 | 80 | 81 | 82 | 83 | | ||
| 904 | -| 21 | 84 | 85 | 86 | 87 | | ||
| 905 | -| 22 | 88 | 89 | 90 | 91 | | ||
| 906 | -| 23 | 92 | 93 | 94 | 95 | | ||
| 907 | -| 24 | 96 | 97 | 98 | 99 | | ||
| 908 | -| 25 | 100 | 101 | 102 | 103 | | ||
| 909 | -| 26 | 104 | 105 | 106 | 107 | | ||
| 910 | -| 27 | 108 | 109 | 110 | 111 | | ||
| 911 | -| 28 | 112 | 113 | 114 | 115 | | ||
| 912 | -| 29 | 116 | 117 | 118 | 119 | | ||
| 913 | -| 30 | 120 | 121 | 122 | 123 | | ||
| 914 | -| 31 | 124 | 125 | 126 | 127 | | ||
| 915 | -| 32 | 128 | 129 | 130 | 131 | | ||
| 916 | -| 33 | 132 | 133 | 134 | 135 | | ||
| 917 | -| 34 | 136 | 137 | 138 | 139 | | ||
| 918 | -| 35 | 140 | 141 | 142 | 143 | | ||
| 919 | -| 36 | 144 | 145 | 146 | 147 | | ||
| 920 | -| 37 | 148 | 149 | 150 | 151 | | ||
| 921 | -| 38 | 152 | 153 | 154 | 155 | | ||
| 922 | -| 39 | 156 | 157 | 158 | 159 | | ||
| 923 | -| 40 | 160 | 161 | 162 | 163 | | ||
| 924 | -| 41 | 164 | 165 | 166 | 167 | | ||
| 925 | -| 42 | 168 | 169 | 170 | 171 | | ||
| 926 | -| 43 | 172 | 173 | 174 | 175 | | ||
| 927 | -| 44 | 176 | 177 | 178 | 179 | | ||
| 928 | -| 45 | 180 | 181 | 182 | 183 | | ||
| 929 | -| 46 | 184 | 185 | 186 | 187 | | ||
| 930 | -| 47 | 188 | 189 | 190 | 191 | | ||
| 931 | -| 48 | 192 | 193 | 194 | 195 | | ||
| 932 | -| 49 | 196 | 197 | 198 | 199 | | ||
| 933 | -| 50 | 200 | 201 | 202 | 203 | | ||
| 934 | -| 51 | 204 | 205 | 206 | 207 | | ||
| 935 | -| 52 | 208 | 209 | 210 | 211 | | ||
| 936 | -| 53 | 212 | 213 | 214 | 215 | | ||
| 937 | -| 54 | 216 | 217 | 218 | 219 | | ||
| 938 | -| 55 | 220 | 221 | 222 | 223 | | ||
| 939 | -| 56 | 224 | 225 | 226 | 227 | | ||
| 940 | -| 57 | 228 | 229 | 230 | 231 | | ||
| 941 | -| 58 | 232 | 233 | 234 | 235 | | ||
| 942 | -| 59 | 236 | 237 | 238 | 239 | | ||
| 943 | -| 60 | 240 | 241 | 242 | 243 | | ||
| 944 | -| 61 | 244 | 245 | 246 | 247 | | ||
| 945 | -| 62 | 248 | 249 | 250 | 251 | | ||
| 946 | -| 63 | 252 | 253 | 254 | 255 | | ||
| 947 | - | ||
| 948 | - | ||
| 949 | -The proposed method saves the time needed for shuffling and reordering, while using only a little more memory. | ||
| 950 | - | ||
| 951 | -With this memory access pattern, writes to the memory are in order (0, 1, 2, 3, etc) while reads wraparound with a step of 16 (0, 16, 32 48, 1, 17, 33, 49, etc). Hence, there will be a memory conflict where writes to addresses take place before the data is read and provided to the butterfly 2x2 module. To resolve this, a set of 3 base addresses are given to the NTT module – src address, interim address and dest address that belong to 3 separate sections in memory. The NTT module will access the memory with the appropriate base address for each round as follows: | ||
| 952 | - | ||
| 953 | -| Round | Read base address | Write base address | | ||
| 954 | -| :---- | :---------------- | :----------------- | | ||
| 955 | -| 0 | src | interim | | ||
| 956 | -| 1 | interim | dest | | ||
| 957 | -| 2 | dest | interim | | ||
| 958 | -| 3 | interim | dest | | ||
| 959 | - | ||
| 960 | - | ||
| 961 | -At the end of NTT operation, results must be located in the section with the dest base address. This will also provide the benefit of preserving the original input for later use in keygen or signing operations. The same memory access pattern is followed for INTT operation as well. Note that Adam’s bridge controller may choose to make src and dest base addresses the same to save on memory usage, when original coefficients need not be preserved. In this case, the requirement is still to have a separate interim base address to avoid memory conflicts during NTT operation. | ||
| 962 | - | ||
| 963 | -#### Modular Reduction in NTT | ||
| 964 | - | ||
| 965 | -The modular addition/subtraction in hardware platform can be implemented by one additional subtraction/addition operations, as follows: | ||
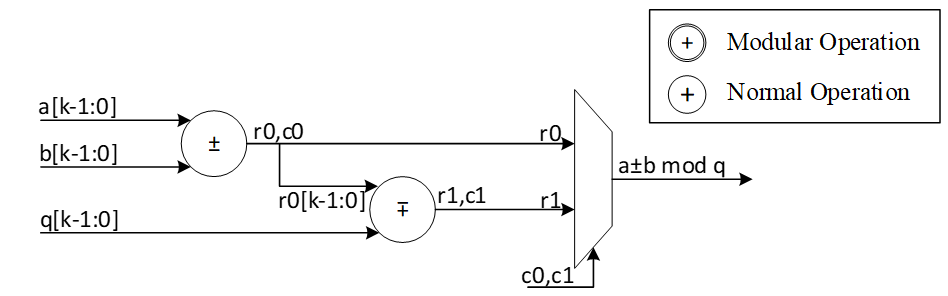
| 966 | - | ||
| 967 | - | ||
| 968 | - | ||
| 969 | -However, modular multiplication can be implemented using different techniques. The commonly used Barrett reduction and Montgomery reduction require additional multiplications and are more suitable for the non-specific modulus. Furthermore, Montgomery reduction needs two more steps to convert all inputs from normal domain to Montgomery domain and then convert back the results into normal domain. This conversation increases the latency of NTT operations and does not lead to the best performance. Hence, Barrett reduction and Montgomery reduction are expensive in time and hardware resources. | ||
| 970 | - | ||
| 971 | - | ||
| 972 | - | ||
| 973 | -For Dilithium hardware accelerator, we can customize the reduction architecture based on the prime value of the scheme with q= 8,380,417 to design a hardware-friendly architecture that increase the efficiency of computation. The value of q can be presented by: | ||
| 974 | - | ||
| 975 | -q=8,380,417=223-213+1 | ||
| 976 | - | ||
| 977 | -For the modular operation we have: | ||
| 978 | - | ||
| 979 | -223=213-1 mod q | ||
| 980 | - | ||
| 981 | -Suppose that all input operands are less than q, we have: | ||
| 982 | - | ||
| 983 | -0≤a,b\<q | ||
| 984 | - | ||
| 985 | -z=a.b\<q2=46'h3FE0\_04FF\_C001 | ||
| 986 | - | ||
| 987 | -Based on 223=213-1 mod q, we can rewrite the equation as follows: | ||
| 988 | - | ||
| 989 | -z=223z45:23+z22:0=213z45:23-z45:23+z22:0=223z45:33+213z32:23-z45:23+z22:0=213z45:33-z45:33+213z32:23-z45:23+z22:0=223z45:43+213z42:33-z45:33+213z32:23-z45:23+z22:0=213z45:43-z45:43+213z42:33-z45:33+213z32:23-z45:23+z22:0=213z45:43+z42:33+z32:23+-z45:43-z45:33-z45:23+z22:0=213z45:43+z42:33+z32:23+z22:13+-z45:43-z45:33-z45:23+z12:0=213c-(z45:43+z45:33+z45:23)+z\[12:0\] | ||
| 990 | - | ||
| 991 | -Where: | ||
| 992 | - | ||
| 993 | -c=z45:43+z42:33+z32:23+z\[22:13\]\<212 | ||
| 994 | - | ||
| 995 | -The value of c has 12 bits, and we can rewrite it as follows: | ||
| 996 | - | ||
| 997 | -213c11:0=223c11:10+213c9:0=213c11:10-c11:10+213c9:0=213d-c11:10 | ||
| 998 | - | ||
| 999 | -d=c11:10+c9:0 | ||
| 1000 | - | ||
| 1001 | -So, the value of z mod q is as follows: | ||
| 1002 | - | ||
| 1003 | -z=213c-z45:43+z45:33+z45:23+z12:0=213d+z12:0-z45:43+z45:33+z45:23+c11:10=213d+z12:0-e | ||
| 1004 | - | ||
| 1005 | -Where: | ||
| 1006 | - | ||
| 1007 | -e=z45:43+z45:33+z45:23+c11:10=f+z45:23 mod q | ||
| 1008 | - | ||
| 1009 | -f\[14:0\]=z45:43+z45:33+c11:10 | ||
| 1010 | - | ||
| 1011 | -We use a modular addition for f+z45:23 to keep it less than q. This modular addition has one stage delay. | ||
| 1012 | - | ||
| 1013 | -The addition between 213d and z12:0 can be implemented by concatenating since the first 13 bits of d are zero as follows: | ||
| 1014 | - | ||
| 1015 | -g23:0=213d+z12:0=d10:0||z\[12:0\] | ||
| 1016 | - | ||
| 1017 | -Since the result has more than 23 bits, we perform a modular addition to keep it less than q. For that, the regular modular addition will be replaced by the following architecture while c0=g23, r0=g\[22:0\]. In other words, c0=d10, r0\[22:0\]=d9:0||z\[12:0\] | ||
| 1018 | - | ||
| 1019 | - | ||
| 1020 | - | ||
| 1021 | -The following figure shows the architecture of this reduction technique. As one can see, these functions do not need any multiplications in hardware and can be achieved by shifter and adder. | ||
| 1022 | - | ||
| 1023 | - | ||
| 1024 | - | ||
| 1025 | -The modular multiplication is implemented with a 3-stage pipeline architecture. At the first pipeline stage, z=a·b is calculated. At the second pipeline stage, f+z\[45:23\] and 213d+z12:0 are calculated in parallel. At the third pipeline stage, a modular subtraction is executed to obtain the result and the result is output. | ||
| 1026 | - | ||
| 1027 | -We do not need extra multiplications for our modular reduction, unlike Barrett and Montgomery algorithms. The operations of our reduction do not depend on the input data and do not leak any information. Our reduction using the modulus q= 8,380,417 is fast, efficient and constant-time. | ||
| 1028 | - | ||
| 1029 | -### Performance of NTT | ||
| 1030 | - | ||
| 1031 | -For a complete NTT operation with 8 layers, i.e., n \= 256, the proposed architecture takes 82=4 rounds. Each round involves 2564=64 operations in pipelined architecture. Hence, the latency of each round is equal to 64 (read from memory) \+ 8 (2 sequential butterfly latency) \+ 4 (input buffer latency) \+ 2 (wait between each two stages) \= 78 cycles. | ||
| 1032 | - | ||
| 1033 | -Round 0: stage 0 & 1 | ||
| 1034 | - | ||
| 1035 | -Round 1: stage 2 & 3 | ||
| 1036 | - | ||
| 1037 | -Round 2: stage 4 & 5 | ||
| 1038 | - | ||
| 1039 | -Round 3: stage 6 & 7 | ||
| 1040 | - | ||
| 1041 | -The total latency would be 4×78=312 cycles. | ||
| 1042 | - | ||
| 1043 | -For a complete NTT/INTT operation for Dilithium ML-DSA-87 with 7 or 8 polynomials, 7\*312=2184 or 8\*312=2496 cycles are required. However, our design can be duplicated to enable parallel NTT for two different polynomials. Having two parallel design results in 1248 cycles. | ||
| 1044 | - | ||
| 1045 | -### NTT shuffling countermeasure | ||
| 1046 | - | ||
| 1047 | -To protect NTT, we have two options – shuffling the order of execution of coefficients and masking in-order computation such that NTT performs operation on two input shares per coefficient and produces two output shares. While masking is a strong countermeasure for side-channel attacks, it requires at least 4x the area and adds 4x the latency to one NTT operation. Shuffling is an implementation trick that can be used to provide randomization to some degree without area or latency overhead. In Adam’s Bridge, we employ a combination of both for protected design. One NTT core will have shuffling for both NTT and INTT modes. The second NTT core will have shuffling and masking on the first layer of computation for INTT mode with cascaded connection from a masked PWM module. In NTT mode, the second NTT core will employ only shuffling. PWM operations are masked by default. PWA and PWS operations are shuffled by default. | ||
| 1048 | - | ||
| 1049 | -| Address || Memory Content |||| | ||
| 1050 | -| ------- | --- | -------------- | --- | --- | --- | | ||
| 1051 | -||||||| | ||
| 1052 | -| 0 || 0 | 1 | 2 | 3 | | ||
| 1053 | -| 1 || 4 | 5 | 6 | 7 | | ||
| 1054 | -| 2 || 8 | 9 | 10 | 11 | | ||
| 1055 | -| 3 || 12 | 13 | 14 | 15 | | ||
| 1056 | -| 4 || 16 | 17 | 18 | 19 | | ||
| 1057 | -| 5 || 20 | 21 | 22 | 23 | | ||
| 1058 | -| 6 || 24 | 25 | 26 | 27 | | ||
| 1059 | -| 7 || 28 | 29 | 30 | 31 | | ||
| 1060 | -| 8 || 32 | 33 | 34 | 35 | | ||
| 1061 | -| 9 || 36 | 37 | 38 | 39 | | ||
| 1062 | -| 10 || 40 | 41 | 42 | 43 | | ||
| 1063 | -| 11 || 44 | 45 | 46 | 47 | | ||
| 1064 | -| 12 || 48 | 49 | 50 | 51 | | ||
| 1065 | -| 13 || 52 | 53 | 54 | 55 | | ||
| 1066 | -| 14 || 56 | 57 | 58 | 59 | | ||
| 1067 | -| 15 || 60 | 61 | 62 | 63 | | ||
| 1068 | -| 16 || 64 | 65 | 66 | 67 | | ||
| 1069 | -| 17 || 68 | 69 | 70 | 71 | | ||
| 1070 | -| 18 || 72 | 73 | 74 | 75 | | ||
| 1071 | -| 19 || 76 | 77 | 78 | 79 | | ||
| 1072 | -| 20 || 80 | 81 | 82 | 83 | | ||
| 1073 | -| 21 || 84 | 85 | 86 | 87 | | ||
| 1074 | -| 22 || 88 | 89 | 90 | 91 | | ||
| 1075 | -| 23 || 92 | 93 | 94 | 95 | | ||
| 1076 | -| 24 || 96 | 97 | 98 | 99 | | ||
| 1077 | -| 25 || 100 | 101 | 102 | 103 | | ||
| 1078 | -| 26 || 104 | 105 | 106 | 107 | | ||
| 1079 | -| 27 || 108 | 109 | 110 | 111 | | ||
| 1080 | -| 28 || 112 | 113 | 114 | 115 | | ||
| 1081 | -| 29 || 116 | 117 | 118 | 119 | | ||
| 1082 | -| 30 || 120 | 121 | 122 | 123 | | ||
| 1083 | -| 31 || 124 | 125 | 126 | 127 | | ||
| 1084 | -| 32 || 128 | 129 | 130 | 131 | | ||
| 1085 | -| 33 || 132 | 133 | 134 | 135 | | ||
| 1086 | -| 34 || 136 | 137 | 138 | 139 | | ||
| 1087 | -| 35 || 140 | 141 | 142 | 143 | | ||
| 1088 | -| 36 || 144 | 145 | 146 | 147 | | ||
| 1089 | -| 37 || 148 | 149 | 150 | 151 | | ||
| 1090 | -| 38 || 152 | 153 | 154 | 155 | | ||
| 1091 | -| 39 || 156 | 157 | 158 | 159 | | ||
| 1092 | -| 40 || 160 | 161 | 162 | 163 | | ||
| 1093 | -| 41 || 164 | 165 | 166 | 167 | | ||
| 1094 | -| 42 || 168 | 169 | 170 | 171 | | ||
| 1095 | -| 43 || 172 | 173 | 174 | 175 | | ||
| 1096 | -| 44 || 176 | 177 | 178 | 179 | | ||
| 1097 | -| 45 || 180 | 181 | 182 | 183 | | ||
| 1098 | -| 46 || 184 | 185 | 186 | 187 | | ||
| 1099 | -| 47 || 188 | 189 | 190 | 191 | | ||
| 1100 | -| 48 || 192 | 193 | 194 | 195 | | ||
| 1101 | -| 49 || 196 | 197 | 198 | 199 | | ||
| 1102 | -| 50 || 200 | 201 | 202 | 203 | | ||
| 1103 | -| 51 || 204 | 205 | 206 | 207 | | ||
| 1104 | -| 52 || 208 | 209 | 210 | 211 | | ||
| 1105 | -| 53 || 212 | 213 | 214 | 215 | | ||
| 1106 | -| 54 || 216 | 217 | 218 | 219 | | ||
| 1107 | -| 55 || 220 | 221 | 222 | 223 | | ||
| 1108 | -| 56 || 224 | 225 | 226 | 227 | | ||
| 1109 | -| 57 || 228 | 229 | 230 | 231 | | ||
| 1110 | -| 58 || 232 | 233 | 234 | 235 | | ||
| 1111 | -| 59 || 236 | 237 | 238 | 239 | | ||
| 1112 | -| 60 || 240 | 241 | 242 | 243 | | ||
| 1113 | -| 61 || 244 | 245 | 246 | 247 | | ||
| 1114 | -| 62 || 248 | 249 | 250 | 251 | | ||
| 1115 | -| 63 || 252 | 253 | 254 | 255 | | ||
| 1116 | - | ||
| 1117 | - | ||
| 1118 | -To implement shuffling in NTT, the memory content is divided into 16 chunks. The highlighted section in the memory table above shows the 16 chunk start addresses. For example, the first chunk consists of addresses 0, 16, 32, 48\. Second chunk has 1, 17, 33, 49, and so on. In NTT mode, memory read pattern is 0, 16, 32, 48, 1, 17, 33, 49, etc. The buffer in NTT module is updated to have two sections and is addressable to support INTT shuffling with matched search space as that of NTT mode. | ||
| 1119 | - | ||
| 1120 | -During shuffling, two levels of randomization are done: | ||
| 1121 | - | ||
| 1122 | -1. Chunk order is randomized | ||
| 1123 | -2. Start address within the selected chunk is also randomized. | ||
| 1124 | - | ||
| 1125 | -With this technique, the search space is 16 ×416=236. For example, if chunk 5 is selected as the starting chunk, the input buffer in NTT mode is configured as below. | ||
| 1126 | - | ||
| 1127 | -||||| | ||
| 1128 | -| :--- | :--- | :--- | :--- | | ||
| 1129 | -||||| | ||
| 1130 | -||||| | ||
| 1131 | -||||| | ||
| 1132 | -| 2151 | 2140 | 2133 | 2122 | | ||
| 1133 | -| 1511 | 1500 | 1493 | 1482 | | ||
| 1134 | -| 871 | 860 | 853 | 842 | | ||
| 1135 | -| 231 | 220 | 213 | 202 | | ||
| 1136 | - | ||
| 1137 | - | ||
| 1138 | -Then, the order of execution is randomized for NTT as a second level of randomization. For example, order of execution in NTT mode can be (22, 86, 150, 214), (23, 87, 151, 215), (20, 84, 148, 212), (21, 85, 149, 213). Note that, once a random start address is selected, the addresses increment from that point and wrap around until all 4 sets of coefficients have been processed in order. Similarly, once a random chunk is selected, rest of the chunks are processed in order and wrapped around until all chunks are covered. In this example, chunk processing order is 5, 6, 7, 8, …, 15, 0, 1, 2, 3, 4\. | ||
| 1139 | - | ||
| 1140 | -For the next chunk, buffer pointer switches to the top half. While the bottom half of the buffer is read and executed, each location of the top half is filled in the same cycle avoiding latency overhead. When all 4 entries of the lower buffer are processed, upper buffer is ready to be fed into BF units. | ||
| 1141 | - | ||
| 1142 | -| 2193 | 2183 | 2173 | 2163 | | ||
| 1143 | -| :--- | :--- | :--- | :--- | | ||
| 1144 | -| 1552 | 1542 | 1532 | 1522 | | ||
| 1145 | -| 911 | 901 | 891 | 881 | | ||
| 1146 | -| 270 | 260 | 250 | 240 | | ||
| 1147 | -| 2151 | 2140 | 2133 | 2122 | | ||
| 1148 | -| 1511 | 1500 | 1493 | 1482 | | ||
| 1149 | -| 871 | 860 | 853 | 842 | | ||
| 1150 | -| 231 | 220 | 213 | 202 | | ||
| 1151 | - | ||
| 1152 | - | ||
| 1153 | - | ||
| 1154 | - | ||
| 1155 | -Above figure shows the flow of a shuffled NTT/INTT operation. The shuffler part of the controller is responsible for calculating the correct memory addresses and feed the correct inputs to the BFs. | ||
| 1156 | - | ||
| 1157 | -When shuffling in NTT mode, the memory read and write addresses are computed as shown below.for i in range (0, 4): | ||
| 1158 | - | ||
| 1159 | - Read address \= chunk \+ (i \* RD\_STEP) | ||
| 1160 | - | ||
| 1161 | -Write address \= chunk \* 4 \+ (rand\_index \* WR\_STEP) | ||
| 1162 | - | ||
| 1163 | -Where rand\_index is the randomized start index of execution order for an NTT operation | ||
| 1164 | - | ||
| 1165 | -E.g. if selected chunk is 5, and rand\_index is 2 | ||
| 1166 | - | ||
| 1167 | - Order of execution is 2, 3, 0, 1 | ||
| 1168 | - | ||
| 1169 | - Read address \= 5 \+ (0\*16), 5 \+ (1\*16), 5+(2\*16), 5+(3\*16) \= 5, 21, 37, 53 | ||
| 1170 | - | ||
| 1171 | - Write address \= (5\*4) \+ (2\*1), (5\*4) \+ (3\*1), (5\*4) \+ (0\*1), (5\*4) \+ (1\*1) \= 22, 23, 20, 21 | ||
| 1172 | - | ||
| 1173 | -Figure below shows the additional control logic required to maintain the shuffling mechanism. | ||
| 1174 | - | ||
| 1175 | - | ||
| 1176 | - | ||
| 1177 | -The index and chunk are obtained from a random number source. Chunk refers to starting chunk number and index refers to start address within the selected chunk. To account for BF latency, the index and chunk must be delayed appropriately (for our design, this latency is 10 cycles) for use in the controller shuffler logic. | ||
| 1178 | - | ||
| 1179 | -The general address calculation for NTT is: | ||
| 1180 | - | ||
| 1181 | -mem read addr=chunk+(countregular\*STEPrd) | ||
| 1182 | - | ||
| 1183 | -Since reading memory can be in order, a regular counter is used to read all 4 addresses of the selected chunk. | ||
| 1184 | - | ||
| 1185 | -mem write addr=chunkf10\*4+indexf10\*STEPwr | ||
| 1186 | - | ||
| 1187 | -The buffer address calculation for NTT is: | ||
| 1188 | - | ||
| 1189 | -buffer write addr=countregular | ||
| 1190 | - | ||
| 1191 | -buffer read addr=countindex | ||
| 1192 | - | ||
| 1193 | -Where f10 refers to delayed values by 10 cycles. In this logic, chunk is updated every 4 cycles and buffer pointer is toggled (to top or bottom half) every 4 cycles. | ||
| 1194 | - | ||
| 1195 | -The general address calculation for INTT is: | ||
| 1196 | - | ||
| 1197 | -mem read addr=(chunk\*4)+(index\*STEPrd) | ||
| 1198 | - | ||
| 1199 | -mem write addr=chunkf10+countregular\*STEPwr | ||
| 1200 | - | ||
| 1201 | -Since writing to memory can be in order, a regular counter is used to write all 4 addresses of the selected chunk. | ||
| 1202 | - | ||
| 1203 | -In INTT, index need not be delayed since the BFs consume the coefficients in the next cycle. | ||
| 1204 | - | ||
| 1205 | -The buffer address calculation for INTT is: | ||
| 1206 | - | ||
| 1207 | -buffer write addr=indexf10 | ||
| 1208 | - | ||
| 1209 | -buffer read addr=countregular | ||
| 1210 | - | ||
| 1211 | -## Rejection Sampler architecture | ||
| 1212 | - | ||
| 1213 | -Dilithium (or Kyber) samples the polynomials that make up the vectors and matrices independently, using a fixed seed value and a nonce value that increases the security as the input for Keccak. Keccak is used to take these seed and nonce and generate random stream bits. | ||
| 1214 | - | ||
| 1215 | -Rejection sampler takes 24-bits (12 bits in case of Kyber) and checks if it is less than the prime number *q* \= 223 −213\+1 \= 8380417 (q=3369 in case of Kyber). It continues to sample all required coefficients, n=256, for a polynomial. | ||
| 1216 | - | ||
| 1217 | -After sampling a polynomial with 256 coefficients, nonce will be changed and a new random stream will be generated using Keccak core and will be sampled by rejection sampling unit. | ||
| 1218 | - | ||
| 1219 | -The output of this operation results in a matrix of polynomial with k rows and l column while each polynomial includes 256 coefficients. | ||
| 1220 | - | ||
| 1221 | -\\[ | ||
| 1222 | -\begin{bmatrix} | ||
| 1223 | -A_{0,0} & \cdots & A_{0,l-1} \\ | ||
| 1224 | -\vdots & \ddots & \vdots \\ | ||
| 1225 | -A_{k-1,0} & \cdots & A_{k-1,l-1} | ||
| 1226 | -\end{bmatrix} | ||
| 1227 | -_{k*l} | ||
| 1228 | -\\] | ||
| 1229 | -Rejection sampling is used in all three operations of Dilithium, i.e., keygen, sign, and verify. Since based on the specification of the Dilithium (and Kyber), the sampled coefficients are considered in NTT domain, the output of rejection sampler can directly be used for polynomial multiplication operation, as follows: | ||
| 1230 | - | ||
| 1231 | -\\[ | ||
| 1232 | -\begin{bmatrix} | ||
| 1233 | -A_{0,0} & \cdots & A_{0,l-1} \\ | ||
| 1234 | -\vdots & \ddots & \vdots \\ | ||
| 1235 | -A_{k-1,0} & \cdots & A_{k-1,l-1} | ||
| 1236 | -\end{bmatrix} | ||
| 1237 | -\circ | ||
| 1238 | -\begin{bmatrix} | ||
| 1239 | -s_{1,0} \\ | ||
| 1240 | -\vdots \\ | ||
| 1241 | -s_{1,l-1} | ||
| 1242 | -\end{bmatrix} | ||
| 1243 | -= | ||
| 1244 | -\begin{bmatrix} | ||
| 1245 | -A_{0,0} \circ s_{1,0} + \cdots + A_{0,l-1} \circ s_{1,l-1} \\ | ||
| 1246 | -\vdots \\ | ||
| 1247 | -A_{k-1,0} \circ s_{1,0} + \cdots + A_{k-1,l-1} \circ s_{1,l-1} | ||
| 1248 | -\end{bmatrix} | ||
| 1249 | -\\] | ||
| 1250 | - | ||
| 1251 | -We propose an architecture to remove the cost of memory access from Keccak to rejection sampler, and from rejection sampler to polynomial multiplier. To achieve this, we need to have a balanced throughput between all these modules to avoid large buffering or conflict between them. | ||
| 1252 | - | ||
| 1253 | -High-level architecture is illustrated as follows: | ||
| 1254 | - | ||
| 1255 | - | ||
| 1256 | - | ||
| 1257 | -### Keccak interface to Rejection Sampler | ||
| 1258 | - | ||
| 1259 | -Keccak is used in SHAKE-128 configuration for rejection sampling operation. Hence, it will take the input data and generates 1344-bit output after each round. We propose implementing of Keccak while each round takes 12 cycles. The format of input data is as follows: | ||
| 1260 | - | ||
| 1261 | -Input data \= ρ | j | i | ||
| 1262 | - | ||
| 1263 | -Where is seed with 256-bits, i and j are nonce that describes the row and column number of corresponding polynomial A such that: | ||
| 1264 | - | ||
| 1265 | -Ai,j=Rejection\_sampling(Keccak(ρ | j | i)) | ||
| 1266 | - | ||
| 1267 | -Since each 24-bit is used for one coefficient, each round of Keccak output provides 1344/24=56 coefficients. To have 256 coefficients for each polynomial (with same seed and nonce), we need to rerun Keccak for at least 5 rounds. | ||
| 1268 | - | ||
| 1269 | -There are two paths for Keccak input. While the input can be set by controller for each new polynomial, the loop path is used to rerun Keccak for completing the previous polynomial. | ||
| 1270 | - | ||
| 1271 | -Rejection sampler cannot take all 1344-bit output parallelly since it makes hardware architecture too costly and complex, and also there is no other input from Keccak for the next 12 cycles. Therefore, we propose a parallel-input serial-output (PISO) unit in between to store the Keccak output and feed rejection unit sequentially. | ||
| 1272 | - | ||
| 1273 | -### Rejection Sampler | ||
| 1274 | - | ||
| 1275 | -This unit takes data from the output of SHAKE-128 stored in a PISO buffer. The required cycles for this unit are variable due to the non-deterministic pattern of rejection sampling. However, at least 5 Keccak rounds are required to provide 256 coefficients. | ||
| 1276 | - | ||
| 1277 | -In our optimized architecture, this unit works in parallel with the Keccak core. Therefore, the latency for rejection sampling is absorbed within the latency for a concurrently running Keccak core. | ||
| 1278 | - | ||
| 1279 | -Our proposed polynomial multiplier can perform point-wise multiplication on four coefficients per cycle that also helps to avoid memory access challenges and make the control logic too complicated. This implies that the optimal speed of the rejection sampling module is to sample four coefficients without rejection in one cycle. | ||
| 1280 | - | ||
| 1281 | -On the output side, as the rejection sampling might fail, the rejection rate for each input is: | ||
| 1282 | - | ||
| 1283 | -\\[rejection\_rate= 1-q/2^23=1-8380471/2^23=0.0009764≈10^{-3}\\] | ||
| 1284 | - | ||
| 1285 | -Hence, the probability of failure to provide 4 appropriate coefficients from 4 inputs would be: | ||
| 1286 | - | ||
| 1287 | -\\[1-(1-rejection\_rate)^4=0.00399\\] | ||
| 1288 | - | ||
| 1289 | -To reduce the failure probability and avoid any wait cycle in polynomial multiplication, 5 coefficients are fed into rejection while only 4 of them will be passed to polynomial multiplication. This decision reduces the probability of failure to | ||
| 1290 | - | ||
| 1291 | -\\[ | ||
| 1292 | -1 - (\text{probability of having 5 good inputs}) - (\text{probability of having 4 good inputs}) = | ||
| 1293 | -1 - (1 - \text{rejection\_rate})^5 - \text{rejection\_rate} \cdot | ||
| 1294 | -\binom{5}{4} \cdot (1 - \text{rejection\_rate})^4 = 0.00000998≈10^{-5} | ||
| 1295 | -\\] | ||
| 1296 | - | ||
| 1297 | -Adding a FIFO to rejection sampling unit can store the remaining unused coefficients and increase the probability of having 4 appropriate coefficients to match polynomial multiplication throughput. The architecture is as follows: | ||
| 1298 | - | ||
| 1299 | - | ||
| 1300 | - | ||
| 1301 | -There are 5 rejection sampler circuits corresponding to each 24-bit input. The controller checks if each of these coefficients should be rejected or not. The valid input coefficients can be stored into the FIFO. While maximum 5 coefficients can be fed into FIFO, there are four more entries for the remaining coefficients from the previous cycle. There are several scenarios for the proposed balanced throughput architecture: | ||
| 1302 | - | ||
| 1303 | -1) At the very first cycle, or whenever the FIFO is empty, rejection sampling unit may not provide all 4 coefficients for polynomial multiplication unit. We reduce the failure probability of this scenario by feeding 5 coefficients, however, it may happen. So, for designing efficient architecture, instead of reducing the failure probability by adding more hardware cost, we use a VALID output that stops polynomial multiplier until all 4 required coefficients are sampled. | ||
| 1304 | -2) If all 5 inputs are valid, they are going to be stored into FIFO. The first 4 coefficients will be sent to polynomial multiplication unit, while the remaining coefficients will be shifted to head of FIFO and be used for the next cycle with the first 3 valid coefficients from the next cycle. | ||
| 1305 | -3) The maximum depth of FIFO is 9 entries. If all 9 FIFO entries are full, rejection sampling unit can provide the required output for the next cycles too. Hence, it does not accept a new input from Keccak core by raising FULL flag. | ||
| 1306 | - | ||
| 1307 | - | ||
| 1308 | -| Cycle count | Input from PISO | FIFO valid entries from previous cycle | Total valid samples | output | FIFO remaining for the next cycle | | ||
| 1309 | -| :---------- | :-------------- | :------------------------------------- | :------------------ | :----- | :-------------------------------- | | ||
| 1310 | -| 0 | 5 | 0 | 5 | 4 | 1 | | ||
| 1311 | -| 1 | 5 | 1 | 6 | 4 | 2 | | ||
| 1312 | -| 2 | 5 | 2 | 7 | 4 | 3 | | ||
| 1313 | -| 3 | 5 | 3 | 8 | 4 | 4 | | ||
| 1314 | -| 4 | 5 | 4 | 9 | 4 | 5 (FULL) | | ||
| 1315 | -| 5 | 0 | 5 | 5 | 4 | 1 | | ||
| 1316 | -| 6 | 5 | 1 | 6 | 4 | 2 | | ||
| 1317 | - | ||
| 1318 | - | ||
| 1319 | - | ||
| 1320 | - | ||
| 1321 | -4) If there is not FULL condition for reading from Keccak, all PISO data can be read in 12 cycles, including 11 cycles with 5 coefficients and 1 cycle for the 56th coefficient. This would be match with Keccak throughput that generates 56 coefficients per 12 cycles. | ||
| 1322 | -5) The maximum number of FULL conditions is when there are no rejected coefficients for all 56 inputs. In this case, after 5 cycles with 5 coefficients, there is one FULL condition. After 12 cycles, 50 coefficients are processed by rejection sampling unit, and there are still 6 coefficients inside PISO. To maximize the utilization factor of our hardware resources, Keccak core will check the PISO status. If PISO contains 5 coefficients or more (the required inputs for rejection sampling unit), EMPTY flag will not be set, and Keccak will wait until the next cycle. Hence, rejection sampling unit takes 13 cycles to process 55 coefficients, and the last coefficients will be combined with the next Keccak round to be processed. | ||
| 1323 | - | ||
| 1324 | - | ||
| 1325 | - | ||
| 1326 | -### Performance of SampleRejq | ||
| 1327 | - | ||
| 1328 | -For processing each round of Keccak using rejection sampling unit, we need 12 to 13 cycles that result in 60-65 cycles for each polynomial with 256 coefficients. | ||
| 1329 | - | ||
| 1330 | -For a complete rejection sampling for Dilithium ML-DSA-87 with 8\*7=56 polynomials, 3360 to 3640 cycles are required using sequential operation. However, our design can be duplicated to enable parallel sampling for two different polynomials. Having two parallel design results in 1680 to 1820 cycles, while three parallel design results in 1120 to 1214 cycles at the cost of more resource utilization. | ||
| 1331 | - | ||
| 1332 | -## INTT architecture | ||
| 1333 | - | ||
| 1334 | -A merged-layer INTT technique uses two pipelined stages with two parallel cores in each stage level, making 4 butterfly cores in total. The parallel pipelined butterfly cores enable us to perform Radix-4 INTT operation with 4 parallel coefficients. | ||
| 1335 | - | ||
| 1336 | -However, INTT requires a specific memory pattern that may limit the efficiency of the butterfly operation. For Dilithium use case, there are n=256 coefficients per polynomial that requires log n=8 layers of INTT operations. Each butterfly unit takes two coefficients while difference between the indexes is 2i-1 in ith stage. That means for the first stage, the given indexes for each butterfly unit are (2\*k, 2\*k+1): | ||
| 1337 | - | ||
| 1338 | -Stage 1 input indexes: {(0, 1), {2, 3), (4, 5), …, (254, 255)} | ||
| 1339 | - | ||
| 1340 | -Stage 2 input indexes: {(0, 2), {1, 3), (4, 6), …, (61, 63), (64, 66), (65, 67), …, (253, 255)} | ||
| 1341 | - | ||
| 1342 | -… | ||
| 1343 | - | ||
| 1344 | -Stage 8 input indexes: {(0, 128), {1, 129), (2, 130), …, (127, 255)} | ||
| 1345 | - | ||
| 1346 | -There are several considerations for that: | ||
| 1347 | - | ||
| 1348 | -- We need access to 4 coefficients per cycle to match the throughput into 2×2 butterfly units. | ||
| 1349 | -- An optimized architecture provides a memory with only one reading port, and one writing port. | ||
| 1350 | -- Based on the previous two notes, each memory address contains 4 coefficients. | ||
| 1351 | -- The initial coefficients are stored sequentially by NTT. Specifically, they begin with 0 and continue incrementally up to 255\. Hence, at the very beginning cycle, the memory contains (0, 1, 2, 3\) in the first address, (4, 5, 6, 7\) in second address, and so on. | ||
| 1352 | -- The cost of in-place memory relocation to align the memory content is not negligible. Particularly, it needs to be repeated for each stage. | ||
| 1353 | - | ||
| 1354 | -While memory bandwidth limits the efficiency of the butterfly operation, we use a specific memory pattern to store four coefficients per address. | ||
| 1355 | - | ||
| 1356 | -We propose a pipeline architecture the read memory in a particular pattern and using a set of buffers, the corresponding coefficients are fed into INTT block. | ||
| 1357 | - | ||
| 1358 | -The initial memory contains the indexes as follows: | ||
| 1359 | - | ||
| 1360 | -| Address | Initial Memory Content |||| | ||
| 1361 | -| ------- | ---------------------- | --- | --- | --- | | ||
| 1362 | -|||||| | ||
| 1363 | -| 0 | 0 | 1 | 2 | 3 | | ||
| 1364 | -| 1 | 4 | 5 | 6 | 7 | | ||
| 1365 | -| 2 | 8 | 9 | 10 | 11 | | ||
| 1366 | -| 3 | 12 | 13 | 14 | 15 | | ||
| 1367 | -| 4 | 16 | 17 | 18 | 19 | | ||
| 1368 | -| 5 | 20 | 21 | 22 | 23 | | ||
| 1369 | -| 6 | 24 | 25 | 26 | 27 | | ||
| 1370 | -| 7 | 28 | 29 | 30 | 31 | | ||
| 1371 | -| 8 | 32 | 33 | 34 | 35 | | ||
| 1372 | -| 9 | 36 | 37 | 38 | 39 | | ||
| 1373 | -| 10 | 40 | 41 | 42 | 43 | | ||
| 1374 | -| 11 | 44 | 45 | 46 | 47 | | ||
| 1375 | -| 12 | 48 | 49 | 50 | 51 | | ||
| 1376 | -| 13 | 52 | 53 | 54 | 55 | | ||
| 1377 | -| 14 | 56 | 57 | 58 | 59 | | ||
| 1378 | -| 15 | 60 | 61 | 62 | 63 | | ||
| 1379 | -| 16 | 64 | 65 | 66 | 67 | | ||
| 1380 | -| 17 | 68 | 69 | 70 | 71 | | ||
| 1381 | -| 18 | 72 | 73 | 74 | 75 | | ||
| 1382 | -| 19 | 76 | 77 | 78 | 79 | | ||
| 1383 | -| 20 | 80 | 81 | 82 | 83 | | ||
| 1384 | -| 21 | 84 | 85 | 86 | 87 | | ||
| 1385 | -| 22 | 88 | 89 | 90 | 91 | | ||
| 1386 | -| 23 | 92 | 93 | 94 | 95 | | ||
| 1387 | -| 24 | 96 | 97 | 98 | 99 | | ||
| 1388 | -| 25 | 100 | 101 | 102 | 103 | | ||
| 1389 | -| 26 | 104 | 105 | 106 | 107 | | ||
| 1390 | -| 27 | 108 | 109 | 110 | 111 | | ||
| 1391 | -| 28 | 112 | 113 | 114 | 115 | | ||
| 1392 | -| 29 | 116 | 117 | 118 | 119 | | ||
| 1393 | -| 30 | 120 | 121 | 122 | 123 | | ||
| 1394 | -| 31 | 124 | 125 | 126 | 127 | | ||
| 1395 | -| 32 | 128 | 129 | 130 | 131 | | ||
| 1396 | -| 33 | 132 | 133 | 134 | 135 | | ||
| 1397 | -| 34 | 136 | 137 | 138 | 139 | | ||
| 1398 | -| 35 | 140 | 141 | 142 | 143 | | ||
| 1399 | -| 36 | 144 | 145 | 146 | 147 | | ||
| 1400 | -| 37 | 148 | 149 | 150 | 151 | | ||
| 1401 | -| 38 | 152 | 153 | 154 | 155 | | ||
| 1402 | -| 39 | 156 | 157 | 158 | 159 | | ||
| 1403 | -| 40 | 160 | 161 | 162 | 163 | | ||
| 1404 | -| 41 | 164 | 165 | 166 | 167 | | ||
| 1405 | -| 42 | 168 | 169 | 170 | 171 | | ||
| 1406 | -| 43 | 172 | 173 | 174 | 175 | | ||
| 1407 | -| 44 | 176 | 177 | 178 | 179 | | ||
| 1408 | -| 45 | 180 | 181 | 182 | 183 | | ||
| 1409 | -| 46 | 184 | 185 | 186 | 187 | | ||
| 1410 | -| 47 | 188 | 189 | 190 | 191 | | ||
| 1411 | -| 48 | 192 | 193 | 194 | 195 | | ||
| 1412 | -| 49 | 196 | 197 | 198 | 199 | | ||
| 1413 | -| 50 | 200 | 201 | 202 | 203 | | ||
| 1414 | -| 51 | 204 | 205 | 206 | 207 | | ||
| 1415 | -| 52 | 208 | 209 | 210 | 211 | | ||
| 1416 | -| 53 | 212 | 213 | 214 | 215 | | ||
| 1417 | -| 54 | 216 | 217 | 218 | 219 | | ||
| 1418 | -| 55 | 220 | 221 | 222 | 223 | | ||
| 1419 | -| 56 | 224 | 225 | 226 | 227 | | ||
| 1420 | -| 57 | 228 | 229 | 230 | 231 | | ||
| 1421 | -| 58 | 232 | 233 | 234 | 235 | | ||
| 1422 | -| 59 | 236 | 237 | 238 | 239 | | ||
| 1423 | -| 60 | 240 | 241 | 242 | 243 | | ||
| 1424 | -| 61 | 244 | 245 | 246 | 247 | | ||
| 1425 | -| 62 | 248 | 249 | 250 | 251 | | ||
| 1426 | -| 63 | 252 | 253 | 254 | 255 | | ||
| 1427 | - | ||
| 1428 | - | ||
| 1429 | -Suppose memory is read in the regular pattern: | ||
| 1430 | - | ||
| 1431 | -Reading Addr: 0, 1, 2, 3, 4, …, 62, 63 | ||
| 1432 | - | ||
| 1433 | -The input goes to the butterfly architecture. The input values contain the required coefficients for our butterfly units in the next stage, i.e., (0, 1\) and (2, 3). Since we merged the first and second layers of INTT stages, the output of the first parallel butterfly units need to exchange one coefficient and then the required input for the second parallel set of butterfly units is ready, i.e., (0, 2\) and (1, 3). | ||
| 1434 | - | ||
| 1435 | - | ||
| 1436 | - | ||
| 1437 | -To prepare the results for the next stages, the output needs to be stored into the customized buffer architecture as follows: | ||
| 1438 | - | ||
| 1439 | -| 0 | → |||||||| | ||
| 1440 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1441 | -| 1 ||||||||| | ||
| 1442 | -| 2 ||||||||| | ||
| 1443 | -| 3 ||||||||| | ||
| 1444 | - | ||
| 1445 | - | ||
| 1446 | -Cycle 0 after butterfly reading address 0 | ||
| 1447 | - | ||
| 1448 | -| 4 | → |||| 0 |||| | ||
| 1449 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1450 | -| 5 |||| 1 ||||| | ||
| 1451 | -| 6 ||| 2 |||||| | ||
| 1452 | -| 7 || 3 ||||||| | ||
| 1453 | - | ||
| 1454 | - | ||
| 1455 | -Cycle 0 after butterfly reading address 1 | ||
| 1456 | - | ||
| 1457 | -| 8 | → |||| 4 | 0 ||| | ||
| 1458 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1459 | -| 9 |||| 5 | 1 |||| | ||
| 1460 | -| 10 ||| 6 | 2 ||||| | ||
| 1461 | -| 11 || 7 | 3 |||||| | ||
| 1462 | - | ||
| 1463 | - | ||
| 1464 | -Cycle 2 after butterfly reading address 2 | ||
| 1465 | - | ||
| 1466 | -| 12 | → |||| 8 | 4 | 0 || | ||
| 1467 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1468 | -| 13 |||| 9 | 5 | 1 ||| | ||
| 1469 | -| 14 ||| 10 | 6 | 2 |||| | ||
| 1470 | -| 15 || 11 | 7 | 3 ||||| | ||
| 1471 | - | ||
| 1472 | - | ||
| 1473 | -Cycle 3 after butterfly reading address 3 | ||
| 1474 | - | ||
| 1475 | -| 16 | → |||| 12 | 8 | 4 | 0 | | ||
| 1476 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1477 | -| 17 |||| 13 | 9 | 5 | 1 || | ||
| 1478 | -| 18 ||| 14 | 10 | 6 | 2 ||| | ||
| 1479 | -| 19 || 15 | 11 | 7 | 3 |||| | ||
| 1480 | - | ||
| 1481 | - | ||
| 1482 | -Cycle 4 after butterfly reading address 4 | ||
| 1483 | - | ||
| 1484 | -| 20 | → |||| 16 | 12 | 8 | 4 | | ||
| 1485 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1486 | -| 21 |||| 17 | 13 | 9 | 5 | 1 | | ||
| 1487 | -| 22 ||| 18 | 14 | 10 | 6 | 2 || | ||
| 1488 | -| 23 || 19 | 15 | 11 | 7 | 3 ||| | ||
| 1489 | - | ||
| 1490 | - | ||
| 1491 | -Cycle 5 after butterfly reading address 5 | ||
| 1492 | - | ||
| 1493 | -The highlighted value in the first buffer contains the required coefficients for our butterfly units in the next stage, i.e., (0, 4\) and (8, 12). | ||
| 1494 | - | ||
| 1495 | -However, we need to write the output in a particular pattern as follows: | ||
| 1496 | - | ||
| 1497 | -Writing Addr: 0, 16, 32, 48, 1, 17, 33, 49, …, 15, 31, 47, 63 | ||
| 1498 | - | ||
| 1499 | -After completing the first round of operation including INTT stage 1 and 2, the memory contains the following data: | ||
| 1500 | - | ||
| 1501 | -| Address | Memory Content after 1&2 stages |||| | ||
| 1502 | -| ------- | ------------------------------- | --- | --- | --- | | ||
| 1503 | -|||||| | ||
| 1504 | -| 0 | 0 | 4 | 8 | 12 | | ||
| 1505 | -| 1 | 16 | 20 | 24 | 28 | | ||
| 1506 | -| 2 | 32 | 36 | 40 | 44 | | ||
| 1507 | -| 3 | 48 | 52 | 56 | 60 | | ||
| 1508 | -| 4 | 64 | 68 | 72 | 76 | | ||
| 1509 | -| 5 | 80 | 84 | 88 | 92 | | ||
| 1510 | -| 6 | 96 | 100 | 104 | 108 | | ||
| 1511 | -| 7 | 112 | 116 | 120 | 124 | | ||
| 1512 | -| 8 | 128 | 132 | 136 | 140 | | ||
| 1513 | -| 9 | 144 | 148 | 152 | 156 | | ||
| 1514 | -| 10 | 160 | 164 | 168 | 172 | | ||
| 1515 | -| 11 | 176 | 180 | 184 | 188 | | ||
| 1516 | -| 12 | 192 | 196 | 200 | 204 | | ||
| 1517 | -| 13 | 208 | 212 | 216 | 220 | | ||
| 1518 | -| 14 | 224 | 228 | 232 | 236 | | ||
| 1519 | -| 15 | 240 | 244 | 248 | 252 | | ||
| 1520 | -| 16 | 1 | 5 | 9 | 13 | | ||
| 1521 | -| 17 | 17 | 21 | 25 | 29 | | ||
| 1522 | -| 18 | 33 | 37 | 41 | 45 | | ||
| 1523 | -| 19 | 49 | 53 | 57 | 61 | | ||
| 1524 | -| 20 | 65 | 69 | 73 | 77 | | ||
| 1525 | -| 21 | 81 | 85 | 89 | 93 | | ||
| 1526 | -| 22 | 97 | 101 | 105 | 109 | | ||
| 1527 | -| 23 | 113 | 117 | 121 | 125 | | ||
| 1528 | -| 24 | 129 | 133 | 137 | 141 | | ||
| 1529 | -| 25 | 145 | 149 | 153 | 157 | | ||
| 1530 | -| 26 | 161 | 165 | 169 | 173 | | ||
| 1531 | -| 27 | 177 | 181 | 185 | 189 | | ||
| 1532 | -| 28 | 193 | 197 | 201 | 205 | | ||
| 1533 | -| 29 | 209 | 213 | 217 | 221 | | ||
| 1534 | -| 30 | 225 | 229 | 233 | 237 | | ||
| 1535 | -| 31 | 241 | 245 | 249 | 253 | | ||
| 1536 | -| 32 | 2 | 6 | 10 | 14 | | ||
| 1537 | -| 33 | 18 | 22 | 26 | 30 | | ||
| 1538 | -| 34 | 34 | 38 | 42 | 46 | | ||
| 1539 | -| 35 | 50 | 54 | 58 | 62 | | ||
| 1540 | -| 36 | 66 | 70 | 74 | 78 | | ||
| 1541 | -| 37 | 82 | 86 | 90 | 94 | | ||
| 1542 | -| 38 | 98 | 102 | 106 | 110 | | ||
| 1543 | -| 39 | 114 | 118 | 122 | 126 | | ||
| 1544 | -| 40 | 130 | 134 | 138 | 142 | | ||
| 1545 | -| 41 | 146 | 150 | 154 | 158 | | ||
| 1546 | -| 42 | 162 | 166 | 170 | 174 | | ||
| 1547 | -| 43 | 178 | 182 | 186 | 190 | | ||
| 1548 | -| 44 | 194 | 198 | 202 | 206 | | ||
| 1549 | -| 45 | 210 | 214 | 218 | 222 | | ||
| 1550 | -| 46 | 226 | 230 | 234 | 238 | | ||
| 1551 | -| 47 | 242 | 246 | 250 | 254 | | ||
| 1552 | -| 48 | 3 | 7 | 11 | 15 | | ||
| 1553 | -| 49 | 19 | 23 | 27 | 31 | | ||
| 1554 | -| 50 | 35 | 39 | 43 | 47 | | ||
| 1555 | -| 51 | 51 | 55 | 59 | 63 | | ||
| 1556 | -| 52 | 67 | 71 | 75 | 79 | | ||
| 1557 | -| 53 | 83 | 87 | 91 | 95 | | ||
| 1558 | -| 54 | 99 | 103 | 107 | 111 | | ||
| 1559 | -| 55 | 115 | 119 | 123 | 127 | | ||
| 1560 | -| 56 | 131 | 135 | 139 | 143 | | ||
| 1561 | -| 57 | 147 | 151 | 155 | 159 | | ||
| 1562 | -| 58 | 163 | 167 | 171 | 175 | | ||
| 1563 | -| 59 | 179 | 183 | 187 | 191 | | ||
| 1564 | -| 60 | 195 | 199 | 203 | 207 | | ||
| 1565 | -| 61 | 211 | 215 | 219 | 223 | | ||
| 1566 | -| 62 | 227 | 231 | 235 | 239 | | ||
| 1567 | -| 63 | 243 | 247 | 251 | 255 | | ||
| 1568 | - | ||
| 1569 | - | ||
| 1570 | -The same process can be applied in the next round to perform INTT stage 3 and 4\. | ||
| 1571 | - | ||
| 1572 | -| 0 | → |||||||| | ||
| 1573 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1574 | -| 4 ||||||||| | ||
| 1575 | -| 8 ||||||||| | ||
| 1576 | -| 12 ||||||||| | ||
| 1577 | - | ||
| 1578 | - | ||
| 1579 | -Cycle 0 after butterfly reading address 0 | ||
| 1580 | - | ||
| 1581 | -| 16 | → |||| 0 |||| | ||
| 1582 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1583 | -| 20 |||| 4 ||||| | ||
| 1584 | -| 24 ||| 8 |||||| | ||
| 1585 | -| 28 || 12 ||||||| | ||
| 1586 | - | ||
| 1587 | - | ||
| 1588 | -Cycle 1 after butterfly reading address 1 | ||
| 1589 | - | ||
| 1590 | -| 32 | → |||| 16 | 0 ||| | ||
| 1591 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1592 | -| 36 |||| 20 | 4 |||| | ||
| 1593 | -| 40 ||| 24 | 8 ||||| | ||
| 1594 | -| 44 || 28 | 12 |||||| | ||
| 1595 | - | ||
| 1596 | - | ||
| 1597 | -Cycle 2 after butterfly reading address 2 | ||
| 1598 | - | ||
| 1599 | -| 48 | → |||| 32 | 16 | 0 || | ||
| 1600 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1601 | -| 52 |||| 36 | 20 | 4 ||| | ||
| 1602 | -| 56 ||| 40 | 24 | 8 |||| | ||
| 1603 | -| 60 || 44 | 28 | 12 ||||| | ||
| 1604 | - | ||
| 1605 | - | ||
| 1606 | -Cycle 3 after butterfly reading address 3 | ||
| 1607 | - | ||
| 1608 | -| 64 | → |||| 48 | 32 | 16 | 0 | | ||
| 1609 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1610 | -| 68 |||| 52 | 36 | 20 | 4 || | ||
| 1611 | -| 72 ||| 56 | 40 | 24 | 8 ||| | ||
| 1612 | -| 76 || 60 | 44 | 28 | 12 |||| | ||
| 1613 | - | ||
| 1614 | - | ||
| 1615 | -Cycle 4 after butterfly reading address 4 | ||
| 1616 | - | ||
| 1617 | -| 80 | → |||| 64 | 48 | 32 | 16 | | ||
| 1618 | -| :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | | ||
| 1619 | -| 84 |||| 68 | 52 | 36 | 20 | 4 | | ||
| 1620 | -| 88 ||| 72 | 56 | 40 | 24 | 8 || | ||
| 1621 | -| 92 || 76 | 60 | 44 | 28 | 12 ||| | ||
| 1622 | - | ||
| 1623 | - | ||
| 1624 | -Cycle 5 after butterfly reading address 5 | ||
| 1625 | - | ||
| 1626 | -After completing all stages, the memory contents would be as follows: | ||
| 1627 | - | ||
| 1628 | -| Address | Memory Content after Stage 7&8 |||| | ||
| 1629 | -| ------- | ------------------------------ | --- | --- | --- | | ||
| 1630 | -|||||| | ||
| 1631 | -| 0 | 0 | 1 | 2 | 3 | | ||
| 1632 | -| 1 | 4 | 5 | 6 | 7 | | ||
| 1633 | -| 2 | 8 | 9 | 10 | 11 | | ||
| 1634 | -| 3 | 12 | 13 | 14 | 15 | | ||
| 1635 | -| 4 | 16 | 17 | 18 | 19 | | ||
| 1636 | -| 5 | 20 | 21 | 22 | 23 | | ||
| 1637 | -| 6 | 24 | 25 | 26 | 27 | | ||
| 1638 | -| 7 | 28 | 29 | 30 | 31 | | ||
| 1639 | -| 8 | 32 | 33 | 34 | 35 | | ||
| 1640 | -| 9 | 36 | 37 | 38 | 39 | | ||
| 1641 | -| 10 | 40 | 41 | 42 | 43 | | ||
| 1642 | -| 11 | 44 | 45 | 46 | 47 | | ||
| 1643 | -| 12 | 48 | 49 | 50 | 51 | | ||
| 1644 | -| 13 | 52 | 53 | 54 | 55 | | ||
| 1645 | -| 14 | 56 | 57 | 58 | 59 | | ||
| 1646 | -| 15 | 60 | 61 | 62 | 63 | | ||
| 1647 | -| 16 | 64 | 65 | 66 | 67 | | ||
| 1648 | -| 17 | 68 | 69 | 70 | 71 | | ||
| 1649 | -| 18 | 72 | 73 | 74 | 75 | | ||
| 1650 | -| 19 | 76 | 77 | 78 | 79 | | ||
| 1651 | -| 20 | 80 | 81 | 82 | 83 | | ||
| 1652 | -| 21 | 84 | 85 | 86 | 87 | | ||
| 1653 | -| 22 | 88 | 89 | 90 | 91 | | ||
| 1654 | -| 23 | 92 | 93 | 94 | 95 | | ||
| 1655 | -| 24 | 96 | 97 | 98 | 99 | | ||
| 1656 | -| 25 | 100 | 101 | 102 | 103 | | ||
| 1657 | -| 26 | 104 | 105 | 106 | 107 | | ||
| 1658 | -| 27 | 108 | 109 | 110 | 111 | | ||
| 1659 | -| 28 | 112 | 113 | 114 | 115 | | ||
| 1660 | -| 29 | 116 | 117 | 118 | 119 | | ||
| 1661 | -| 30 | 120 | 121 | 122 | 123 | | ||
| 1662 | -| 31 | 124 | 125 | 126 | 127 | | ||
| 1663 | -| 32 | 128 | 129 | 130 | 131 | | ||
| 1664 | -| 33 | 132 | 133 | 134 | 135 | | ||
| 1665 | -| 34 | 136 | 137 | 138 | 139 | | ||
| 1666 | -| 35 | 140 | 141 | 142 | 143 | | ||
| 1667 | -| 36 | 144 | 145 | 146 | 147 | | ||
| 1668 | -| 37 | 148 | 149 | 150 | 151 | | ||
| 1669 | -| 38 | 152 | 153 | 154 | 155 | | ||
| 1670 | -| 39 | 156 | 157 | 158 | 159 | | ||
| 1671 | -| 40 | 160 | 161 | 162 | 163 | | ||
| 1672 | -| 41 | 164 | 165 | 166 | 167 | | ||
| 1673 | -| 42 | 168 | 169 | 170 | 171 | | ||
| 1674 | -| 43 | 172 | 173 | 174 | 175 | | ||
| 1675 | -| 44 | 176 | 177 | 178 | 179 | | ||
| 1676 | -| 45 | 180 | 181 | 182 | 183 | | ||
| 1677 | -| 46 | 184 | 185 | 186 | 187 | | ||
| 1678 | -| 47 | 188 | 189 | 190 | 191 | | ||
| 1679 | -| 48 | 192 | 193 | 194 | 195 | | ||
| 1680 | -| 49 | 196 | 197 | 198 | 199 | | ||
| 1681 | -| 50 | 200 | 201 | 202 | 203 | | ||
| 1682 | -| 51 | 204 | 205 | 206 | 207 | | ||
| 1683 | -| 52 | 208 | 209 | 210 | 211 | | ||
| 1684 | -| 53 | 212 | 213 | 214 | 215 | | ||
| 1685 | -| 54 | 216 | 217 | 218 | 219 | | ||
| 1686 | -| 55 | 220 | 221 | 222 | 223 | | ||
| 1687 | -| 56 | 224 | 225 | 226 | 227 | | ||
| 1688 | -| 57 | 228 | 229 | 230 | 231 | | ||
| 1689 | -| 58 | 232 | 233 | 234 | 235 | | ||
| 1690 | -| 59 | 236 | 237 | 238 | 239 | | ||
| 1691 | -| 60 | 240 | 241 | 242 | 243 | | ||
| 1692 | -| 61 | 244 | 245 | 246 | 247 | | ||
| 1693 | -| 62 | 248 | 249 | 250 | 251 | | ||
| 1694 | -| 63 | 252 | 253 | 254 | 255 | | ||
| 1695 | - | ||
| 1696 | - | ||
| 1697 | -The proposed method saves the time needed for shuffling and reordering, while using only a little more memory. | ||
| 1698 | - | ||
| 1699 | -### INTT shuffling countermeasure | ||
| 1700 | - | ||
| 1701 | -Similar to NTT operation, INTT requires shuffling the order of execution of coefficients in order to mitigate SCA attacks. Refer to section 5.3.3 for details on NTT shuffling. In INTT mode, the chunks are split in the following pattern into 16 chunks: | ||
| 1702 | - | ||
| 1703 | -| Address || 1&2 |||| | ||
| 1704 | -| ------- | --- | --- | --- | --- | --- | | ||
| 1705 | -||||||| | ||
| 1706 | -| 0 || 0 | 1 | 2 | 3 | | ||
| 1707 | -| 1 || 4 | 5 | 6 | 7 | | ||
| 1708 | -| 2 || 8 | 9 | 10 | 11 | | ||
| 1709 | -| 3 || 12 | 13 | 14 | 15 | | ||
| 1710 | -| 4 || 16 | 17 | 18 | 19 | | ||
| 1711 | -| 5 || 20 | 21 | 22 | 23 | | ||
| 1712 | -| 6 || 24 | 25 | 26 | 27 | | ||
| 1713 | -| 7 || 28 | 29 | 30 | 31 | | ||
| 1714 | -| 8 || 32 | 33 | 34 | 35 | | ||
| 1715 | -| 9 || 36 | 37 | 38 | 39 | | ||
| 1716 | -| 10 || 40 | 41 | 42 | 43 | | ||
| 1717 | -| 11 || 44 | 45 | 46 | 47 | | ||
| 1718 | -| 12 || 48 | 49 | 50 | 51 | | ||
| 1719 | -| 13 || 52 | 53 | 54 | 55 | | ||
| 1720 | -| 14 || 56 | 57 | 58 | 59 | | ||
| 1721 | -| 15 || 60 | 61 | 62 | 63 | | ||
| 1722 | -| 16 || 64 | 65 | 66 | 67 | | ||
| 1723 | -| 17 || 68 | 69 | 70 | 71 | | ||
| 1724 | -| 18 || 72 | 73 | 74 | 75 | | ||
| 1725 | -| 19 || 76 | 77 | 78 | 79 | | ||
| 1726 | -| 20 || 80 | 81 | 82 | 83 | | ||
| 1727 | -| 21 || 84 | 85 | 86 | 87 | | ||
| 1728 | -| 22 || 88 | 89 | 90 | 91 | | ||
| 1729 | -| 23 || 92 | 93 | 94 | 95 | | ||
| 1730 | -| 24 || 96 | 97 | 98 | 99 | | ||
| 1731 | -| 25 || 100 | 101 | 102 | 103 | | ||
| 1732 | -| 26 || 104 | 105 | 106 | 107 | | ||
| 1733 | -| 27 || 108 | 109 | 110 | 111 | | ||
| 1734 | -| 28 || 112 | 113 | 114 | 115 | | ||
| 1735 | -| 29 || 116 | 117 | 118 | 119 | | ||
| 1736 | -| 30 || 120 | 121 | 122 | 123 | | ||
| 1737 | -| 31 || 124 | 125 | 126 | 127 | | ||
| 1738 | -| 32 || 128 | 129 | 130 | 131 | | ||
| 1739 | -| 33 || 132 | 133 | 134 | 135 | | ||
| 1740 | -| 34 || 136 | 137 | 138 | 139 | | ||
| 1741 | -| 35 || 140 | 141 | 142 | 143 | | ||
| 1742 | -| 36 || 144 | 145 | 146 | 147 | | ||
| 1743 | -| 37 || 148 | 149 | 150 | 151 | | ||
| 1744 | -| 38 || 152 | 153 | 154 | 155 | | ||
| 1745 | -| 39 || 156 | 157 | 158 | 159 | | ||
| 1746 | -| 40 || 160 | 161 | 162 | 163 | | ||
| 1747 | -| 41 || 164 | 165 | 166 | 167 | | ||
| 1748 | -| 42 || 168 | 169 | 170 | 171 | | ||
| 1749 | -| 43 || 172 | 173 | 174 | 175 | | ||
| 1750 | -| 44 || 176 | 177 | 178 | 179 | | ||
| 1751 | -| 45 || 180 | 181 | 182 | 183 | | ||
| 1752 | -| 46 || 184 | 185 | 186 | 187 | | ||
| 1753 | -| 47 || 188 | 189 | 190 | 191 | | ||
| 1754 | -| 48 || 192 | 193 | 194 | 195 | | ||
| 1755 | -| 49 || 196 | 197 | 198 | 199 | | ||
| 1756 | -| 50 || 200 | 201 | 202 | 203 | | ||
| 1757 | -| 51 || 204 | 205 | 206 | 207 | | ||
| 1758 | -| 52 || 208 | 209 | 210 | 211 | | ||
| 1759 | -| 53 || 212 | 213 | 214 | 215 | | ||
| 1760 | -| 54 || 216 | 217 | 218 | 219 | | ||
| 1761 | -| 55 || 220 | 221 | 222 | 223 | | ||
| 1762 | -| 56 || 224 | 225 | 226 | 227 | | ||
| 1763 | -| 57 || 228 | 229 | 230 | 231 | | ||
| 1764 | -| 58 || 232 | 233 | 234 | 235 | | ||
| 1765 | -| 59 || 236 | 237 | 238 | 239 | | ||
| 1766 | -| 60 || 240 | 241 | 242 | 243 | | ||
| 1767 | -| 61 || 244 | 245 | 246 | 247 | | ||
| 1768 | -| 62 || 248 | 249 | 250 | 251 | | ||
| 1769 | -| 63 || 252 | 253 | 254 | 255 | | ||
| 1770 | - | ||
| 1771 | - | ||
| 1772 | -(0, 1, 2, 3\) addresses are chunk0, (4,5,6,7) are chunk1, etc. Chunk addresses are in order since for INTT, reads are in order and writes are out of order. Similar to NTT, two levels of randomization are used: | ||
| 1773 | - | ||
| 1774 | -1. Starting chunk is randomized | ||
| 1775 | -2. Start address within each chunk is randomized | ||
| 1776 | - | ||
| 1777 | -With this technique, the search space is 16 ×416=236. For example, if chunk 5 is selected as the starting chunk, and start address is 1, the order of execution is (21, 22, 23, 20). When next chunk is selected (chunk 6), start address is again randomized. For example, next order can be (27, 24, 25, 26\) and so on. | ||
| 1778 | - | ||
| 1779 | -The output buffer in INTT mode is configured as below. The buffer write pointer is aligned with the start address of the selected chunk and wraps around. In the given example, buffer write pointer increments as (1, 2, 3, 0\) and the outputs of butterfly2x2 are stored in the buffer in locations (1, 2, 3, 0\) in the order shown by superscript in the table below. This ensures the correct data is written back to memory to the correct addresses. In INTT mode, memory reads are randomized and memory writes will be in order. | ||
| 1780 | - | ||
| 1781 | -| 1110 | 1100 | 1090 | 1080 | | ||
| 1782 | -| :--- | :--- | :--- | :--- | | ||
| 1783 | -| 1073 | 1063 | 1053 | 1043 | | ||
| 1784 | -| 1032 | 1022 | 1012 | 1002 | | ||
| 1785 | -| 991 | 981 | 971 | 961 | | ||
| 1786 | -| 952 | 942 | 932 | 922 | | ||
| 1787 | -| 911 | 901 | 891 | 881 | | ||
| 1788 | -| 870 | 860 | 850 | 840 | | ||
| 1789 | -| 833 | 823 | 813 | 803 | | ||
| 1790 | - | ||
| 1791 | - | ||
| 1792 | -While the next chunk starts, the data in the bottom half of the buffer is written to memory. Since every cycle there is a write to memory and write to the other half of the buffer, this incurs no latency overhead. | ||
| 1793 | - | ||
| 1794 | -Memory read and write addresses are calculated as shown | ||
| 1795 | - | ||
| 1796 | -for i in range (0, 4): | ||
| 1797 | - | ||
| 1798 | - Read address \= (chunk\*4) \+ (rand\_index \* INTT\_RD\_STEP) | ||
| 1799 | - | ||
| 1800 | -Write address \= chunk \+ (i \* INTT\_WR\_STEP) | ||
| 1801 | - | ||
| 1802 | -Where rand\_index is the randomized start index of execution order for an NTT operation | ||
| 1803 | - | ||
| 1804 | -E.g. if selected chunk is 5, and rand\_index is 2 | ||
| 1805 | - | ||
| 1806 | - Order of execution is 2, 3, 0, 1 | ||
| 1807 | - | ||
| 1808 | - Read address \= 5\*4 \+ (2\*1), 5\*4 \+ (3\*1), 5\*4+(0\*1), 5\*4+(1\*1) \= 22, 23, 20, 21 | ||
| 1809 | - | ||
| 1810 | - Write address \= 5 \+ (2\*16), 5 \+ (3\*16), 5 \+ (0\*16), 5 \+ (1\*16) \= 37, 53, 5, 21 | ||
| 1811 | - | ||
| 1812 | -## Point-wise Multiplication architecture | ||
| 1813 | - | ||
| 1814 | -Polynomial in NTT domain can be performed using point-wise multiplication (PWM). Considering the current architecture with 4 butterfly units, there are 4 modular multiplications that can be reused in point-wise multiplication operation. This approach enhances the design from an optimization perspective by resource sharing technique. \` | ||
| 1815 | - | ||
| 1816 | -There are 2 memories containing polynomial f and g, with 4 coefficients per each memory address. The parallel butterfly cores enable us to perform 4 point-wise multiplication operations with 4 parallel coefficients as follows: | ||
| 1817 | - | ||
| 1818 | - | ||
| 1819 | - | ||
| 1820 | -The proposed NTT method preserves the memory contents in sequence without needing to shuffle and reorder them, so the point-wise multiplication can be sped up by using consistent reading/writing addresses from both memories. | ||
| 1821 | - | ||
| 1822 | -## RejBounded architecture | ||
| 1823 | - | ||
| 1824 | -This unit takes data from the output of SHAKE-256 stored in a PISO buffer. The required cycles for this unit are variable due to the non-deterministic pattern of sampling. However, at least 1 Keccak round is required to provide 256 coefficients. | ||
| 1825 | - | ||
| 1826 | -This unit takes 4 bits from Keccak output. For ML-DSA-87 scheme, the only rejected sample is input data equal to 15 which means the probability of rejection is 116 . | ||
| 1827 | - | ||
| 1828 | -| b (4-bit Input) | b mod 5 | 2-(b mod 5\) | valid/invalid | Output mod q | | ||
| 1829 | -| :-------------: | :-----: | :----------: | :-----------: | :----------: | | ||
| 1830 | -| 0 | 0 | 2 | valid | 2 | | ||
| 1831 | -| 1 | 1 | 1 | valid | 1 | | ||
| 1832 | -| 2 | 2 | 0 | valid | 0 | | ||
| 1833 | -| 3 | 3 | \-1 | valid | 8380416 | | ||
| 1834 | -| 4 | 4 | \-2 | valid | 8380415 | | ||
| 1835 | -| 5 | 0 | 2 | valid | 2 | | ||
| 1836 | -| 6 | 1 | 1 | valid | 1 | | ||
| 1837 | -| 7 | 2 | 0 | valid | 0 | | ||
| 1838 | -| 8 | 3 | \-1 | valid | 8380416 | | ||
| 1839 | -| 9 | 4 | \-2 | valid | 8380415 | | ||
| 1840 | -| 10 | 0 | 2 | valid | 2 | | ||
| 1841 | -| 11 | 1 | 1 | valid | 1 | | ||
| 1842 | -| 12 | 2 | 0 | valid | 0 | | ||
| 1843 | -| 13 | 3 | \-1 | valid | 8380416 | | ||
| 1844 | -| 14 | 4 | \-2 | valid | 8380415 | | ||
| 1845 | -| 15 | 0 | 2 | invalid | invalid | | ||
| 1846 | - | ||
| 1847 | - | ||
| 1848 | -In our optimized architecture, this unit works in parallel with the Keccak core. Therefore, the latency for RejBounded sampling is absorbed within the latency for a concurrently running Keccak core. | ||
| 1849 | - | ||
| 1850 | -Our proposed NTT can perform on four coefficients per cycle that also helps to avoid memory access challenges and make the control logic too complicated. This implies that the optimal speed of the RejBounded sampling module is to sample four coefficients without rejection in one cycle. | ||
| 1851 | - | ||
| 1852 | -On the output side, as the RejBouned sampling might fail, the rejection rate for each input is: | ||
| 1853 | - | ||
| 1854 | -\\[rejection\_rate=1/16=0.0625\\] | ||
| 1855 | - | ||
| 1856 | -Hence, the probability of failure to provide 4 appropriate coefficients from 4 inputs would be: | ||
| 1857 | - | ||
| 1858 | -\\[1-(1-rejection\_rate)^4=0.2275\\] | ||
| 1859 | - | ||
| 1860 | -To reduce the failure probability and avoid any wait cycle in polynomial multiplication, 5 coefficients are fed into rejection while only 4 of them will be passed to polynomial multiplication. This decision reduces the probability of failure to | ||
| 1861 | - | ||
| 1862 | -\\[ | ||
| 1863 | -1 - (\text{probability of having 5 good inputs}) - (\text{probability of having 4 good inputs}) = | ||
| 1864 | -1 - (1 - \text{rejection\_rate})^5 - \text{rejection\_rate} \cdot | ||
| 1865 | -\binom{5}{4} \cdot (1 - \text{rejection\_rate})^4 = 0.0344 | ||
| 1866 | -\\] | ||
| 1867 | - | ||
| 1868 | - | ||
| 1869 | -The following is the probability of failure for a design that has 4 samplings per cycle: | ||
| 1870 | - | ||
| 1871 | -| Sample number in input | Failure probability of 4 valid output | | ||
| 1872 | -| :--------------------- | :------------------------------------ | | ||
| 1873 | -| 4 | 0.2275238037109375 | | ||
| 1874 | -| 5 | 0.034404754638671875 | | ||
| 1875 | -| 6 | 0.004229903221130371 | | ||
| 1876 | -| 7 | 0.0004580467939376831 | | ||
| 1877 | -| 8 | 4.549999721348286e-05 | | ||
| 1878 | - | ||
| 1879 | - | ||
| 1880 | -The following is the probability of failure for a high-throughput design that has 8 samplings per cycle: | ||
| 1881 | - | ||
| 1882 | -| Sample number in input | Failure probability of 8 valid output | | ||
| 1883 | -| :--------------------- | :------------------------------------ | | ||
| 1884 | -| 8 | 0.4032805261667818 | | ||
| 1885 | -| 9 | 0.10492078925017267 | | ||
| 1886 | -| 10 | 0.021007113242376363 | | ||
| 1887 | -| 11 | 0.003525097407418798 | | ||
| 1888 | -| 12 | 0.0005203759357854665 | | ||
| 1889 | -| 13 | 6.966771504046676e-05 | | ||
| 1890 | - | ||
| 1891 | - | ||
| 1892 | -Adding a FIFO to RejBounded sampling unit can store the remaining unused coefficients and increase the probability of having 4 appropriate coefficients to match polynomial multiplication throughput. The architecture is as follows: | ||
| 1893 | - | ||
| 1894 | - | ||
| 1895 | - | ||
| 1896 | -There are 8 rejection sampler circuits corresponding to each 4-bit input. The controller checks if each of these coefficients should be rejected or not. The valid input coefficients will be processes and a result between \[-η, η\] ( is 2 for ML-DSA-87) will be stored into the FIFO. While maximum 8 coefficients can be fed into FIFO, there are four more entries for the remaining coefficients from the previous cycle. There are several scenarios for the proposed balanced throughput architecture: | ||
| 1897 | - | ||
| 1898 | -1) At the very first cycle, or whenever the FIFO is empty, RejBounded sampling unit may not provide all 4 coefficients for polynomial multiplication unit. We reduce the failure probability of this scenario by feeding 8 coefficients, however, it may happen. So, for designing efficient architecture, instead of reducing the failure probability by adding more hardware cost, we use a VALID output that stops polynomial multiplier until all 4 required coefficients are sampled. | ||
| 1899 | -2) If more than 4 inputs are valid, they are going to be stored into FIFO. The first 4 coefficients will be sent to polynomial multiplication unit, while the remaining coefficients will be shifted to head of FIFO and be used for the next cycle with the valid coefficients from the next cycle. | ||
| 1900 | -3) The maximum depth of FIFO is 12 entries. The input needs 8 entities that are ready to use, and we know that 4 entities will be released in each cycle by sending the output. Hence, if more than 8 FIFO entries are full, RejBounded sampling unit does not accept a new input from Keccak core by raising FULL flag. However, it has the required valid samples to provide the required output for the next cycle. | ||
| 1901 | - | ||
| 1902 | - | ||
| 1903 | -| Cycle count | Input from PISO | FIFO valid entries from previous cycle | Total valid samples | output | FIFO remaining for the next cycle | | ||
| 1904 | -| :---------- | :-------------- | :------------------------------------- | :------------------ | :----- | :-------------------------------- | | ||
| 1905 | -| 0 | 8 | 0 | 8 | 4 | 4 | | ||
| 1906 | -| 1 | 8 | 4 | 12 | 4 | 8 | | ||
| 1907 | -| 2 | 8 | 8 | 16 | 4 | 12 (FULL) | | ||
| 1908 | -| 3 | 0 | 12 | 12 | 4 | 8 | | ||
| 1909 | -| 4 | 8 | 8 | 16 | 4 | 12 (FULL) | | ||
| 1910 | -| 5 | 0 | 12 | 12 | 4 | 8 | | ||
| 1911 | -| 6 | 8 | 8 | 16 | 4 | 12 (FULL) | | ||
| 1912 | -| 7 | 0 | 12 | 12 | 4 | 8 | | ||
| 1913 | -| 8 | 7 | 8 | 15 | 4 | 11 (FULL) | | ||
| 1914 | -| 9 | 0 | 11 | 11 | 4 | 7 | | ||
| 1915 | -| 10 | 6 | 7 | 13 | 4 | 9 (FULL) | | ||
| 1916 | - | ||
| 1917 | - | ||
| 1918 | - | ||
| 1919 | - | ||
| 1920 | -4) PISO contains 1088/4=272 coefficients. If there is not FULL condition for reading from Keccak, all PISO data can be read in 34 cycles. This would be match with Keccak throughput that generates 56 coefficients per 12 cycles. To maximize the utilization factor of our hardware resources, Keccak core will check the PISO status. If PISO contains 8 coefficients or more (the required inputs for RejBounded sampling unit), EMPTY flag will not be set, and Keccak will wait until the next cycle. | ||
| 1921 | -5) The maximum number of FULL conditions is when there are no rejected coefficients for all inputs. In this case, after 2 cycles with 16 coefficients, there is one FULL condition. After 64 cycles, all 256 required coefficients are processed by RejBouned sampling unit. | ||
| 1922 | -6) To maximize the utilization factor of our hardware resources, Keccak core will check the PISO status. If PISO contains 8 coefficients or more (the required inputs for RejBounded sampling unit), EMPTY flag will not be set, and Keccak will wait until the next cycle. | ||
| 1923 | - | ||
| 1924 | - | ||
| 1925 | - | ||
| 1926 | -## SampleInBall architecture | ||
| 1927 | - | ||
| 1928 | -SampleInBall is a procedure that uses the SHAKE256 of a seed ρ to produce a random element of Bτ. The procedure uses the Fisher-Yates shuffle method. The signs of the nonzero entries of c are determined by the first 8 bytes of H(ρ), and the following bytes of H(ρ) are used to determine the locations of those nonzero entries. | ||
| 1929 | - | ||
| 1930 | -We propose an architecture to remove the cost of memory access from Keccak to SampleInBall, and from SampleInBall to NTT. This requires a specific pattern of coefficients for NTT that prevents excessive buffering or interference between them. It also lowers the rejection rate and speeds up SampleInBall while maintaining small and efficient architecture. | ||
| 1931 | - | ||
| 1932 | -High-level architecture is illustrated as follows: | ||
| 1933 | - | ||
| 1934 | - | ||
| 1935 | - | ||
| 1936 | -### Keccak interface to SampleInBall | ||
| 1937 | - | ||
| 1938 | -Keccak is used in SHAKE-256 configuration for SampleInBall operation. Hence, it will take the input seed with 256-bit and generates 1088-bit output after each round. | ||
| 1939 | - | ||
| 1940 | -The first τ bits (τ \= 60 in the case of ML-DSA-87) in the first 8 bytes of this random stream are interpreted as τ random sign bits si ∈ {0, 1}, i \= 0, . . . , τ − 1\. The remaining 64 − τ bits are discarded. | ||
| 1941 | - | ||
| 1942 | -The remaining random bits are used for sampling. Since each 8-bit is used for one sample, the first round of Keccak output provides (1088-64)/8=128 samples. The number of valid samples needed is 60\. Because this is a sampling operation that is non-deterministic, if more samples are required, Keccak will run again and produce 1088/8=136 additional samples. Hence, there are two paths for Keccak input. While the input seed can be set by controller for each new polynomial c, the loop path is used to rerun Keccak for completing the previous polynomial. | ||
| 1943 | - | ||
| 1944 | -SampleInBall cannot take all samples parallelly since it makes hardware architecture too costly and complex. Therefore, we propose a parallel-input serial-output (PISO) unit in between to store the Keccak output and feed SampleInBall unit sequentially. | ||
| 1945 | - | ||
| 1946 | -### SampleInBall | ||
| 1947 | - | ||
| 1948 | -This unit takes data from the output of SHAKE-256 stored in a PISO buffer. The required cycles for this unit are variable due to the non-deterministic pattern of sampling. But this operation can only be finished with 60 valid samples. | ||
| 1949 | - | ||
| 1950 | -In our optimized architecture, this unit works in parallel with the Keccak core. Therefore, the latency for Keccak sampling (for the second round and next) is absorbed within the latency for a concurrently running SampleInBall core. | ||
| 1951 | - | ||
| 1952 | -The NTT unit needs to take four coefficients per cycle. This implies that the output contains four samples per each address as follows: | ||
| 1953 | - | ||
| 1954 | - | ||
| 1955 | - | ||
| 1956 | -SampleInBall algorithm is as follows: | ||
| 1957 | -```cpp | ||
| 1958 | -1) Initialize c = c0 c1 . . . c255 = 0 0 . . . 0 | ||
| 1959 | -2) for i := 256 − τ to 255 | ||
| 1960 | -3) j ← {0, 1, . . . , i} | ||
| 1961 | -4) s ← {0, 1} | ||
| 1962 | -5) ci := cj | ||
| 1963 | -6) cj := (−1)s | ||
| 1964 | -7) return c | ||
| 1965 | -``` | ||
| 1966 | -SampleInBall includes three main operations: | ||
| 1967 | - | ||
| 1968 | -1) Check the validity of input samples respect to parameter i (line 3 of algorithm) | ||
| 1969 | -2) Store the sign s (line 4 of algorithm) | ||
| 1970 | -3) Shuffle the stored polynomial c respect to parameter i, j, and s (line 5 and 6 of algorithm) | ||
| 1971 | - | ||
| 1972 | -To recall, for ML-DSA-87 with τ \= 60, 60 valid samples are required. | ||
| 1973 | - | ||
| 1974 | -Validity check on the input sample depends on the iteration number i while a sample greater than i will be rejected. Hence, the probability of failure for each round would be: | ||
| 1975 | - | ||
| 1976 | - | ||
| 1977 | - | ||
| 1978 | -*Rejection rate for each round of SampleInBall operation* | ||
| 1979 | - | ||
| 1980 | -To reduce the failure probability and avoid any wait cycle in polynomial multiplication, 4 samples are fed into SampleInBall while only 1 of them will be passed to shuffling unit. This decision reduces the probability of failure to: | ||
| 1981 | - | ||
| 1982 | -\\(probability of having 4 rejected inputs=(rejection rate)^4\\) | ||
| 1983 | - | ||
| 1984 | -In the worst case scenario (the first iteration with i=196), the failure probability is: | ||
| 1985 | - | ||
| 1986 | -\\((0.23046)^4=0.00282\\) | ||
| 1987 | - | ||
| 1988 | -The unused coefficients will be processed in the next cycle when i increments. The architecture is as follows: | ||
| 1989 | - | ||
| 1990 | - | ||
| 1991 | - | ||
| 1992 | -*Sampling phase of SampleInBall architecture* | ||
| 1993 | - | ||
| 1994 | -The first 2 cycles is used to store the sign bits into the sign buffer. After that, each 32 bits of input will be divided into 4 samples. Each sample is compared to i and the first valid sample is passed into the shuffling step. | ||
| 1995 | - | ||
| 1996 | -Controller uses a counter to manage i value. The counter starts at 196 (for ML-DSA-87) and goes up after a valid coefficient is found. | ||
| 1997 | - | ||
| 1998 | -When a valid coefficient is found, valid flag will be set and the chosen sample (known by j), i, and s will be transferred to shuffling unit. Then, the counter is incremented, and the remaining samples will be compared to the new i value. | ||
| 1999 | - | ||
| 2000 | -The architecture of shuffling unit is as follows: | ||
| 2001 | - | ||
| 2002 | - | ||
| 2003 | - | ||
| 2004 | -*Shuffling phase of SampleInBall architecture* | ||
| 2005 | - | ||
| 2006 | -A polynomial c is stored in a memory that has four coefficients for each address. This pattern is needed for NTT operation that works on the output of SampleInBall. The memory has two ports that can read or write data. | ||
| 2007 | - | ||
| 2008 | -Each input sample needs two cycles. In the first cycle, the memory reads the two addresses that have i and j, and in the second cycle, the memory saves the new coefficients. | ||
| 2009 | - | ||
| 2010 | -The read data from address j will be updated with 1 or q-1 based on the s value, while the original value of j is transferred to address i using a multiplexer and demultiplexer. | ||
| 2011 | - | ||
| 2012 | -When i and j have the same address, both ports try to write to the same location in the second cycle. To avoid this, the red path is used to turn off port a for address j. But then, j will be changed in the same buffer that has i (port b) and will be saved into memory. | ||
| 2013 | - | ||
| 2014 | -## Decompose Architecture | ||
| 2015 | - | ||
| 2016 | -Decompose unit is used in signing operation of Dilithium. It decomposes r into (r1,r0) such that r ≡ r1(2γ2)+r0 mod q. The output of decompose has two parts. While r0 will be stored into memory, r1 will be encoded and then be stored into Keccak SIPO input buffer to run SHAKE256. | ||
| 2017 | - | ||
| 2018 | - | ||
| 2019 | - | ||
| 2020 | -There are k polynomials (k=8 for ML-DSA-87) that needs to be decomposed as follows: | ||
| 2021 | - | ||
| 2022 | -\\[ | ||
| 2023 | -w= | ||
| 2024 | -\begin{bmatrix} | ||
| 2025 | -w_0 \\ | ||
| 2026 | -\vdots \\ | ||
| 2027 | -w_{k-1} | ||
| 2028 | -\end{bmatrix} | ||
| 2029 | -\\] | ||
| 2030 | - | ||
| 2031 | -Due to our memory configuration that stores 4 coefficients per address, we need 4 parallel cores for decompose and encode units to match the throughout between these modules. | ||
| 2032 | - | ||
| 2033 | - | ||
| 2034 | - | ||
| 2035 | - | ||
| 2036 | -Decompose algorithm plays a crucial role by breaking down the coefficients of a polynomial into smaller parts. Decompose calculates high and low bits r1 and r0 such that: | ||
| 2037 | - | ||
| 2038 | -\\[ | ||
| 2039 | -r = r_1 · 2 γ_2 + r_0 {mod} q | ||
| 2040 | -\\] | ||
| 2041 | - | ||
| 2042 | -where: | ||
| 2043 | - | ||
| 2044 | -\\[ | ||
| 2045 | --γ2 < r0 \leq γ2 | ||
| 2046 | -\\] | ||
| 2047 | - | ||
| 2048 | -except for the border case when r \- r0=q – 1. In the border case, the high bits r1 are made zero, and the low bits r0 are reduced by one. | ||
| 2049 | - | ||
| 2050 | -**Definition:** | ||
| 2051 | - | ||
| 2052 | -* mod α: If α is a positive integer and m ∈ Z or m ∈ Zα, then m mod α denotes the unique element m ′∈ Z in the range 0 ≤ m ′ \< α such that m and m ′ are congruent modulo α. | ||
| 2053 | -* mod± α: If α is a positive integer and m ∈ Z or m ∈ Zα, then m mod± α denotes the unique element m ′∈ Z in the range −α/2 \< m ′ ≤ α/2 such that m and m ′ are congruent modulo α. | ||
| 2054 | - | ||
| 2055 | -High-level architecture is illustrated as follows: | ||
| 2056 | - | ||
| 2057 | - | ||
| 2058 | - | ||
| 2059 | -The modular reduction architecture is as follows: | ||
| 2060 | - | ||
| 2061 | -  | ||
| 2062 | - | ||
| 2063 | -| r0 mod 22 down limit | r0 mod 22 Up limit | r0 | | ||
| 2064 | -| :------------------: | :----------------: | :-----------------------: | | ||
| 2065 | -| 0 | γ2 | r0 mod 2 γ2 | | ||
| 2066 | -| γ2\+1 | 2γ2\-1 | (r0 mod 2 γ2) \+ (q-2 γ2) | | ||
| 2067 | - | ||
| 2068 | - | ||
| 2069 | -Our suggested design calculates two shares of r0 and r1 at the same time. We use a lookup table with 16 parallel comparisons to find the value of r1 from r based on the following graph: | ||
| 2070 | - | ||
| 2071 | - | ||
| 2072 | - | ||
| 2073 | -*r1 value based on the given r* | ||
| 2074 | - | ||
| 2075 | -| r down limit | r Up limit | r1 | | ||
| 2076 | -| :----------: | :--------: | :-: | | ||
| 2077 | -| 0 | γ2 | 0 | | ||
| 2078 | -| γ2\+1 | 3γ2 | 1 | | ||
| 2079 | -| 3γ2\+1 | 5γ2 | 2 | | ||
| 2080 | -| 5γ2\+1 | 7γ2 | 3 | | ||
| 2081 | -| 7γ2\+1 | 9γ2 | 4 | | ||
| 2082 | -| 9γ2\+1 | 11γ2 | 5 | | ||
| 2083 | -| 11γ2\+1 | 13γ2 | 6 | | ||
| 2084 | -| 13γ2\+1 | 15γ2 | 7 | | ||
| 2085 | -| 15γ2\+1 | 17γ2 | 8 | | ||
| 2086 | -| 17γ2\+1 | 19γ2 | 9 | | ||
| 2087 | -| 19γ2\+1 | 21γ2 | 10 | | ||
| 2088 | -| 21γ2\+1 | 23γ2 | 11 | | ||
| 2089 | -| 23γ2\+1 | 25γ2 | 12 | | ||
| 2090 | -| 25γ2\+1 | 27γ2 | 13 | | ||
| 2091 | -| 27γ2\+1 | 29γ2 | 14 | | ||
| 2092 | -| 29γ2\+1 | 31γ2 | 15 | | ||
| 2093 | -| 31γ2\+1 | q-1 | 0 | | ||
| 2094 | - | ||
| 2095 | - | ||
| 2096 | -To compute r0 mod± 2γ2, at the same time with r1 computation, a modular reduction operation will be applied to the input value r with respect to 2γ2 to compute r0 mod 2γ2. The result can be mapped into mod± 2γ2 range by subtracting 2γ2 when the result is greater than γ2. However, at the end all shares should be modulus q. For that, instead of subtracting 2γ2, we perform an addition with q-2γ2 to the results. | ||
| 2097 | - | ||
| 2098 | -The expected r0 for different values of r is illustrated as follows: | ||
| 2099 | - | ||
| 2100 | - | ||
| 2101 | - | ||
| 2102 | -*r0 value based on the given r (without considering boarder case)* | ||
| 2103 | - | ||
| 2104 | -Using this technique, we could achieve r0 and r1 for all cases expect the border case where r \- r0=q – 1. This case can be detected inside r1 decompose architecture shown by red. In this case, the lookup table sets the value of 0 for r1, while r1 will be set as follows: | ||
| 2105 | - | ||
| 2106 | -r0=r0-1=r-q+1-1=r-q≡r mod q | ||
| 2107 | - | ||
| 2108 | - | ||
| 2109 | - | ||
| 2110 | -*r0 value based on the given r considering boarder case* | ||
| 2111 | - | ||
| 2112 | -### Performance of Decompose | ||
| 2113 | - | ||
| 2114 | -There are k polynomials with 256 coefficients for each that need to be fed into decompose unit in pipeline method. After having 1088-bit input into SIPO, Keccak will be enabled parallel with decompose and encode units. However, the last round of Keccak will be performed after processing all coefficients. Each round of Keccak takes 12 cycles which allows processing of 48 coefficients. Since the output length of each encode unit is 4 bits, Keccak works faster than decompose/encode units and SIPO will not have overflow issue. | ||
| 2115 | - | ||
| 2116 | -For a complete decompose/encode/hash operation for Dilithium ML-DSA-87 with 8 polynomials, 8\*256/4 \+ 12 \= 524 cycles are required using pipelined architecture. | ||
| 2117 | - | ||
| 2118 | -## MakeHint Architecture | ||
| 2119 | - | ||
| 2120 | -The basic approach of the MakeHint(z, r) function involves decomposing both r and r+z into two parts: (r1, r0) for r and (rz1, rz0) for r+z. It then proceeds to evaluate whether r1 and rz1 are identical. In the event that r1 does not match rz1, it indicates that a hint is necessary to proceed. This process is essential for determining when additional information is required to resolve discrepancies between the compared segments. | ||
| 2121 | - | ||
| 2122 | -However, decompose function is expensive on hardware to be implemented. Furthermore, performing a sequential decompose function using a shared hardware resource requires more latency. | ||
| 2123 | - | ||
| 2124 | -The process of implementing the decompose function is notably resource-intensive and can incur significant costs when executed on hardware. Additionally, the sequential execution of this function, particularly when it relies on a common hardware resource, tends to introduce increased latency. This is due to the fact that shared resources often necessitate additional time to manage concurrent operations, which can result in delays and reduced efficiency. | ||
| 2125 | - | ||
| 2126 | -The following architecture shows Dilithium algorithm to compute h=MakeHint(−ct0, w − cs2 \+ ct0). There are several decompose operations embedded into HighBits, LowBits, and MakeHint functions, shown by red. | ||
| 2127 | - | ||
| 2128 | - | ||
| 2129 | - | ||
| 2130 | -As an alternative and more efficient way, we can use a method to realize where hint needs to be generated as follows: | ||
| 2131 | - | ||
| 2132 | -To compute h=MakeHint(−ct0, w − cs2 \+ ct0), first note is that instead of computing (r1, r0) \= Decomposeq (w−cs2, α) and checking whether ‖r0‖\<2 \- β and r1 \= w1, it is equivalent to just check that ‖w0-cs2‖\<2\-β, where w0 is the low part of w. If this check passes, w0 − cs2 is the low part of w − cs2. Next, recall that by the definition of the MakeHint function, a coefficient of a polynomial in h as computed is non-zero precisely if the high parts of the corresponding coefficients of w − cs2 and w − cs2 \+ ct0 differ. Now, we have already computed the full decomposition w \= αw1 \+ w0 of w, and we know that αw1 \+ (w0 −cs2) is the correct decomposition of w−cs2. But then, αw1 \+ (w0 −cs2 \+ct0) is the correct decomposition of w − cs2 \+ ct0 (i.e. the high part is w1) if and only if each coefficient of w0 − cs2 \+ ct0 lies in the interval (−γ2, γ2\], or, when some coefficient is −γ2 and the corresponding coefficient of w1 is zero. The last condition is due to the border case in the Decompose function. On the other hand, if these conditions are not true, then the high parts must differ, and it then follows that for computing the hint vector h it suffices to just check these conditions on the coefficients of w0 − cs2 \+ ct0. This algorithm is shown as follows: | ||
| 2133 | - | ||
| 2134 | - | ||
| 2135 | - | ||
| 2136 | -The alternative algorithm reduces the decompose cost by modifying the MakeHint to enhance the efficiency of the architecture. We propose efficient architecture for performing the alternative MakeHint operation on hardware platform and accelerate this operation using a pipeline architecture. | ||
| 2137 | - | ||
| 2138 | -High-level architecture is illustrated as follows: | ||
| 2139 | - | ||
| 2140 | - | ||
| 2141 | - | ||
| 2142 | -### Hint Sum and Hint BitPack | ||
| 2143 | - | ||
| 2144 | -In Dilithium signing algorithm, the output of Makehint (hint output) is further processed to generate the encoded ‘h’ component of the signature. Additionally, one of the validity checks in signing algorithm uses hint sum to determine validity of the generated signature. These post-processing steps can be embedded into the Makehint architecture to avoid latency overhead while maintaining low complexity. The following figure shows the embedded logic into Makehint to generate the required outputs. | ||
| 2145 | - | ||
| 2146 | - | ||
| 2147 | - | ||
| 2148 | -Hint Sum: | ||
| 2149 | - | ||
| 2150 | -In the pipelined architecture, as 4 hints are generated every cycle, they are accumulated every cycle for all 8 polynomials. | ||
| 2151 | - | ||
| 2152 | -{if hintsum\> ω invalid\_h=1 else invalid\_h=0 | ||
| 2153 | - | ||
| 2154 | -Hint BitPack: | ||
| 2155 | - | ||
| 2156 | -The output of hint bitpack is a byte string ‘y’ of which \[ω\-1:0\] bytes are the indices at which the generated hint is non-zero. \[ω\+k-1 : ω\] bytes are the total number of indices per polynomial at which the hint is non-zero. If the number of non-zero hints is \< ω, the rest of the entries of y are filled with 0s. If the number of non-zero hints is \> ω, Makehint flow continues for the remaining coefficients and the ‘y’ array is overwritten with the subsequent values. In this case, the ‘h’ component is invalid and the signature is discarded. | ||
| 2157 | - | ||
| 2158 | -The following table shows an example of construction of y array per polynomial based on generated hints. | ||
| 2159 | - | ||
| 2160 | -| Polynomial | Hint\[3:0\] | Index\[3:0\]\[7:0\] | y\[ω\-1:0\] | | ||
| 2161 | -| :--------- | :---------- | :------------------ | :------------------------------ | | ||
| 2162 | -| 0 | 1-1-0-0 | 3-2-1-0 | 3-2 | | ||
| 2163 | -| 0 | 0-1-0-1 | 7-6-5-4 | 6-4-3-2 | | ||
| 2164 | -| 0 | 0-0-1-0 | 11-10-9-8 | 9-6-4-3-2 | | ||
| 2165 | -| … | … | … | …-9-6-4-3-2 | | ||
| 2166 | -| 1 | 1-1-1-0 | 3-2-1-0 | 3-2-1-…-9-6-4-3-2 | | ||
| 2167 | -| 1 | 0-1-1-0 | 7-6-5-4 | 6-5-3-2-1-…-9-6-4-3-2 | | ||
| 2168 | -| … | … | … | …-6-5-3-2-1-…-9-6-4-3-2 | | ||
| 2169 | -| 2 | 0-0-0-0 | 3-2-1-0 | …-6-5-3-2-1-…-9-6-4-3-2 | | ||
| 2170 | -| 2 | 0-0-0-1 | 7-6-5-4 | 4-…-6-5-3-2-1-…-9-6-4-3-2 | | ||
| 2171 | -| 2 | 1-1-0-0 | 11-10-9-8 | 11-10-4-…-6-5-3-2-1-…-9-6-4-3-2 | | ||
| 2172 | -| … | … | … | … | | ||
| 2173 | - | ||
| 2174 | - | ||
| 2175 | -To optimize area, 1 dword of ‘y’ buffer is written directly to the register API. The buffer generates a valid signal after accumulating 1 dword worth of data which can be used as a write enable for the register API. To protect the signature from intermittent firmware reads, the signature register is lockable. The lock is asserted during signing flow and is only unlocked after the entire flow has been completed. | ||
| 2176 | - | ||
| 2177 | -At the end of all polynomials, the hintsum is written to the register API to construct the y\[ω\+k-1:ω\] locations of the byte string. | ||
| 2178 | - | ||
| 2179 | -It is possible that during the last cycle of the last polynomial, the index buffer contains \< 1 dword of index values to be written to the reg API. To accommodate this scenario, the controller flushes out the buffer at the end of the last polynomial and writes the remaining data to the register API. | ||
| 2180 | - | ||
| 2181 | -## W1Encode Architecture | ||
| 2182 | - | ||
| 2183 | -The signer’s commitment is shown by w, while this value needs to be decomposed into two shares to provide the required hint as a part of signature. The output of decompose is shown by (w1, w0) which presents the higher and lower parts of the given input. While w0 can be stored into the memory, the value of w1 is required to compute commitment hash using SHAKE256 operation. The following equation shows this operation: | ||
| 2184 | - | ||
| 2185 | -c=H(μ||w1Encodew1) | ||
| 2186 | - | ||
| 2187 | -Where is a 512-bit value computed based on the message and || means the concatenation between these two parts. | ||
| 2188 | - | ||
| 2189 | -In ML-DSA-87 algorithm, there are 8 polynomials for w shown by w0 to w7. Furthermore, higher parts of each coefficient of these polynomials, shown by w1, is a value in \[0:15\] range that can be presented by 4 bits. Based on this, the total input size for performing SHAKE256 is: | ||
| 2190 | - | ||
| 2191 | -inputsize=512size of μ+8poly number\*256coeff per poly\*4higher bit per coeff=8,704 bits | ||
| 2192 | - | ||
| 2193 | -Since SHAKE256 takes only 1088 bits per each round, we have to feed these values sequentially. However, due to the prefix value of , and also the SHAKE256 input size does not divide evenly by each polynomial w1 size (which is 256\*4=1024 bits), the pattern of feeding decompose results into hashing buffer is challenging. | ||
| 2194 | - | ||
| 2195 | -There are k polynomials (k=8 for ML-DSA-87) that needs to be decomposed as follows: | ||
| 2196 | - | ||
| 2197 | -\\[ | ||
| 2198 | -w= | ||
| 2199 | -\begin{bmatrix} | ||
| 2200 | -w_0 \\ | ||
| 2201 | -\vdots \\ | ||
| 2202 | -w_{k-1} | ||
| 2203 | -\end{bmatrix} | ||
| 2204 | -\\] | ||
| 2205 | - | ||
| 2206 | -Due to our memory configuration that stores 4 coefficients per address, we need 4 parallel cores for decompose and encode units to match the throughout between these modules. | ||
| 2207 | - | ||
| 2208 | - | ||
| 2209 | - | ||
| 2210 | -To optimize the performance and remove the cost of memory, we use a pipeline architecture for encode that processes the input values and feed them into Keccak buffer. The following figure shows the optimized architecture for W1Encoder. | ||
| 2211 | - | ||
| 2212 | - | ||
| 2213 | - | ||
| 2214 | -In the suggested design, every cycle, 4 coefficients for w1 are calculated from the decompose unit and then sent to the encode unit. Each coefficient is represented by 4 bits, making a total of 16 bits. However, the Keccak buffer only accepts input in 64-bit chunks. Therefore, a shift register is used to store the coefficients and pass a 64-bit chunk every 4 cycles to the Keccak SIPO buffer. An internal counter is used to control when the Keccak SIPO buffer takes this 64-bit chunk every 4 cycles. | ||
| 2215 | - | ||
| 2216 | -Meanwhile, Keccak SIPO buffer can store 1088 bits of data and then activate Keccak to process it. The internal counter counts the number of writes on Keccak SIPO, and when it reaches 17 (17\*64 \= 1088 bits), Keccak enable is triggered. Because of Keccak architecture, SIPO can keep buffering a new input while Keccak works on the previous stored data. | ||
| 2217 | - | ||
| 2218 | -The very first iteration of Keccak contains a 512-bit value shown by , which the high-level controller puts in Keccak SIPO buffer before decompose/encode process. So, only 576 bits of SIPO are left for encoding output. We suggest starting with a counter value of 8 to deal with this edge case in the first Keccak round. The other rounds have 17 SIPO write enable. | ||
| 2219 | - | ||
| 2220 | -The following figure shows the counter architecture. The first two bits is used to enable SIPO buffer, while the remaining bits of \[6:2\] is used to enable Keccak process. | ||
| 2221 | - | ||
| 2222 | - | ||
| 2223 | - | ||
| 2224 | -The following table reports the SIPO input for different Keccak rounds. | ||
| 2225 | - | ||
| 2226 | -| Keccak SHAKE256 Round | Buffer input | Bits | | ||
| 2227 | -| :-------------------- | :------------ | :--- | | ||
| 2228 | -| 1 | μ | 512 | | ||
| 2229 | -|| w0\[143:0\] | 576 | | ||
| 2230 | -| 2 | w0\[255:144\] | 448 | | ||
| 2231 | -|| w1\[159:0\] | 640 | | ||
| 2232 | -| 3 | w1\[255:160\] | 384 | | ||
| 2233 | -|| w2\[175:0\] | 704 | | ||
| 2234 | -| 4 | w2\[255:176\] | 320 | | ||
| 2235 | -|| w3\[191:0\] | 768 | | ||
| 2236 | -| 5 | w3\[255:192\] | 256 | | ||
| 2237 | -|| w4\[207:0\] | 832 | | ||
| 2238 | -| 6 | w4\[255:208\] | 192 | | ||
| 2239 | -|| w5\[223:0\] | 896 | | ||
| 2240 | -| 7 | w5\[255:224\] | 128 | | ||
| 2241 | -|| w6\[239:0\] | 960 | | ||
| 2242 | -| 8 | w6\[255:240\] | 64 | | ||
| 2243 | -|| w7\[255:0\] | 1024 | | ||
| 2244 | -| 9 | padding | 1088 | | ||
| 2245 | - | ||
| 2246 | - | ||
| 2247 | -When the whole polynomials are done in the first 8 rounds of Keccak and Keccak done signal is asserted, the encode done signal is asserted and the high-level controller resumes control and adds the necessary padding to SIPO to finish the SHAKE256 process. | ||
| 2248 | - | ||
| 2249 | -## Norm Check Architecture | ||
| 2250 | - | ||
| 2251 | -The figure provided illustrates the finite field range for polynomial coefficients. It indicates that each coefficient is an integer ranging from 0 to q-1: | ||
| 2252 | - | ||
| 2253 | - | ||
| 2254 | - | ||
| 2255 | -The infinity norm is defined as follows: | ||
| 2256 | - | ||
| 2257 | -For an element w ∈ Z , \\(∥w∥∞ = |w|\\), the absolute value of w. For an element \\(w ∈ Z_q\\),\\(∥w∥∞ = w mod^ ± q\\) . For an element *w* of *R* or *Rq*, \\(∥w∥∞ = max0≤i<256 ∥wi∥∞\\) . For a length-*m* vector w with entries from *R* or *Rq*, \\(∥w∥∞ = max0≤i<m ∥w[i]∥∞\\) . | ||
| 2258 | - | ||
| 2259 | -In the context of norm definition within a finite field, when a value for the bound is provided, the norm check determines whether the coefficient falls below the bound or exceeds the q-bound, which is highlighted in red in the following figure. | ||
| 2260 | - | ||
| 2261 | - | ||
| 2262 | - | ||
| 2263 | -There are three different validity checks with different bounds during signing operations as follows: | ||
| 2264 | - | ||
| 2265 | -1) \\[ |(|z|)|_∞ ≥ γ1 -β \\] | ||
| 2266 | -2) \\[ |(|r0|)|_∞ ≥ γ2 -β \\] | ||
| 2267 | -3) \\[ |⟨⟨ct0⟩⟩|_∞ ≥ γ2 \\] | ||
| 2268 | - | ||
| 2269 | -Vector z contains l polynomials (l=7 for ML-DSA-87) and r0 and ct0 contains k polynomials (k=8 for ML-DSA-87) that needs to be evaluated by norm check operation. | ||
| 2270 | - | ||
| 2271 | -Due to our memory configuration that stores 4 coefficients per address, we need 4 parallel cores for norm check unit to match the throughput between these modules. To optimize the performance and remove the cost of memory, we use a pipeline architecture for norm check that processes the input values. | ||
| 2272 | - | ||
| 2273 | - | ||
| 2274 | - | ||
| 2275 | -In the proposed design, during each cycle, 4 norm check coefficients are computed from stored data. This provides a performance improvement since this block only needs to read from memory and does not perform any writes to memory. Every coefficient is expressed using 24 bits, culminating in a combined total of 96 bits. A norm check is executed on each of these coefficients to produce a invalid output. The invalid outputs for all coefficients across all polynomials must be collectively ORed to yield the ultimate INVALID signal. This INVALID signal is asserted when any coefficient fails to meet the predetermined norm check criteria within the specified bound. | ||
| 2276 | - | ||
| 2277 | -The proposed design is configurable and accepts different bounds to reduce the required hardware resources. The following table shows the latency requirements for these three norm checks. | ||
| 2278 | - | ||
| 2279 | -| Input polynomials | Number of polynomials | Total coefficients | Latency for ML-DSA-87 | | ||
| 2280 | -| :---------------- | :-------------------- | :----------------- | :-------------------- | | ||
| 2281 | -| z | L | L\*256 | 448 (for 4\) | | ||
| 2282 | -| r0 | K | K\*256 | 512 (for 4\) | | ||
| 2283 | -| ct0 | k | K\*256 | 512 (for 4\) | | ||
| 2284 | - | ||
| 2285 | - | ||
| 2286 | -## skDecode Architecture | ||
| 2287 | - | ||
| 2288 | -The given sk to the core for performing a signing operation has been encoded, and skDecode is responsible to reverse the encoding procedure to divide sk to the appropriate portions. The initial segments within sk should be allocated to variables p, K, and tr, corresponding to sizes of 256 bits, 256 bits, and 512 bits, respectively, without necessitating any modifications. | ||
| 2289 | - | ||
| 2290 | -The remaining part of sk stores the packed form of s1, s2, and t0, respectively. For s1 and s2, each coefficient is represented by η bits and needs to be unpacked as follows: | ||
| 2291 | - | ||
| 2292 | -coefficient \= η – data\[η\_size-1:0\] | ||
| 2293 | - | ||
| 2294 | -where η\_size \= bitlen(2\*η). | ||
| 2295 | - | ||
| 2296 | -For t0, each coefficient is represented by d bits and needs to be unpacked as follows: | ||
| 2297 | - | ||
| 2298 | -coefficient \= 2d-1 – data\[d-1:0\] | ||
| 2299 | - | ||
| 2300 | -| sk part | poly size | coeff size | Total size | Latency for ML-DSA-87 | | ||
| 2301 | -| :------ | :-------- | :--------- | :-------------------------------- | :---------------------------------------------------------------------- | | ||
| 2302 | -| s1 | l=7 | η\_size=3 | l\*256\*η\_size=7\*256\*3= 5376 | 224 cycles | | ||
| 2303 | -| s2 | k=8 | η\_size=3 | k\*256\*η\_size \=8\*256\*3= 6144 | 256 cycles | | ||
| 2304 | -| t0 | K=8 | d=13 | k\*256\*d=8\*256\*13= 26624 | 256 cycles (using 8 parallel cores) 512 cycles (using 4 parallel cores) | | ||
| 2305 | - | ||
| 2306 | - | ||
| 2307 | -The skDecode architecture reads 8 values from the register API, based on the memory pattern that has 4 coefficients for each address. It then maps them to modulo q value using the given equation. Then it stores the mapped value in the memory with two parallel write operations. | ||
| 2308 | - | ||
| 2309 | -The high-level architecture for skDecode is as follows: | ||
| 2310 | - | ||
| 2311 | - | ||
| 2312 | - | ||
| 2313 | -For s1 and s2 unpacking, the decode architecture is as follows: | ||
| 2314 | - | ||
| 2315 | - | ||
| 2316 | - | ||
| 2317 | -In case a\[2:0\] is greater than ‘h4, the sk is considered out of range. skDecode block triggers an error interrupt to the RV core and the algorithm is aborted. | ||
| 2318 | - | ||
| 2319 | -For t0 unpacking, the decode architecture is shown below: | ||
| 2320 | - | ||
| 2321 | - | ||
| 2322 | - | ||
| 2323 | -Since key sizes are large, a key memory is used to interface with FW and skDecode module to avoid routing and timing issues. Assuming a memory interface of two 32-bit RW ports, s1s2 unpacking can be done with 8 parallel cores. This requires 24-bits per cycle to be processed which can be accommodated with a single key memory read per cycle (32-bits) and accumulating remaining bits in a sample buffer. Once next read occurs, bits are appended to the previous ones and the values are fed from buffer to the unpack module. | ||
| 2324 | - | ||
| 2325 | -In case of t0 unpacking, since 13-bits are required per core, 4 parallel cores can be used instead of 8 to support the 32-bit memory interface. Two memory reads are done per cycle (64-bits) and 52 bits are processed per cycle (13\*4). Remaining bits are accumulated in the sample buffer and read out. | ||
| 2326 | - | ||
| 2327 | -The s1/s2 buffer can hold up to 32+24 bits of data. To avoid data conflict within s1/s2 buffer, the following memory access pattern is used: | ||
| 2328 | - | ||
| 2329 | -S1, s2 unpack: | ||
| 2330 | - | ||
| 2331 | -Cycle 0 🡪 read 1 addr (buffer \= 32 bits) | ||
| 2332 | - | ||
| 2333 | -Cycle 1 🡪 read 1 addr (buffer \= 32 \+ 8 bits) | ||
| 2334 | - | ||
| 2335 | -Cycle 2 🡪 read 1 addr (buffer \= 32 \+ 16 bits) | ||
| 2336 | - | ||
| 2337 | -Cycle 3 🡪 stall and read buffer contents (24 bits) | ||
| 2338 | - | ||
| 2339 | -T0 unpack: | ||
| 2340 | - | ||
| 2341 | -In case of t0 unpack, the t0 sample buffer can hold up to 64+52 \= 116 bits of data. The buffer generates a full signal that is used to stall key memory reads for a cycle before continuing to write to the buffer. | ||
| 2342 | - | ||
| 2343 | -## sigEncode\_z Architecture | ||
| 2344 | - | ||
| 2345 | -The sigEncode\_z operation converts a signature into a sequence of bytes. This operation has three distinct parts, namely c, z, and h. The first part simply writes the c into the register API as it is. The last part also uses the MakeHint structure to combine the MakeHint outputs into register API. However, the middle part, that is z, requires encoding. | ||
| 2346 | - | ||
| 2347 | -Every coefficient of z is between \[-γ1+1, γ1\], but its value mod q is kept in memory. To encode it, this equation is needed on the non-modular value: | ||
| 2348 | - | ||
| 2349 | -Encoded z \= γ1 – z | ||
| 2350 | - | ||
| 2351 | -The high-level architecture processes each coefficient of z in this way: | ||
| 2352 | - | ||
| 2353 | - | ||
| 2354 | - | ||
| 2355 | -The modular and non-modular value are equal when the z is in the interval \[0, γ1\]. The first branch in this architecture shows this. But for the negative range, we need to remove q from the difference results. In this case, we get γ1 – (z mod q) \= γ1 – (q \+ z) \= γ1 – z – q. So, the second branch adds q to the result to finish the encoding. | ||
| 2356 | - | ||
| 2357 | -Using two parallel read ports, 8 encoding units read 8 coefficients from the memory and write the encoded values to the register API as follows: | ||
| 2358 | - | ||
| 2359 | - | ||
| 2360 | - | ||
| 2361 | -## Power2Round Architecture | ||
| 2362 | - | ||
| 2363 | -Power2Round function is used to split each coefficient of vector t to two parts (similar to decompose unit). Power2Round calculates high and low bits r1 and r0 such that: | ||
| 2364 | - | ||
| 2365 | -r \= r1 · 2d \+r0 mod q | ||
| 2366 | - | ||
| 2367 | -where: | ||
| 2368 | - | ||
| 2369 | -\\(-2^(d-1)<r_0≤2^(d-1)\\) | ||
| 2370 | - | ||
| 2371 | -**Definition:** | ||
| 2372 | - | ||
| 2373 | -* mod α: If α is a positive integer and m ∈ Z or m ∈ Zα, then m mod α denotes the unique element m ′∈ Z in the range 0 ≤ m ′ \< α such that m and m ′ are congruent modulo α. | ||
| 2374 | -* mod± α: If α is a positive integer and m ∈ Z or m ∈ Zα, then m mod± α denotes the unique element m ′∈ Z in the range −α/2 \< m ′ ≤ α/2 such that m and m ′ are congruent modulo α. | ||
| 2375 | - | ||
| 2376 | -The power2round process yields two outputs, t0 and t1. The value of t0 must be processed using skEncode and then placed in the API register. Meanwhile, t1 is to be processed with pkEncode and then fed into the register API. This is depicted in the high-level architecture diagram. | ||
| 2377 | - | ||
| 2378 | - | ||
| 2379 | - | ||
| 2380 | -The goal is to create a pipeline architecture for skEncode and pkEncode that minimizes memory overhead costs. Therefore, these operations will be executed simultaneously with power2round, and the outcomes will be directly stored into the API. | ||
| 2381 | - | ||
| 2382 | -Power2Round reads 2 addresses of memory containing 8 coefficients. | ||
| 2383 | - | ||
| 2384 | -The expected r1 and r0 for different values of given r is illustrated as follows: | ||
| 2385 | - | ||
| 2386 | - | ||
| 2387 | - | ||
| 2388 | - | ||
| 2389 | - | ||
| 2390 | -The diagram illustrates the structure of the power2round mechanism integrated with the skEncode arrangement. However, pkEncode is the process of saving the t1 values into the register API. | ||
| 2391 | - | ||
| 2392 | - | ||
| 2393 | - | ||
| 2394 | -## skEncode Architecture | ||
| 2395 | - | ||
| 2396 | -The SkEncode operation requires multiple inputs (skEncode(ρ, K, tr, s1, s2, t0)). But ρ, K, tr, and t0 have been preloaded into the API through different operations. In terms of s1 and s2, SkEncode serves as a conversion tool that maps the values of these coefficients using the following equation: | ||
| 2397 | - | ||
| 2398 | -data\[η\_size-1:0\] \= η – coefficient | ||
| 2399 | - | ||
| 2400 | -For ML-DSA-87 with η=2, there are only 5 possible values for the s1 and s2 coefficients, and the following architecture converts their modular presentation into the packed format: | ||
| 2401 | - | ||
| 2402 | - | ||
| 2403 | - | ||
| 2404 | -## pkDecode Architecture | ||
| 2405 | - | ||
| 2406 | -During the verification process, the provided pk must be decoded. The initial 256 bits of pk include ρ exactly as it is. The bits that follow consist of t1 polynomials. According to ML-DSA-87 protocol, each set of 10 bits represents a single coefficient. Therefore, these 10 bits need to be read, shifted left by 13 bits, and the outcome should be saved into memory. | ||
| 2407 | - | ||
| 2408 | -The architecture is as follows: | ||
| 2409 | - | ||
| 2410 | - | ||
| 2411 | - | ||
| 2412 | -## sigDecode\_z Architecture | ||
| 2413 | - | ||
| 2414 | -The sigDecode operation reverses the sigEncode. This operation has three distinct parts, namely c, z, and h. The first part simply writes the c from the register API as it is. The last part also uses the HintBitUnpack structure to combine the MakeHint outputs into register API. However, the middle part, that is z, requires decoding. | ||
| 2415 | - | ||
| 2416 | -Every coefficient of z is presented by 20 bits, but its value mod q is required to be stored into memory. To decode it, this equation is needed: | ||
| 2417 | - | ||
| 2418 | -Decoded z \= γ1 – z | ||
| 2419 | - | ||
| 2420 | -However, because the decoded value falls within \[-γ1+1, γ1\], we must convert it to its equivalent modular q value. | ||
| 2421 | - | ||
| 2422 | -The high-level architecture is as follows: | ||
| 2423 | - | ||
| 2424 | - | ||
| 2425 | - | ||
| 2426 | -## sigDecode\_h Architecture | ||
| 2427 | - | ||
| 2428 | -The sigDecode function reverses sigEncode and is composed of three separate segments: c, z, and h. The h part uses the HintBitUnpack structure to decode given Hint and store it into memory. | ||
| 2429 | - | ||
| 2430 | -We must reconstruct k polynomials (with k being 8 in the case of ML-DSA-87) using the decoding process provided. The total number of non-zero indices of each polynomial can be found in the range of bytes \[ω: ω+k-1\] (where ω is set to 75 for ML-DAS-87). Therefore, the initial step to reconstruct each hi involves reading the byte at position ω+i for each polynomial (where 0≤i\<k), shown by HINTSUM\_i. | ||
| 2431 | - | ||
| 2432 | -HINTSUM\_i indicates how many bytes to read from \[ω\-1:0\] byte range for the current polynomial from the register API. To keep the API constant and avoid any complexity in storing hints for the next polynomial, the decode module always reads 4 bytes from the register API and an internal vector, current polynomial map (curr\_poly\_map), is used to indicate which of the 4 bytes belongs to the current polynomial. For example, if the HINTSUM is 3, the curr\_poly\_map is updated to 0-1-1-1 to indicate that bytes \[2:0\] are valid. Byte\[3\] is processed as part of the next polynomial. Once the required bytes are identified, a 256-bit vector is updated with 1s in the positions indicated by these input bytes. After the first cycle, the first 4 bits of the bitmap are ready to be written to the memory. | ||
| 2433 | - | ||
| 2434 | -To keep the throughput as storing 4 coefficients per cycle into internal memory, hints are processed every cycle and the bitmap is updated every cycle. To store data into memory, each coefficient, which might either be a 0 or a 1, is represented using 24 bits. | ||
| 2435 | - | ||
| 2436 | -Since a non-zero hint can occur in any position of the 256-bit vector, it takes 64 cycles (4 coeffs/cycle) to write all 256 coefficients to memory irrespective of the value of the coefficient. For example, if the last 1 recorded is in index 35, the decode module continues to write the rest of the coefficients (36, 37, etc) to memory. | ||
| 2437 | - | ||
| 2438 | - | ||
| 2439 | - | ||
| 2440 | -Example hint processing: | ||
| 2441 | - | ||
| 2442 | -| Cycle | Polynomial | Hintsum | Hintsum\_curr | Remaining hintsum | Byte select of reg API | Curr\_poly\_map | | ||
| 2443 | -| :----- | :--------- | :------ | :------------ | :---------------- | :--------------------- | :-------------- | | ||
| 2444 | -| 0 | 0 | 5 | 5 | 5 | 3-2-1-0 | 1-1-1-1 | | ||
| 2445 | -| 1 | 0 | 5 | 5 | 5-4 \= 1 | 7-6-5-4 | 0-0-0-1 | | ||
| 2446 | -| 2-63 | 0 | 5 | 5 | 0 | \- | 0-0-0-0 | | ||
| 2447 | -| 64 | 1 | 11 | 11-5 \= 6 | 6 | 8-7-6-5 | 1-1-1-1 | | ||
| 2448 | -| 65 | 1 | 11 | 6 | 6-4 \= 2 | 12-11-10-9 | 0-0-1-1 | | ||
| 2449 | -| 66-127 | 1 | 11 | 6 | 0 | \- | 0-0-0-0 | | ||
| 2450 | -| 128 | 2 | 25 | 25-11 \= 14 | 14 | 14-13-12-11 | 1-1-1-1 | | ||
| 2451 | -| 129 | 2 | 25 | 14 | 14-4 \= 10 | 18-17-16-15 | 1-1-1-1 | | ||
| 2452 | -| 130 | 2 | 25 | 14 | 10-4 \= 6 | 22-21-20-19 | 1-1-1-1 | | ||
| 2453 | -| 131 | 2 | 25 | 14 | 6-4 \= 2 | 26-25-24-23 | 0-0-1-1 | | ||
| 2454 | - | ||
| 2455 | - | ||
| 2456 | -In each cycle, the positions indicated by y\[rd\_ptr\] are flipped to 1 in the bitmap. Once a polynomial is finished, the bitmap, read pointer, current polynomial map, etc are all reset to prepare for the next polynomial. In this way, sigdecode\_h takes (64\*8 \= 512\) cycles to finish writing all coefficients to the internal memory (a few additional cycles are required for control state transitions). | ||
| 2457 | - | ||
| 2458 | -### Hint rules | ||
| 2459 | -The hint (h segment of the signature) must follow a specific pattern. Any violation of these rules renders the hint (and signature) invalid. In such cases, the sigDecode_h architecture raises an error, causing the verification process to fail. The structure of h is as follows: | ||
| 2460 | - | ||
| 2461 | -| Byte 0 | Byte 1 | Byte 2 | ... | Byte ω-1 | Byte ω | Byte ω+1 | ... | Byte ω+k-1 | | ||
| 2462 | -| --------- | --------- | --------- | ----- | ----------- | ------------ | ------------ | ----- | -------------- | | ||
| 2463 | -| Hint\_0 | Hint\_1 | Hint\_2 | ... | Hint\_ω-1 | HINTSUM\_0 | HINTSUM\_1 | ... | HINTSUM\_k-1 | | ||
| 2464 | - | ||
| 2465 | - | ||
| 2466 | - | ||
| 2467 | -- HINTSUM_0 represents the number of non-zero coefficients in poly_0. | ||
| 2468 | - | ||
| 2469 | -- For subsequent polynomials (poly\_i, where i > 0), the number of non-zero coefficients is determined by HINTSUM\_i - HINTSUM\_(i-1). | ||
| 2470 | - | ||
| 2471 | -The rules for a valid hint are as follows: | ||
| 2472 | - | ||
| 2473 | -1) The HINTSUM\_i values must be in ascending order. Repeated values are allowed, meaning a polynomial may have no non-zero coefficients. | ||
| 2474 | -2) The maximum allowable value for HINTSUM_i is ω. Since the values must be in ascending order, if HINTSUM\_i = ω for any i < k-1, then all subsequent HINTSUM values must also be ω. | ||
| 2475 | -3) Within each polynomial, non-zero coefficient indices must be unique and arranged in ascending order. | ||
| 2476 | -4) If HINTSUM\_(k-1) is less than ω, all hint values from Hint\_(HINTSUM\_(k-1)) to Hint\_(ω-1) must be zero. | ||
| 2477 | - | ||
| 2478 | -## UseHint Architecture | ||
| 2479 | - | ||
| 2480 | -To reconstruct the signer's commitment, it is necessary to update the approximate computed value labeled as w' by utilizing the provided hint. Hence, the value of w’ should be decomposed, and its higher part should be altered if the related hint equals 1 for that coefficient. Subsequently, the higher part requires encoding through the W1Encode operation and must be stored into the Keccak SIPO. | ||
| 2481 | - | ||
| 2482 | -The procedure is similar to the Decompose and W1Encode steps in the signing process, but it differs since there's no need to store the lower segment in memory. Moreover, the UseHint operation occurs between Decompose and W1Encode, adjusting the upper portion of the Decompose output utilizing h. | ||
| 2483 | - | ||
| 2484 | -The Decompose and W1Encode stages of the signing procedure are depicted below (with the gray components being inactive): | ||
| 2485 | - | ||
| 2486 | - | ||
| 2487 | - | ||
| 2488 | -The UseHint operation in the verifying operation is as follows (with the gray components being inactive): | ||
| 2489 | - | ||
| 2490 | - | ||
| 2491 | - | ||
| 2492 | -For w0 condition we have: | ||
| 2493 | - | ||
| 2494 | -- if w0=0 or w0 > γ_2: w1←w1-1 mod 16 | ||
| 2495 | -- else: w1←w1+1 mod 16 | ||
| 2496 | - | ||
| 2497 | -# High-Level architecture | ||
| 2498 | - | ||
| 2499 | -In our proposed architecture, we define specific instructions for various submodules, including SHAKE256, SHAKE128, NTT, INTT, etc. Each instruction is associated with an opcode and operands. By customizing these instructions, we can tailor the engine's behavior to different security levels. | ||
| 2500 | - | ||
| 2501 | -To execute the required instructions, a high-level controller acts as a sequencer, orchestrating a precise sequence of operations. Within the architecture, several memory blocks are accessible to submodules. However, it's the sequencer's responsibility to provide the necessary memory addresses for each operation. Additionally, the sequencer handles instruction fetching, decoding, operand retrieval, and overall data flow management. | ||
| 2502 | - | ||
| 2503 | -The high-level architecture of Adams Bridge controller is illustrated as follows: | ||
| 2504 | - | ||
| 2505 | - | ||
| 2506 | - | ||
| 2507 | -## Sequencer | ||
| 2508 | - | ||
| 2509 | -High-Level controller works as a sequencer to perform a specific sequence of operations. There are several blocks of memory in the architecture that can be accessed by sub-modules. However, the sequencer would be responsible for passing the required addresses for each operation. | ||
| 2510 | - | ||
| 2511 | -As an example, an NTT operation needs to take three base addresses as follows: | ||
| 2512 | - | ||
| 2513 | -NTT(initialvalue\_base\_address, intermediatevalue\_base\_address, result\_base\_address) | ||
| 2514 | - | ||
| 2515 | -So, for performing a=NTT(b), the sequencer needs to be: | ||
| 2516 | - | ||
| 2517 | -NTT(a\_base\_address, temp\_base\_address, b\_base\_address) | ||
| 2518 | - | ||
| 2519 | -The following table lists different operations used in the high-level controller. | ||
| 2520 | - | ||
| 2521 | -**Keccak and samplers Opcodes:** | ||
| 2522 | - | ||
| 2523 | -| Instruction | Description | | ||
| 2524 | -| :---------------------- | :------------------------------------------------------------------------------- | | ||
| 2525 | -| RST\_Keccak | Reset the Keccak SIPO buffer | | ||
| 2526 | -| EN\_Keccak | Enable the Keccak | | ||
| 2527 | -| LDKeccak\_MEM src, len | Load Keccak SIPO buffer at memory address src in len \-width | | ||
| 2528 | -| LDKeccak\_REG src, len | Load Keccak SIPO buffer at register ID src in len \-width | | ||
| 2529 | -| RDKeccak\_MEM dest, len | Read Keccak PISO buffer and store it at memory address dest in len \-width | | ||
| 2530 | -| RDKeccak\_REG dest, len | Read Keccak PISO buffer and store it at register ID dest in len \-width | | ||
| 2531 | -| REJBOUND\_SMPL dest | Start Keccak and RejBounded sampler and store the results at memory address dest | | ||
| 2532 | -| REJ\_SMPL | Start Keccak and rejection sampler (results is used by PWM) | | ||
| 2533 | -| SMPL\_INBALL | Start Keccak and SampleInBall (results is stored in SampleInBall memory) | | ||
| 2534 | -| EXP\_MASK dest | Start Keccak and ExpandMask sampler and store the results at memory address dest | | ||
| 2535 | - | ||
| 2536 | - | ||
| 2537 | -**NTT/INTT/PWO Opcodes:** | ||
| 2538 | - | ||
| 2539 | -| Instruction | Description | | ||
| 2540 | -| :------------------------- | :------------------------------------------------------------------------------------------------------------------------------------------------ | | ||
| 2541 | -| NTT src, temp, dest | Perform NTT on data at memory address src and store the results at address dest | | ||
| 2542 | -| INTT src, temp, dest | Perform INTT on data at memory address src and store the results at address dest | | ||
| 2543 | -| PWM src0, src1, dest | Perform PWM on data at memory address src0 and src1 and store the results at address dest (dest \= src0\*src1) | | ||
| 2544 | -| PWM\_SMPL src, dest | Perform PWM on data from sampler and at memory address src and store the results at address dest (dest \= smpl\*src) | | ||
| 2545 | -| PWM\_ACCU src0, src1, dest | Perform PWM in accumulation mode on data at memory address src0 and src1 and store the results at address dest (dest \= src0\*src1+dest) | | ||
| 2546 | -| PWM\_ACCU\_SMPL src, dest | Perform PWM in accumulation mode on data from sampler and at memory address src and store the results at address dest (dest \= smpl\*src \+ dest) | | ||
| 2547 | -| PWA src0, src1, dest | Perform PWA on data at memory address src0 and src1 and store the results at address dest (dest \= src0+src1) | | ||
| 2548 | -| PWS src0, src1, dest | Perform PWS on data at memory src0 and src1 and store the results at address dest (dest \= src0-src1) | | ||
| 2549 | - | ||
| 2550 | - | ||
| 2551 | -**Other Opcodes:** | ||
| 2552 | - | ||
| 2553 | -| Instruction | Description | | ||
| 2554 | -| :---------------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------- | | ||
| 2555 | -| MAKEHINT src, dest | Perform MakeHint on data at memory address src and store the results at register API address dest | | ||
| 2556 | -| USEHINT src0, src1 | Perform Decompose on w data at memory address src0 considering the hint data at memory address src1, and perform W1Encode on w1 and store them into Keccak SIPO | | ||
| 2557 | -| NORM\_CHK src, mode | Perform NormCheck on data at memory address src with mode configuration | | ||
| 2558 | -| SIG\_ENCODE src0, src1, dest | Perform sigEncode on data at memory address src0 and src1 and store the results at register API address dest | | ||
| 2559 | -| DECOMP\_SIGN src, dest | Perform Decompose on w data at memory address src and store w0 at memory address dest, and perform W1Encode on w1 and store them into Keccak SIPO | | ||
| 2560 | -| UPDATE\_κ | The value of κ will be updated as κ+l | | ||
| 2561 | -| POWER2ROUND src, dest0, dest1 | Perform Power2Round on t data at memory address src and store t0 at register API address dest0 and t1 at register API address dest1 | | ||
| 2562 | -| SIG\_DECODE\_Z src, dest | Perform sigDecode\_z on data at register API address src and store the results at memory address dest | | ||
| 2563 | -| SIG\_DECODE\_H src, dest | Perform sigDecode\_h on data at register API address src and store the results at memory address dest | | ||
| 2564 | - | ||
| 2565 | - | ||
| 2566 | -## Keygen Operation: | ||
| 2567 | - | ||
| 2568 | -The algorithm for keygen is presented below. We will explain the specifics of each operation in the following subsections. | ||
| 2569 | - | ||
| 2570 | - | ||
| 2571 | - | ||
| 2572 | -### (p,p',K)= H(ξ||K||L ,1024) | ||
| 2573 | - | ||
| 2574 | -Keygen starts with running Keccak operation on seed to derive three different values. Seed is a value stored in register API, and we need to perform SHAKE256 with 256-bit inputs to generate 1024 bits output. | ||
| 2575 | - | ||
| 2576 | -| Operation | opcode | operand | operand | operand | | ||
| 2577 | -| :-------------------- | :----------- | :------ | :------- | :------ | | ||
| 2578 | -| (p,p',K)=Keccak(seed) | Keccak\_SIPO | seed | 32 bytes || | ||
| 2579 | -|| Keccak\_SIPO | K | 1 byte || | ||
| 2580 | -|| Keccak\_SIPO | L | 1 byte || | ||
| 2581 | -|| Keccak\_PISO | p | 32 bytes || | ||
| 2582 | -|| Keccak\_PISO | p' | 64 bytes || | ||
| 2583 | -|| Keccak\_PISO | K | 32 bytes || | ||
| 2584 | - | ||
| 2585 | - | ||
| 2586 | -Firstly, we need to fill Keccak input buffer with seed and then run the Keccak core. After that, the Keccak output stored in PISO is used to set the p, p’, and K values. | ||
| 2587 | - | ||
| 2588 | -### (s1,s2)←ExpandS(ρ′) | ||
| 2589 | - | ||
| 2590 | -We use the previous step's p' as the input for the Keccak and run the rejbounded sampler. For each polynomial, we need to feed the Keccak input buffer with p' and a constant value of length 16 bits. To do this, we first feed the 512-bit p' into SIPO, and then we add a 16 bits value (which acts as a counter from 0 to 14\) to the end of the fed p' and then padding starts from there. | ||
| 2591 | - | ||
| 2592 | -Rejbounded opcode enables both Keccak and sampler and shows the destination of output into the memory. | ||
| 2593 | - | ||
| 2594 | -Then we run the rejbounded sampler 15 times with the shake256 mode. We can mask the latency of SIPO, the Keccak\_SIPO can be invoked when rejbounded is handling the previous data. However, the Keccak will not be enabled until rejbounded is done. | ||
| 2595 | - | ||
| 2596 | -| Operation | opcode | operand | operand | operand | | ||
| 2597 | -| :--------- | :----------- | :------ | :--------- | :------ | | ||
| 2598 | -| s1=expandS | Keccak\_SIPO | p' | 0 (2bytes) || | ||
| 2599 | -|| rejbounded | s1\_0 ||| | ||
| 2600 | -|| Keccak\_SIPO | p' | 1 || | ||
| 2601 | -|| rejbounded | s1\_1 ||| | ||
| 2602 | -|| … |||| | ||
| 2603 | -|| Keccak\_SIPO | p' | 6 || | ||
| 2604 | -|| rejbounded | s1\_6 ||| | ||
| 2605 | -| s2=expandS | Keccak\_SIPO | p' | 7 || | ||
| 2606 | -|| rejbounded | s2\_0 ||| | ||
| 2607 | -|| … |||| | ||
| 2608 | -|| Keccak\_SIPO | p' | 14 || | ||
| 2609 | -|| rejbounded | s2\_7 ||| | ||
| 2610 | - | ||
| 2611 | - | ||
| 2612 | -### NTT(s1) | ||
| 2613 | - | ||
| 2614 | -We need to call NTT for s1 by passing three addresses. Temp address can be the same for all NTT calls while init and destination are different. | ||
| 2615 | - | ||
| 2616 | -| Operation | opcode | operand | operand | operand | | ||
| 2617 | -| :-------- | :----- | :------ | :------ | :--------- | | ||
| 2618 | -| NTT(s1) | NTT | s1\_0 | temp | s1\_0\_ntt | | ||
| 2619 | -|| NTT | s1\_1 | temp | s1\_1\_ntt | | ||
| 2620 | -|| … |||| | ||
| 2621 | -|| NTT | s1\_6 | temp | s1\_6\_ntt | | ||
| 2622 | - | ||
| 2623 | - | ||
| 2624 | -### Aˆ ←ExpandA(ρ) AND Aˆ ◦NTT(s1) | ||
| 2625 | - | ||
| 2626 | -We perform rejection sampling and PWM simultaneously. This step takes p from the first step and appends two bytes of Keccak SIPO to the end of the given p and then starts padding from there. We run the rejection sampler 56 times with shake128 mode, where k \* l=56. | ||
| 2627 | - | ||
| 2628 | -Each polynomial requires p and the necessary constants to fill SIPO. Then Rejection\_sample opcode activates both Keccak and sampler. The output of rejection sampler goes straight to PWM unit. Then, the pwm opcode turns on pwm core, which can check the input from rejection sampler for a valid input. | ||
| 2629 | - | ||
| 2630 | -There are two different opcodes for PWM: regular PWM and PWM\_ACCU that indicates different modes for PWM units. | ||
| 2631 | - | ||
| 2632 | -We can mask the latency of SIPO, the Keccak\_SIPO can be invoked when PWM/Rejection\_sampler is handling the previous data. However, the Keccak will not be enabled until PWM is done. | ||
| 2633 | - | ||
| 2634 | -| Operation | opcode | operand | operand | operand | | ||
| 2635 | -| :--------------------- | :----------------- | :------- | :--------- | :--------- | | ||
| 2636 | -| As1\_0=PWM(A, NTT(s1)) | Keccak\_SIPO | p | 0 (1 byte) | 0 (1 byte) | | ||
| 2637 | -|| Rejection\_sampler |||| | ||
| 2638 | -|| pwm | DONTCARE | s1\_0\_ntt | As0 | | ||
| 2639 | -|| Keccak\_SIPO | p | 0 | 1 | | ||
| 2640 | -|| Rejection\_sampler |||| | ||
| 2641 | -|| pwm\_accu | DONTCARE | s1\_1\_ntt | As0 | | ||
| 2642 | -|| Keccak\_SIPO | p | 0 | 2 | | ||
| 2643 | -|| Rejection\_sampler |||| | ||
| 2644 | -|| pwm\_accu | DONTCARE | s1\_2\_ntt | As0 | | ||
| 2645 | -|| … |||| | ||
| 2646 | -|| Keccak\_SIPO | p | 0 | 6 | | ||
| 2647 | -|| Rejection\_sampler |||| | ||
| 2648 | -|| pwm\_accu | DONTCARE | s1\_6\_ntt | As0 | | ||
| 2649 | -| As1\_1=PWM(A, NTT(s1)) | Keccak\_SIPO | p | 1 | 0 | | ||
| 2650 | -|| Rejection\_sampler |||| | ||
| 2651 | -|| pwm | DONTCARE | s1\_0\_ntt | As1 | | ||
| 2652 | -|| Keccak\_SIPO | p | 1 | 1 | | ||
| 2653 | -|| Rejection\_sampler |||| | ||
| 2654 | -|| pwm\_accu | DONTCARE | s1\_1\_ntt | As1 | | ||
| 2655 | -|| … |||| | ||
| 2656 | -|| Keccak\_SIPO | p | 1 | 6 | | ||
| 2657 | -|| Rejection\_sampler |||| | ||
| 2658 | -|| pwm\_accu | DONTCARE | s1\_6\_ntt | As1 | | ||
| 2659 | -| As1\_7=PWM(A, NTT(s1)) | … |||| | ||
| 2660 | -|| Keccak\_SIPO | p | 7 | 6 | | ||
| 2661 | -|| Rejection\_sampler |||| | ||
| 2662 | -|| pwm\_accu | DONTCARE | s1\_6\_ntt | As7 | | ||
| 2663 | - | ||
| 2664 | - | ||
| 2665 | -### NTT−1(Aˆ ◦NTT(s1)) | ||
| 2666 | - | ||
| 2667 | -We need to call INTT for As1 by passing three addresses. Temp address can be the same for all INTT calls while init and destination are different. | ||
| 2668 | - | ||
| 2669 | -| Operation | opcode | operand | operand | operand | | ||
| 2670 | -| :-------- | :----- | :------ | :------ | :-------- | | ||
| 2671 | -| INTT(As1) | INTT | As0 | temp | As0\_intt | | ||
| 2672 | -|| INTT | As1 | temp | As1\_intt | | ||
| 2673 | -|| … |||| | ||
| 2674 | -|| INTT | As7 | temp | As7\_intt | | ||
| 2675 | - | ||
| 2676 | - | ||
| 2677 | -### t ←NTT−1(Aˆ ◦NTT(s1))+s2 | ||
| 2678 | - | ||
| 2679 | -We need to call point-wise addition for As1 results and s2 by passing three addresses. | ||
| 2680 | - | ||
| 2681 | -| Operation | opcode | operand | operand | operand | | ||
| 2682 | -| :------------- | :----- | :-------- | :------ | :------ | | ||
| 2683 | -| t=INTT(As1)+s2 | PWA | As0\_intt | s2\_0 | t0 | | ||
| 2684 | -|| PWA | As1\_intt | s2\_1 | t1 | | ||
| 2685 | -|| … |||| | ||
| 2686 | -|| PWA | As7\_intt | s2\_7 | t7 | | ||
| 2687 | - | ||
| 2688 | - | ||
| 2689 | -### (t1,t0)←Power2Round(t,*d*) AND *pk* ←pkEncode(ρ,t1) AND *sk* ←skEncode(t0) | ||
| 2690 | - | ||
| 2691 | -We need to call power2round for t results from the previous step, and the results are stored in two different addresses to API for sk and pk. | ||
| 2692 | - | ||
| 2693 | -| Operation | Opcode | operand | operand | operand | | ||
| 2694 | -| :------------------------- | :---------- | :------ | :------ | :------ | | ||
| 2695 | -| (t1,t0)←Power2Round(t,*d*) | POWER2ROUND | t | t0 (sk) | t1 (pk) | | ||
| 2696 | - | ||
| 2697 | - | ||
| 2698 | -NOTE: The value of ρ needs to be also stored into register API for pk. | ||
| 2699 | - | ||
| 2700 | -### *tr* ←H(BytesToBits(*pk*),512) | ||
| 2701 | - | ||
| 2702 | -The value of pk from register API needs to be read and stored into Keccak SIPO to perform SHAKE256. Due to long size of pk, 20 rounds of Keccak is required to executed to generate 512-bit tr. | ||
| 2703 | - | ||
| 2704 | -| Operation | opcode | operand | operand | operand | | ||
| 2705 | -| :------------ | :----------- | :------ | :--------- | :------ | | ||
| 2706 | -| tr=Keccak(pk) | Keccak\_SIPO | pk | 2592 bytes || | ||
| 2707 | -|| Keccak\_PISO | tr | 64 bytes || | ||
| 2708 | - | ||
| 2709 | - | ||
| 2710 | -### *sk* ←skEncode(ρ,*K*,*tr*,s1,s2,t0) | ||
| 2711 | - | ||
| 2712 | -The value of ρ, *K* needs to be stored into register API, while *tr* and *t0* are already stored by previous steps. | ||
| 2713 | - | ||
| 2714 | -We need to call skEncode for s1 and s2 coefficients and the results are stored into API for sk. | ||
| 2715 | - | ||
| 2716 | -| Operation | opcode | operand | operand | operand | | ||
| 2717 | -| :----------------- | :------- | :------ | :------ | :------ | | ||
| 2718 | -| *sk* ←skEncode(s1) | skEncode | s1 | sk || | ||
| 2719 | -| *sk* ←skEncode(s2) | skEncode | S2 | sk || | ||
| 2720 | - | ||
| 2721 | - | ||
| 2722 | -## Signing | ||
| 2723 | - | ||
| 2724 | -Signing operation is the most challenging operation for ML-DSA. From a high-level perspective, the required operation for performing a signing operation can be shown as follows: | ||
| 2725 | - | ||
| 2726 | - | ||
| 2727 | - | ||
| 2728 | -The are some initial processes to decode private key. The loop between challenge generation and validity check should be continued until validity check passed the results and then, the signature will be generated and published. | ||
| 2729 | - | ||
| 2730 | -In our optimized design, the next challenge is generated in advance, so that it can be used if the validity check of the current round fails. Therefore, we use two sequencers to support parallel operations. | ||
| 2731 | - | ||
| 2732 | -The algorithm for signing is presented below. We will explain the specifics of each operation in the following subsections. | ||
| 2733 | - | ||
| 2734 | - | ||
| 2735 | - | ||
| 2736 | -The following table shows the operations for each sequencer: | ||
| 2737 | - | ||
| 2738 | -| Sequencer 1 || | ||
| 2739 | -| -------------------- | :---------------------------- | | ||
| 2740 | -| Challenge Generation | μ ←H(*tr* ||*M*,512) | | ||
| 2741 | -|| ρ′←H(*K*||*rnd*||μ,512) | | ||
| 2742 | -|| y ←ExpandMask(ρ′ ,κ) | | ||
| 2743 | -|| w ←NTT−1(Aˆ ◦NTT(y)) | | ||
| 2744 | -|| (w1,w0) ←Decompose(w) | | ||
| 2745 | -|| *c*˜←H(μ ||w1Encode(w1),2λ) | | ||
| 2746 | -|| *c* ←SampleInBall(*c*˜) | | ||
| 2747 | -|| *κ ←κ \+ℓ* | | ||
| 2748 | - | ||
| 2749 | - | ||
| 2750 | - | ||
| 2751 | - | ||
| 2752 | -| Sequencer 2 || | ||
| 2753 | -| :------------------- | :---------------------------------------------- | | ||
| 2754 | -| Initial steps | (ρ,*K*,*tr*,s1,s2,t0)←skDecode(*sk*) | | ||
| 2755 | -|| sˆ1 ←NTT(s1) | | ||
| 2756 | -|| sˆ2 ←NTT(s2) | | ||
| 2757 | -|| ˆt0 ←NTT(t0) | | ||
| 2758 | -| Validity Checks | *c*ˆ ←NTT(*c*) | | ||
| 2759 | -|| \⟨\⟨*c*s1\⟩\⟩←NTT−1(*c*ˆ◦ sˆ1) | | ||
| 2760 | -|| ⟨⟨*c*s2⟩⟩←NTT−1(*c*ˆ◦ sˆ2) | | ||
| 2761 | -|| z ←y \+⟨⟨*c*s1⟩⟩ | | ||
| 2762 | -|| r0 ←(w0 −⟨⟨*c*s2⟩⟩) | | ||
| 2763 | -|| ⟨⟨*c*t0⟩⟩←NTT−1(*c*ˆ◦ tˆ0) | | ||
| 2764 | -|| h ←MakeHint(w1, w0−⟨⟨*c*s2⟩⟩+⟨⟨*c*t0⟩⟩) | | ||
| 2765 | -|| ||z||∞ ≥ γ1 −β | | ||
| 2766 | -|| ||r0 ||∞ ≥ γ2 −β | | ||
| 2767 | -|| ||⟨⟨*c*t0⟩⟩||∞ ≥ γ2 | | ||
| 2768 | -| Signature Generation | σ ←sigEncode(*c*˜,z mod±*q*,h) | | ||
| 2769 | - | ||
| 2770 | - | ||
| 2771 | -### (ρ,*K*,*tr*,s1,s2,t0)←skDecode(*sk*) | ||
| 2772 | - | ||
| 2773 | -We need to call skDecode for s1, s2, and t0 by passing the required addresses. | ||
| 2774 | - | ||
| 2775 | -| Operation | opcode | operand | operand | operand | | ||
| 2776 | -| :----------- | :------- | :------ | :------ | :------ | | ||
| 2777 | -| skDecode(s1) | skDecode | s1 | s1 || | ||
| 2778 | -| skDecode(s2) | skDecode | s2 | s2 || | ||
| 2779 | -| skDecode(t0) | skDecode | t0 | t0 || | ||
| 2780 | - | ||
| 2781 | - | ||
| 2782 | -### sˆ1 ←NTT(s1) | ||
| 2783 | - | ||
| 2784 | -We need to call NTT for s1 by passing three addresses. Temp address can be the same for all NTT calls while init and destination are different. | ||
| 2785 | - | ||
| 2786 | -| Operation | opcode | operand | operand | operand | | ||
| 2787 | -| :-------- | :----- | :------ | :------ | :--------- | | ||
| 2788 | -| NTT(s1) | NTT | s1\_0 | temp | s1\_0\_ntt | | ||
| 2789 | -|| NTT | s1\_1 | temp | s1\_1\_ntt | | ||
| 2790 | -|| … |||| | ||
| 2791 | -|| NTT | s1\_6 | temp | s1\_6\_ntt | | ||
| 2792 | - | ||
| 2793 | - | ||
| 2794 | -### sˆ2 ←NTT(s2) | ||
| 2795 | - | ||
| 2796 | -We need to call NTT for t0 by passing three addresses. Temp address can be the same for all NTT calls while init and destination are different. | ||
| 2797 | - | ||
| 2798 | -| Operation | opcode | operand | operand | operand | | ||
| 2799 | -| :-------- | :----- | :------ | :------ | :--------- | | ||
| 2800 | -| NTT(s2) | NTT | t0\_0 | temp | t0\_0\_ntt | | ||
| 2801 | -|| NTT | t0\_1 | temp | t0\_1\_ntt | | ||
| 2802 | -|| … |||| | ||
| 2803 | -|| NTT | t0\_7 | temp | t0\_7\_ntt | | ||
| 2804 | - | ||
| 2805 | - | ||
| 2806 | -### ˆt0 ←NTT(t0) | ||
| 2807 | - | ||
| 2808 | -We need to call NTT for s2 by passing three addresses. Temp address can be the same for all NTT calls while init and destination are different. | ||
| 2809 | - | ||
| 2810 | -| Operation | opcode | operand | operand | operand | | ||
| 2811 | -| :-------- | :----- | :------ | :------ | :--------- | | ||
| 2812 | -| NTT(s2) | NTT | s2\_0 | temp | s2\_0\_ntt | | ||
| 2813 | -|| NTT | s2\_1 | temp | s2\_1\_ntt | | ||
| 2814 | -|| … |||| | ||
| 2815 | -|| NTT | s2\_7 | temp | s2\_7\_ntt | | ||
| 2816 | - | ||
| 2817 | - | ||
| 2818 | -### *c*ˆ ←NTT(*c*) | ||
| 2819 | - | ||
| 2820 | -This is the part where two sequencers sync up. Sequencer 1 will pause until the second sequencer finishes the SampleInBall operation and the ready flag from SampleInBall tells the first sequencer to go on. | ||
| 2821 | - | ||
| 2822 | -We need to call NTT for c by passing three addresses. Temp address can be the same for all NTT calls while init and destination are different. | ||
| 2823 | - | ||
| 2824 | -| Operation | opcode | operand | operand | operand | | ||
| 2825 | -| :-------- | :----- | :------ | :------ | :------ | | ||
| 2826 | -| NTT(c) | NTT | c | temp | c\_ntt | | ||
| 2827 | - | ||
| 2828 | - | ||
| 2829 | -### ⟨⟨*c*s1⟩⟩←NTT−1(*c*ˆ◦ sˆ1) | ||
| 2830 | - | ||
| 2831 | -We need firstly to call PWM to perform point-wise multiplication between c and s1. | ||
| 2832 | - | ||
| 2833 | -| Operation | opcode | operand | operand | operand | | ||
| 2834 | -| :------------- | :----- | :------ | :--------- | :---------- | | ||
| 2835 | -| cs1=PWM(c, s1) | PWM | c\_ntt | s1\_0\_ntt | cs1\_0\_ntt | | ||
| 2836 | -|| PWM | c\_ntt | s1\_1\_ntt | cs1\_1\_ntt | | ||
| 2837 | -|| … |||| | ||
| 2838 | -|| PWM | c\_ntt | s1\_6\_ntt | cs1\_6\_ntt | | ||
| 2839 | - | ||
| 2840 | - | ||
| 2841 | -Then, we need to call INTT for cs1 by passing three addresses. Temp address can be the same for all INTT calls while init and destination are different. | ||
| 2842 | - | ||
| 2843 | -| Operation | opcode | operand | operand | operand | | ||
| 2844 | -| :-------- | :----- | :---------- | :------ | :------ | | ||
| 2845 | -| INTT(cs1) | INTT | cs1\_0\_ntt | temp | cs1\_0 | | ||
| 2846 | -|| INTT | cs1\_1\_ntt | temp | cs1\_1 | | ||
| 2847 | -|| … |||| | ||
| 2848 | -|| INTT | cs1\_6\_ntt | temp | cs1\_6 | | ||
| 2849 | - | ||
| 2850 | - | ||
| 2851 | -### ⟨⟨*c*s2⟩⟩←NTT−1(*c*ˆ◦ sˆ2) | ||
| 2852 | - | ||
| 2853 | -We need first to call PWM to perform point-wise multiplication between c and s2. | ||
| 2854 | - | ||
| 2855 | -| Operation | opcode | operand | operand | operand | | ||
| 2856 | -| :------------- | :----- | :------ | :--------- | :---------- | | ||
| 2857 | -| cs2=PWM(c, s2) | PWM | c\_ntt | s2\_0\_ntt | cs2\_0\_ntt | | ||
| 2858 | -|| PWM | c\_ntt | s2\_1\_ntt | cs2\_1\_ntt | | ||
| 2859 | -|| … |||| | ||
| 2860 | -|| PWM | c\_ntt | s2\_7\_ntt | cs2\_7\_ntt | | ||
| 2861 | - | ||
| 2862 | - | ||
| 2863 | -Then, we need to call INTT for cs2 by passing three addresses. Temp address can be the same for all INTT calls while init and destination are different. | ||
| 2864 | - | ||
| 2865 | -| Operation | opcode | operand | operand | operand | | ||
| 2866 | -| :-------- | :----- | :---------- | :------ | :------ | | ||
| 2867 | -| INTT(cs2) | INTT | cs2\_0\_ntt | temp | cs2\_0 | | ||
| 2868 | -|| INTT | cs2\_1\_ntt | temp | cs2\_1 | | ||
| 2869 | -|| … |||| | ||
| 2870 | -|| INTT | cs2\_7\_ntt | temp | cs2\_7 | | ||
| 2871 | - | ||
| 2872 | - | ||
| 2873 | -### z ←y \+⟨⟨*c*s1⟩⟩ | ||
| 2874 | - | ||
| 2875 | -We need to call PWA to perform point-wise addition between cs1 and y. | ||
| 2876 | - | ||
| 2877 | -| Operation | opcode | operand | operand | operand | | ||
| 2878 | -| :------------ | :----- | :------ | :------ | :------ | | ||
| 2879 | -| z=PWA(y, cs1) | PWA | y\_0 | cs1\_0 | z\_0 | | ||
| 2880 | -|| PWA | y\_1 | cs1\_1 | z\_1 | | ||
| 2881 | -|| … |||| | ||
| 2882 | -|| PWA | y\_6 | cs1\_6 | z\_6 | | ||
| 2883 | - | ||
| 2884 | - | ||
| 2885 | -### r0 ←(w0 −⟨⟨*c*s2⟩⟩) | ||
| 2886 | - | ||
| 2887 | -We need to call PWS to perform point-wise subtraction between w0 and cs2. | ||
| 2888 | - | ||
| 2889 | -| Operation | opcode | operand | operand | operand | | ||
| 2890 | -| :-------------- | :----- | :------ | :------ | :------ | | ||
| 2891 | -| r0=PWS(w0, cs2) | PWS | w0\_0 | cs2\_0 | r0\_0 | | ||
| 2892 | -|| PWS | w0\_1 | cs2\_1 | r0\_1 | | ||
| 2893 | -|| … |||| | ||
| 2894 | -|| PWS | w0\_7 | cs2\_7 | r0\_7 | | ||
| 2895 | - | ||
| 2896 | - | ||
| 2897 | -### ⟨⟨*c*t0⟩⟩←NTT−1(*c*ˆ◦ tˆ0) | ||
| 2898 | - | ||
| 2899 | -We need first to call PWM to perform point-wise multiplication between c and t0. | ||
| 2900 | - | ||
| 2901 | -| Operation | opcode | operand | operand | operand | | ||
| 2902 | -| :------------- | :----- | :------ | :--------- | :---------- | | ||
| 2903 | -| ct0=PWM(c, t0) | PWM | c\_ntt | t0\_0\_ntt | ct0\_0\_ntt | | ||
| 2904 | -|| PWM | c\_ntt | t0\_1\_ntt | ct0\_1\_ntt | | ||
| 2905 | -|| … |||| | ||
| 2906 | -|| PWM | c\_ntt | t0\_7\_ntt | ct0\_7\_ntt | | ||
| 2907 | - | ||
| 2908 | - | ||
| 2909 | -Then, we need to call INTT for ct0 by passing three addresses. Temp address can be the same for all INTT calls while init and destination are different. | ||
| 2910 | - | ||
| 2911 | -| Operation | opcode | operand | operand | operand | | ||
| 2912 | -| :-------- | :----- | :---------- | :------ | :------ | | ||
| 2913 | -| INTT(ct0) | INTT | ct0\_0\_ntt | temp | ct0\_0 | | ||
| 2914 | -|| INTT | ct0\_1\_ntt | temp | ct0\_1 | | ||
| 2915 | -|| … |||| | ||
| 2916 | -|| INTT | ct0\_7\_ntt | temp | ct0\_7 | | ||
| 2917 | - | ||
| 2918 | - | ||
| 2919 | -### h ←MakeHint(w1,r0+⟨⟨*c*t0⟩⟩) | ||
| 2920 | - | ||
| 2921 | -We need to call PWA to perform point-wise addition between r0 and ct0. | ||
| 2922 | - | ||
| 2923 | -| Operation | opcode | operand | operand | operand | | ||
| 2924 | -| :------------------- | :----- | :--------- | :------ | :------ | | ||
| 2925 | -| hint\_r=PWA(r0, ct0) | PWA | hint\_r\_0 | r0\_0 | ct0\_0 | | ||
| 2926 | -|| PWA | hint\_r\_1 | r0\_1 | ct0\_1 | | ||
| 2927 | -|| … |||| | ||
| 2928 | -|| PWA | hint\_r\_7 | r0\_7 | ct0\_7 | | ||
| 2929 | - | ||
| 2930 | - | ||
| 2931 | -Then, we need to call MakeHint for hint\_r. It will process the entire hint\_r polynomials, i.e., from hint\_r\_0 to hint\_r\_7. | ||
| 2932 | - | ||
| 2933 | -| Operation | opcode | operand | operand | operand | | ||
| 2934 | -| :------------------- | :------- | :--------- | :------ | :------ | | ||
| 2935 | -| hint\_r=PWA(r0, ct0) | MAKEHINT | hint\_r\_0 | h || | ||
| 2936 | - | ||
| 2937 | - | ||
| 2938 | -### ||z||∞ ≥ γ1 −β | ||
| 2939 | - | ||
| 2940 | -We need to call Norm\_Check to perform validity check on z. The output will be stored as an individual flag in the high-level architecture. | ||
| 2941 | - | ||
| 2942 | -| Operation | opcode | operand | operand | operand | | ||
| 2943 | -| :----------------- | :------ | :------ | :------ | :------ | | ||
| 2944 | -| Valid=NormCheck(z) | NormChk | z | mode || | ||
| 2945 | - | ||
| 2946 | - | ||
| 2947 | -### ||r0||∞ ≥ γ2 −β | ||
| 2948 | - | ||
| 2949 | -We need to call Norm\_Check to perform validity check on r0. The output will be stored as an individual flag in the high-level architecture. | ||
| 2950 | - | ||
| 2951 | -| Operation | opcode | operand | operand | operand | | ||
| 2952 | -| :------------------ | :------ | :------ | :------ | :------ | | ||
| 2953 | -| Valid=NormCheck(r0) | NormChk | r | mode || | ||
| 2954 | - | ||
| 2955 | - | ||
| 2956 | -### ||⟨⟨*c*t0⟩⟩||∞ ≥ γ2 | ||
| 2957 | - | ||
| 2958 | -We need to call Norm\_Check to perform validity check on ct0. The output will be stored as an individual flag in the high-level architecture. | ||
| 2959 | - | ||
| 2960 | -| Operation | opcode | operand | operand | operand | | ||
| 2961 | -| :------------------- | :------ | :------ | :------ | :------ | | ||
| 2962 | -| Valid=NormCheck(ct0) | NormChk | ct0 | mode || | ||
| 2963 | - | ||
| 2964 | - | ||
| 2965 | -### σ ←sigEncode(*c*˜,z mod±*q*,h) | ||
| 2966 | - | ||
| 2967 | -This step writes the final signature into the register API. Before that, the high-level design will check all four flags coming from: | ||
| 2968 | - | ||
| 2969 | -1) MakeHint | ||
| 2970 | -2) NormChk on z | ||
| 2971 | -3) NormChk on r0 | ||
| 2972 | -4) NormChk on ct0 | ||
| 2973 | - | ||
| 2974 | -If all checks show the successful signature, then the sigEncode unit will be called. The value of h is already stored by MakeHint unit into the register API. Hence, only two remaining parts will be passed to this unit. | ||
| 2975 | - | ||
| 2976 | -| Operation | opcode | operand | operand | operand | | ||
| 2977 | -| :--------------- | :-------- | :------ | :------ | :------ | | ||
| 2978 | -| σ=sigEncode(c,z) | sigEncode | c | z | σ | | ||
| 2979 | - | ||
| 2980 | - | ||
| 2981 | -### μ ←H(*tr*||*M*,512) | ||
| 2982 | - | ||
| 2983 | -The other sequencer starts with running Keccak operation on tr and the given message. tr and the message are stored in register API as inputs, and we need to perform SHAKE256 with to generate 512 bits output. | ||
| 2984 | - | ||
| 2985 | -| Operation | opcode | operand | operand | operand | | ||
| 2986 | -| :------------------ | :----------- | :------ | :------- | :------ | | ||
| 2987 | -| μ\=Keccak(tr|| M) | Keccak\_SIPO | tr | 64 bytes || | ||
| 2988 | -|| Keccak\_SIPO | 0 | 2 bytes || | ||
| 2989 | -|| Keccak\_SIPO | Message | 64 bytes || | ||
| 2990 | -|| Keccak\_PISO | μ | 64 bytes || | ||
| 2991 | - | ||
| 2992 | - | ||
| 2993 | - | ||
| 2994 | -### ρ′←H(*K*||*rnd*||μ,512) | ||
| 2995 | - | ||
| 2996 | -We need to run Keccak operation on K, rnd, and μ values. K and rnd are stored in register API as inputs, and μ is stored in an internal register. we need to perform SHAKE256 with to generate 512 bits output. | ||
| 2997 | - | ||
| 2998 | -| Operation | opcode | operand | operand | operand | | ||
| 2999 | -| :---------------------------- | :----------- | :-------- | :------------ | :------ | | ||
| 3000 | -| ρ′\=Keccak(K || rnd || μ) | Keccak\_SIPO | K | 4 (x64 words) || | ||
| 3001 | -|| Keccak\_SIPO | sign\_rnd | 4 (x64 words) || | ||
| 3002 | -|| Keccak\_SIPO | μ | 8 (x64 words) || | ||
| 3003 | -|| Keccak\_PISO | ρ′ | 8 (x64 words) || | ||
| 3004 | - | ||
| 3005 | - | ||
| 3006 | -Firstly, we need to fill Keccak input buffer with K and then concatenate it with sign\_rnd and μ. Then we run the Keccak core, and the Keccak output stored in PISO is used to set the ρ′ value into a special register. | ||
| 3007 | - | ||
| 3008 | -### y ←ExpandMask(ρ’ ,κ) | ||
| 3009 | - | ||
| 3010 | -We use the previous step's p' as the input for the Keccak and run the ExpandMask sampler. For each polynomial, we need to feed the Keccak input buffer with p' and a register value of length 16 bits. To do this, we first feed the 512-bit p' into SIPO, and then we add a 16 bits value (which acts as a counter from 0 to 6\) to the end of the fed p' and then padding starts from there. | ||
| 3011 | - | ||
| 3012 | -ExpandMask opcode enables both Keccak and sampler and shows the destination of output into the memory. | ||
| 3013 | - | ||
| 3014 | -Then we run the ExpandMask sampler 7 times with the shake256 mode. We can mask the latency of SIPO, the Keccak\_SIPO can be invoked when ExpandMask is handling the previous data. However, the Keccak will not be enabled until ExpandMask is done. | ||
| 3015 | - | ||
| 3016 | -| Operation | opcode | operand | operand | operand | | ||
| 3017 | -| :------------------ | :-------- | :------ | :------- | :------ | | ||
| 3018 | -| y=ExpandMask(ρ’ ,κ) | LDKeccak | p' | 64 bytes || | ||
| 3019 | -|| LDKeccak | κ | 2 bytes || | ||
| 3020 | -|| Exp\_Mask | y\_0 ||| | ||
| 3021 | -|| LDKeccak | p' | 1 bytes || | ||
| 3022 | -|| LDKeccak | κ+1 | 2 bytes || | ||
| 3023 | -|| Exp\_Mask | y\_1 ||| | ||
| 3024 | -|| … |||| | ||
| 3025 | -|| LDKeccak | p' | 64 bytes || | ||
| 3026 | -|| LDKeccak | κ \+6 | 2 bytes || | ||
| 3027 | -|| Exp\_Mask | y\_6 ||| | ||
| 3028 | - | ||
| 3029 | - | ||
| 3030 | -### NTT(y) | ||
| 3031 | - | ||
| 3032 | -We need to call NTT for s1 by passing three addresses. Temp address can be the same for all NTT calls while init and destination are different. | ||
| 3033 | - | ||
| 3034 | -| Operation | opcode | operand | operand | operand | | ||
| 3035 | -| :-------- | :----- | :------ | :------ | :-------- | | ||
| 3036 | -| NTT(y) | NTT | y\_0 | temp | y\_0\_ntt | | ||
| 3037 | -|| NTT | y\_1 | temp | y\_1\_ntt | | ||
| 3038 | -|| … |||| | ||
| 3039 | -|| NTT | y\_6 | temp | y\_6\_ntt | | ||
| 3040 | - | ||
| 3041 | - | ||
| 3042 | -### Aˆ ←ExpandA(ρ) AND Aˆ ◦NTT(y) | ||
| 3043 | - | ||
| 3044 | -We perform rejection sampling and PWM simultaneously. This step takes p from and appends two bytes of Keccak SIPO to the end of the given p and then starts padding from there. We run the rejection sampler 56 times with shake128 mode, where k \* l=56. | ||
| 3045 | - | ||
| 3046 | -Each polynomial requires p and the necessary constants to fill SIPO. Then Rejection\_sample opcode activates both Keccak and sampler. The output of rejection sampler goes straight to PWM unit. Then, the pwm opcode turns on pwm core, which can check the input from rejection sampler for a valid input. | ||
| 3047 | - | ||
| 3048 | -There are two different opcodes for PWM: regular PWM and PWM\_ACCU that indicates different modes for PWM units. | ||
| 3049 | - | ||
| 3050 | -We can mask the latency of SIPO, the Keccak\_SIPO can be invoked when PWM/Rejection\_sampler is handling the previous data. However, the Keccak will not be enabled until PWM is done. | ||
| 3051 | - | ||
| 3052 | -| Operation | opcode | operand | operand | operand | | ||
| 3053 | -| :----------------- | :----------------- | :------- | :-------- | :------ | | ||
| 3054 | -| Ay0=PWM(A, NTT(y)) | LDKeccak | p | 32 bytes || | ||
| 3055 | -|| LDKeccak | 0 | 1 byte || | ||
| 3056 | -|| LDKeccak | 0 | 1 byte || | ||
| 3057 | -|| Rejection\_sampler |||| | ||
| 3058 | -|| pwm | DONTCARE | y\_0\_ntt | Ay0 | | ||
| 3059 | -|| LDKeccak | p | 32 bytes || | ||
| 3060 | -|| LDKeccak | 0 | 1 byte || | ||
| 3061 | -|| LDKeccak | 1 | 1 byte || | ||
| 3062 | -|| Rejection\_sampler |||| | ||
| 3063 | -|| pwm\_accu | DONTCARE | y\_1\_ntt | Ay0 | | ||
| 3064 | -|| LDKeccak | p | 32 bytes || | ||
| 3065 | -|| LDKeccak | 0 | 1 byte || | ||
| 3066 | -|| LDKeccak | 2 | 1 byte || | ||
| 3067 | -|| Rejection\_sampler |||| | ||
| 3068 | -|| pwm\_accu | DONTCARE | y\_2\_ntt | Ay0 | | ||
| 3069 | -|| … |||| | ||
| 3070 | -|| LDKeccak | p | 32 bytes || | ||
| 3071 | -|| LDKeccak | 0 | 1 byte || | ||
| 3072 | -|| LDKeccak | 6 | 1 byte || | ||
| 3073 | -|| Rejection\_sampler |||| | ||
| 3074 | -|| pwm\_accu | DONTCARE | y\_6\_ntt | Ay0 | | ||
| 3075 | -| Ay1=PWM(A, NTT(y)) | LDKeccak | p | 32 bytes | 0 | | ||
| 3076 | -|| LDKeccak | 1 | 1 byte || | ||
| 3077 | -|| LDKeccak | 0 | 1 byte || | ||
| 3078 | -|| Rejection\_sampler |||| | ||
| 3079 | -|| pwm | DONTCARE | y\_0\_ntt | Ay1 | | ||
| 3080 | -|| LDKeccak | p | 32 bytes || | ||
| 3081 | -|| LDKeccak | 1 | 1 byte || | ||
| 3082 | -|| LDKeccak | 1 | 1 byte || | ||
| 3083 | -|| Rejection\_sampler |||| | ||
| 3084 | -|| pwm\_accu | DONTCARE | y\_1\_ntt | Ay1 | | ||
| 3085 | -|| … |||| | ||
| 3086 | -|| LDKeccak | p | 32 bytes || | ||
| 3087 | -|| LDKeccak | 1 | 1 byte || | ||
| 3088 | -|| LDKeccak | 6 | 1 byte || | ||
| 3089 | -|| Rejection\_sampler |||| | ||
| 3090 | -|| pwm\_accu | DONTCARE | y\_6\_ntt | Ay1 | | ||
| 3091 | -| Ay7=PWM(A, NTT(y)) | … |||| | ||
| 3092 | -|| LDKeccak | p | 32 bytes || | ||
| 3093 | -|| LDKeccak | 7 | 1 byte || | ||
| 3094 | -|| LDKeccak | 6 | 1 byte || | ||
| 3095 | -|| Rejection\_sampler |||| | ||
| 3096 | -|| pwm\_accu | DONTCARE | y\_6\_ntt | Ay7 | | ||
| 3097 | - | ||
| 3098 | - | ||
| 3099 | -### w ←NTT−1(Aˆ ◦NTT(y)) | ||
| 3100 | - | ||
| 3101 | -We need to call INTT for Ay by passing three addresses. Temp address can be the same for all INTT calls while init and destination are different. | ||
| 3102 | - | ||
| 3103 | -| Operation | opcode | operand | operand | operand | | ||
| 3104 | -| :-------- | :----- | :------ | :------ | :------ | | ||
| 3105 | -| INTT(Ay) | INTT | Ay0 | temp | w\_0 | | ||
| 3106 | -|| INTT | Ay1 | temp | w\_1 | | ||
| 3107 | -|| … |||| | ||
| 3108 | -|| INTT | Ay7 | temp | w\_7 | | ||
| 3109 | - | ||
| 3110 | - | ||
| 3111 | -### (w1,w0) ←Decompose(w) AND *c*˜←H(μ||w1Encode(w1),2λ) | ||
| 3112 | - | ||
| 3113 | -The decompose unit takes w from memory and splits it into two parts. It saves w0 in memory and sends w1 to the Keccak SIPO for SampleInBall. However, SIPO requires the μ prefix before receiving the w1 values. Therefore, the high-level controller should provide μ before using decompose. After completing the decompose operation, the high-level controller needs to add the necessary padding for H(μ||w1Encode(w1),2λ). Then, by activating the SampleInBall, the Keccak will start and the data in the SIPO will be processed. | ||
| 3114 | - | ||
| 3115 | -| Operation | opcode | operand | operand | operand | | ||
| 3116 | -| :------------------------ | :---------- | :--------------- | :------- | :------ | | ||
| 3117 | -| H(μ || w1Encode(w1),2λ) | LDKeccak | μ | 64 bytes || | ||
| 3118 | -| (w1,w0) ←Decompose(w) | Decomp\_Enc | w | w0 || | ||
| 3119 | -| H(μ || w1Encode(w1),2λ) | LDKeccak | padding | | ||
| 3120 | - | ||
| 3121 | - | ||
| 3122 | -### *c* ←SampleInBall(*c*˜) | ||
| 3123 | - | ||
| 3124 | -We take the SIPO value from the last step as the Keccak input and run SampleInBall. The output stays in the SampleInBall memory. | ||
| 3125 | - | ||
| 3126 | -| Operation | opcode | operand | operand | operand | | ||
| 3127 | -| :----------------------- | :----------- | :------ | :------ | :------ | | ||
| 3128 | -| *c* ←SampleInBall(*c*˜1) | SMPL\_INBALL |||| | ||
| 3129 | - | ||
| 3130 | - | ||
| 3131 | -### κ ←κ \+ℓ | ||
| 3132 | - | ||
| 3133 | -High-level controller increases the value of κ by l. | ||
| 3134 | - | ||
| 3135 | -| Operation | opcode | operand | operand | operand | | ||
| 3136 | -| :-------- | :-------- | :------ | :------ | :------ | | ||
| 3137 | -| κ ←κ \+ℓ | Update\_k |||| | ||
| 3138 | - | ||
| 3139 | - | ||
| 3140 | -## Verifying | ||
| 3141 | - | ||
| 3142 | -The algorithm for verifying is presented below. We will explain the specifics of each operation in the following subsections. | ||
| 3143 | - | ||
| 3144 | - | ||
| 3145 | - | ||
| 3146 | -### (ρ,t1)←pkDecode(*pk*) | ||
| 3147 | - | ||
| 3148 | -We need to call pkDecode to decode the given pk for t1 values. | ||
| 3149 | - | ||
| 3150 | -| Operation | opcode | operand | operand | operand | | ||
| 3151 | -| :---------------- | :------- | :------ | :------ | :------ | | ||
| 3152 | -| *t1←pkDecode(pk)* | pkDecode | *pk* | t1 || | ||
| 3153 | - | ||
| 3154 | - | ||
| 3155 | -### (*c*˜,z,h)←sigDecode(σ) | ||
| 3156 | - | ||
| 3157 | -We need to call sigDecode to decode the given signature for z and h values. | ||
| 3158 | - | ||
| 3159 | -| Operation | opcode | operand | operand | operand | | ||
| 3160 | -| :----------------- | :----------- | :------ | :------ | :------ | | ||
| 3161 | -| (z,h)←sigDecode(σ) | sigDecode\_z | *σ\_z* | z || | ||
| 3162 | -|| sigDecode\_h | *σ\_h* | h || | ||
| 3163 | - | ||
| 3164 | - | ||
| 3165 | -### ||z||∞ ≥ γ1 −β | ||
| 3166 | - | ||
| 3167 | -We need to call Norm\_Check to perform validity check on the given z. The output will be stored as an individual flag in the high-level architecture. | ||
| 3168 | - | ||
| 3169 | -| Operation | opcode | operand | operand | operand | | ||
| 3170 | -| :----------------- | :------ | :------ | :------ | :------ | | ||
| 3171 | -| Valid=NormCheck(z) | NormChk | z | mode || | ||
| 3172 | - | ||
| 3173 | - | ||
| 3174 | -### \[\[number of 1’s in h is ≤ ω\]\] | ||
| 3175 | - | ||
| 3176 | -We need to call HintSum to perform validity check on the given h. The output will be stored as an individual flag in the high-level architecture. | ||
| 3177 | - | ||
| 3178 | -| Operation | opcode | operand | operand | operand | | ||
| 3179 | -| :--------------- | :------ | :------ | :------ | :------ | | ||
| 3180 | -| Valid=HintSum(h) | HINTSUM | h ||| | ||
| 3181 | - | ||
| 3182 | - | ||
| 3183 | -### z ←NTT(z) | ||
| 3184 | - | ||
| 3185 | -We need to call NTT for z by passing three addresses. Temp address can be the same for all NTT calls while init and destination are different. | ||
| 3186 | - | ||
| 3187 | -| Operation | opcode | operand | operand | operand | | ||
| 3188 | -| :-------- | :----- | :------ | :------ | :-------- | | ||
| 3189 | -| NTT(z) | NTT | z\_0 | temp | z\_0\_ntt | | ||
| 3190 | -|| NTT | z\_1 | temp | z\_1\_ntt | | ||
| 3191 | -|| … |||| | ||
| 3192 | -|| NTT | z\_6 | temp | z\_6\_ntt | | ||
| 3193 | - | ||
| 3194 | - | ||
| 3195 | -### Aˆ ←ExpandA(ρ) AND Aˆ ◦NTT(z) | ||
| 3196 | - | ||
| 3197 | -We perform rejection sampling and PWM simultaneously. This step takes p from the register API and appends two bytes of Keccak SIPO to the end of the given p and then starts padding from there. We run the rejection sampler 56 times with shake128 mode, where k \* l=56. | ||
| 3198 | - | ||
| 3199 | -Each polynomial requires p and the necessary constants to fill SIPO. Then Rejection\_sample opcode activates both Keccak and sampler. The output of rejection sampler goes straight to PWM unit. Then, the pwm opcode turns on pwm core, which can check the input from rejection sampler for a valid input. | ||
| 3200 | - | ||
| 3201 | -There are two different opcodes for PWM: regular PWM and PWM\_ACCU that indicates different modes for PWM units. | ||
| 3202 | - | ||
| 3203 | -We can mask the latency of SIPO, the Keccak\_SIPO can be invoked when PWM/Rejection\_sampler is handling the previous data. However, the Keccak will not be enabled until PWM is done. | ||
| 3204 | - | ||
| 3205 | -| Operation | opcode | operand | operand | operand | | ||
| 3206 | -| :------------------- | :----------------- | :------- | :--------- | :--------- | | ||
| 3207 | -| Az\_0=PWM(A, NTT(z)) | Keccak\_SIPO | p | 0 (1 byte) | 0 (1 byte) | | ||
| 3208 | -|| Rejection\_sampler |||| | ||
| 3209 | -|| pwm | DONTCARE | z\_0\_ntt | Az0 | | ||
| 3210 | -|| Keccak\_SIPO | p | 0 | 1 | | ||
| 3211 | -|| Rejection\_sampler |||| | ||
| 3212 | -|| pwm\_accu | DONTCARE | z\_1\_ntt | Az0 | | ||
| 3213 | -|| Keccak\_SIPO | p | 0 | 2 | | ||
| 3214 | -|| Rejection\_sampler |||| | ||
| 3215 | -|| pwm\_accu | DONTCARE | z\_2\_ntt | Az0 | | ||
| 3216 | -|| … |||| | ||
| 3217 | -|| Keccak\_SIPO | p | 0 | 6 | | ||
| 3218 | -|| Rejection\_sampler |||| | ||
| 3219 | -|| pwm\_accu | DONTCARE | z\_6\_ntt | Az0 | | ||
| 3220 | -| Az\_1=PWM(A, NTT(z)) | Keccak\_SIPO | p | 1 | 0 | | ||
| 3221 | -|| Rejection\_sampler |||| | ||
| 3222 | -|| pwm | DONTCARE | z\_0\_ntt | Az1 | | ||
| 3223 | -|| Keccak\_SIPO | p | 1 | 1 | | ||
| 3224 | -|| Rejection\_sampler |||| | ||
| 3225 | -|| pwm\_accu | DONTCARE | z\_1\_ntt | Az1 | | ||
| 3226 | -|| … |||| | ||
| 3227 | -|| Keccak\_SIPO | p | 1 | 6 | | ||
| 3228 | -|| Rejection\_sampler |||| | ||
| 3229 | -|| pwm\_accu | DONTCARE | z\_6\_ntt | Az1 | | ||
| 3230 | -| Az\_7=PWM(A, NTT(z)) | … |||| | ||
| 3231 | -|| Keccak\_SIPO | p | 7 | 6 | | ||
| 3232 | -|| Rejection\_sampler |||| | ||
| 3233 | -|| pwm\_accu | DONTCARE | z\_6\_ntt | Az7 | | ||
| 3234 | - | ||
| 3235 | - | ||
| 3236 | -### tr ←H(pk,512) | ||
| 3237 | - | ||
| 3238 | -The sequencer runs Keccak operation on pk. pk is stored in register API as input, and we need to perform SHAKE256 with to generate 512 bits output. | ||
| 3239 | - | ||
| 3240 | -| Operation | opcode | operand | operand | operand | | ||
| 3241 | -| :------------ | :----------- | :------ | :--------- | :------ | | ||
| 3242 | -| tr=Keccak(pk) | Keccak\_SIPO | pk | 2592 bytes || | ||
| 3243 | -|| Keccak\_PISO | tr | 64 bytes || | ||
| 3244 | - | ||
| 3245 | - | ||
| 3246 | -### μ ←H(*tr*||*M*,512) | ||
| 3247 | - | ||
| 3248 | -The sequencer starts with running Keccak operation on tr and the given message. tr is stored in an internal register from the previous step, and the message is stored in register API as input, and we need to perform SHAKE256 with to generate 512 bits output. | ||
| 3249 | - | ||
| 3250 | -| Operation | opcode | operand | operand | operand | | ||
| 3251 | -| :------------------- | :----------- | :------ | :------- | :------ | | ||
| 3252 | -| μ\=Keccak(tr || M) | Keccak\_SIPO | tr | 64 bytes || | ||
| 3253 | -|| Keccak\_SIPO | 0 | 2 bytes || | ||
| 3254 | -|| Keccak\_SIPO | Message | 64 bytes || | ||
| 3255 | -|| Keccak\_PISO | μ | 64 bytes || | ||
| 3256 | - | ||
| 3257 | - | ||
| 3258 | -### *c* ←SampleInBall(*c*˜) | ||
| 3259 | - | ||
| 3260 | -We take the c\~ values from register API as the Keccak input and run SampleInBall. The output stays in the SampleInBall memory. | ||
| 3261 | - | ||
| 3262 | -| Operation | opcode | operand | operand | operand | | ||
| 3263 | -| :---------------------- | :----------- | :------ | :------- | :------ | | ||
| 3264 | -|| Keccak\_SIPO | c\~ | 64 bytes || | ||
| 3265 | -| *c* ←SampleInBall(*c*˜) | SMPL\_INBALL |||| | ||
| 3266 | - | ||
| 3267 | - | ||
| 3268 | -### *c*ˆ ←NTT(*c*) | ||
| 3269 | - | ||
| 3270 | -We need to call NTT for c by passing three addresses. Temp address can be the same for all NTT calls while init and destination are different. | ||
| 3271 | - | ||
| 3272 | -| Operation | opcode | operand | operand | operand | | ||
| 3273 | -| :-------- | :----- | :------ | :------ | :------ | | ||
| 3274 | -| NTT(c) | NTT | c | temp | c\_ntt | | ||
| 3275 | - | ||
| 3276 | - | ||
| 3277 | -### *c*ˆ ←NTT(*c*) | ||
| 3278 | - | ||
| 3279 | -We need to call NTT for c by passing three addresses. Temp address can be the same for all NTT calls while init and destination are different. | ||
| 3280 | - | ||
| 3281 | -| Operation | opcode | operand | operand | operand | | ||
| 3282 | -| :-------- | :----- | :------ | :------ | :------ | | ||
| 3283 | -| NTT(c) | NTT | c | temp | c\_ntt | | ||
| 3284 | - | ||
| 3285 | - | ||
| 3286 | -### t1 ←NTT(t1) | ||
| 3287 | - | ||
| 3288 | -We need to call NTT for t1 by passing three addresses. Temp address can be the same for all NTT calls while init and destination are different. | ||
| 3289 | - | ||
| 3290 | -| Operation | opcode | operand | operand | operand | | ||
| 3291 | -| :-------- | :----- | :------ | :------ | :--------- | | ||
| 3292 | -| NTT(t1) | NTT | t1\_0 | temp | t1\_0\_ntt | | ||
| 3293 | -|| NTT | t1\_1 | temp | t1\_1\_ntt | | ||
| 3294 | -|| … |||| | ||
| 3295 | -|| NTT | t1\_7 | temp | t1\_7\_ntt | | ||
| 3296 | - | ||
| 3297 | - | ||
| 3298 | -### NTT(*c*) ◦NTT(t1) | ||
| 3299 | - | ||
| 3300 | -We need to call point-wise multiplication between c and all t1 polynomials in NTT domain. | ||
| 3301 | - | ||
| 3302 | -| Operation | opcode | operand | operand | operand | | ||
| 3303 | -| :------------------------- | :----- | :------ | :--------- | :------ | | ||
| 3304 | -| ct1=PWM(NTT(*c*) ◦NTT(t1)) | PWM | c\_ntt | t1\_0\_ntt | ct1\_0 | | ||
| 3305 | -|| PWM | c\_ntt | t1\_1\_ntt | ct1\_1 | | ||
| 3306 | -|| … |||| | ||
| 3307 | -| . | PWM | c\_ntt | t1\_7\_ntt | ct1\_7 | | ||
| 3308 | - | ||
| 3309 | - | ||
| 3310 | -### A ˆ ◦NTT(z*)* −NTT(*c*) ◦NTT(t1) | ||
| 3311 | - | ||
| 3312 | -We need to call point-wise subtraction between Az and ct1 polynomials in NTT domain. | ||
| 3313 | - | ||
| 3314 | -| Operation | opcode | operand | operand | operand | | ||
| 3315 | -| :-------------------------------------- | :----- | :------ | :------ | :--------- | | ||
| 3316 | -| Az-ct1=A ˆ ◦NTT(z*)* −NTT(*c*) ◦NTT(t1) | PWS | Az\_0 | ct1\_0 | Az\_ct1\_0 | | ||
| 3317 | -|| PWS | Az\_1 | ct1\_1 | Az\_ct1\_1 | | ||
| 3318 | -|| … |||| | ||
| 3319 | -| . | PWS | Az\_7 | ct1\_7 | Az\_ct1\_7 | | ||
| 3320 | - | ||
| 3321 | - | ||
| 3322 | -### w′ ←NTT-1(A ˆ ◦NTT(z*)* −NTT(*c*) ◦NTT(t1)) | ||
| 3323 | - | ||
| 3324 | -We need to call INTT for Az\_ct1 by passing three addresses. Temp address can be the same for all INTT calls while init and destination are different. | ||
| 3325 | - | ||
| 3326 | -| Operation | opcode | operand | operand | operand | | ||
| 3327 | -| :------------------------------------------ | :----- | :--------- | :------ | :------ | | ||
| 3328 | -| w′ ←NTT-1(A ˆ ◦NTT(z*)* −NTT(*c*) ◦NTT(t1)) | INTT | Az\_ct1\_0 | temp | w’\_0 | | ||
| 3329 | -|| INTT | Az\_ct1\_1 | temp | w’\_1 | | ||
| 3330 | -|| … |||| | ||
| 3331 | -|| INTT | Az\_ct1\_7 | temp | w’\_7 | | ||
| 3332 | - | ||
| 3333 | - | ||
| 3334 | -### w ′ ←UseHint(h,w ′) AND *c*˜←H(μ||w1Encode(w1),2λ) | ||
| 3335 | - | ||
| 3336 | -In the UseHint phase, the decompose unit retrieves w from memory and divides it into two components. Next, w1 is refreshed through useHint, encoded, and forwarded to the Keccak SIPO. Nonetheless, the μ prefix must precede w1 before SIPO can accept it. Therefore, the high-level controller should provide μ before using decompose. After completing the UseHint operation, the high-level controller needs to add the necessary padding for H(μ||w1Encode(w1),2λ). Then, the Keccak will start and the data in the SIPO will be stored at register API as verification result. | ||
| 3337 | - | ||
| 3338 | -| Operation | opcode | operand | operand | operand | | ||
| 3339 | -| :------------------------- | :--------- | :------------------ | :------- | :------ | | ||
| 3340 | -| H(μ || w1Encode(w1),2λ) | LDKeccak | μ | 64 bytes || | ||
| 3341 | -| w ′ ←UseHint(h,w ′) | USEHINT | w | H || | ||
| 3342 | -| H(μ || w1Encode(w1),2λ) | LDKeccak | padding ||| | ||
| 3343 | -|| EN\_Keccak |||| | ||
| 3344 | -|| RDKeccak | Verification Result ||| | ||
| 3345 | - | ||
| 3346 | - | ||
| 3347 | -References: | ||
| 98 | +# References: | ||
| 3348 | 99 | ||
| 3349 | 100 | [1] The White House, "National Security Memorandum on Promoting United States Leadership in Quantum Computing While Mitigating Risks to Vulnerable Cryptographic Systems," 2022. [Online]. Available: [White House](https://www.whitehouse.gov/briefing-room/statements-releases/2022/05/04/national-security-memorandum-on-promoting-united-states-leadership-in-quantum-computing-while-mitigating-risks-to-vulnerable-cryptographic-systems/). | |
| 3350 | 101 | ||
| 3351 | -[2] NIST, "PQC Standardization Process: Announcing Four Candidates to be Standardized, Plus Fourth Round Candidates," [Online]. Available: [NIST PQC](https://csrc.nist.gov/news/2022/pqc-candidates-to-be-standardized-and-round-4). [Accessed 2022]. | ||
| 102 | +[2] NIST, "FIPS 203 Module-Lattice-Based Key-Encapsulation Mechanism Standard," August 13, 2024. | ||
| 3352 | 103 | ||
| 3353 | 104 | [3] NIST, "FIPS 204 Module-Lattice-Based Digital Signature Standard," August 13, 2024. | |
| 3354 | 105 | ||
Image not present in this version
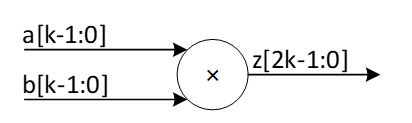
Image not present in this version
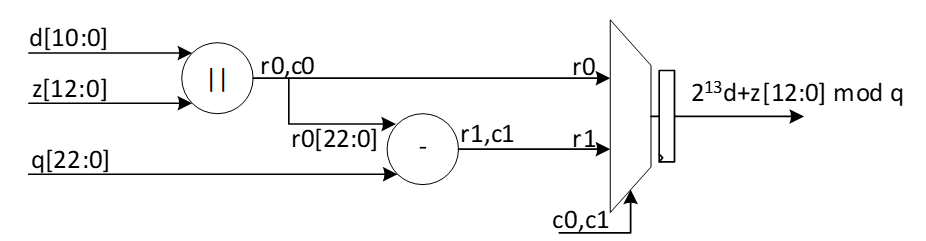
Image not present in this version
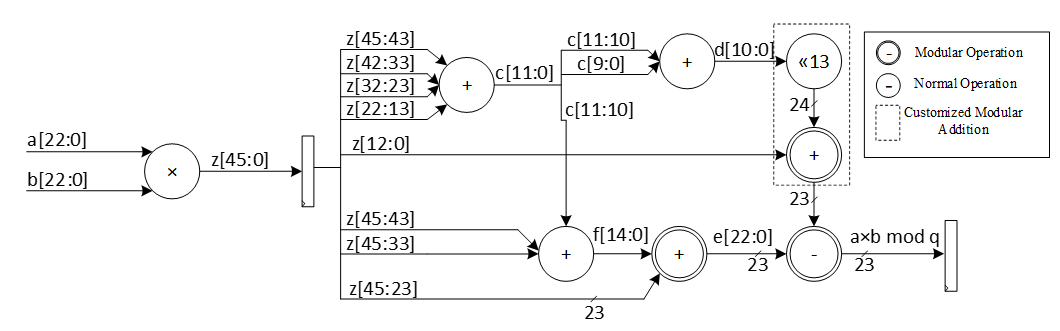
Image not present in this version
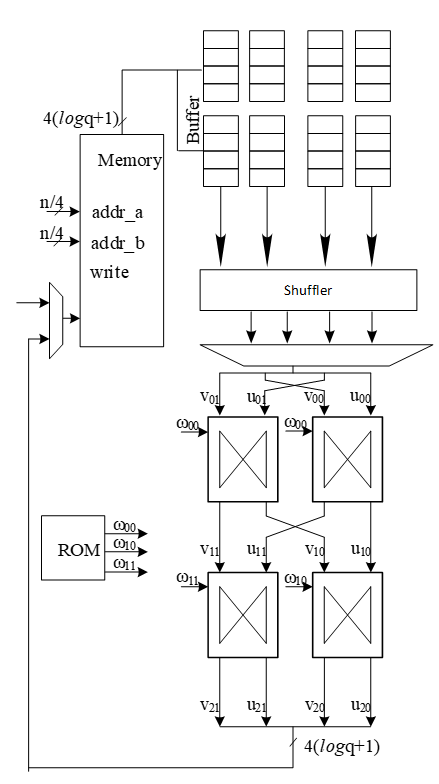
Image not present in this version
Image not present in this version
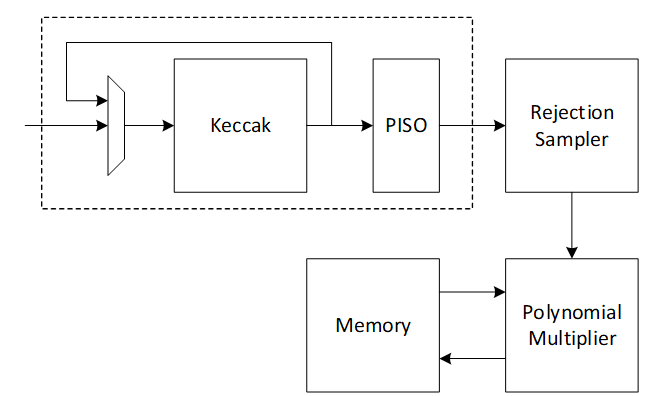
Image not present in this version
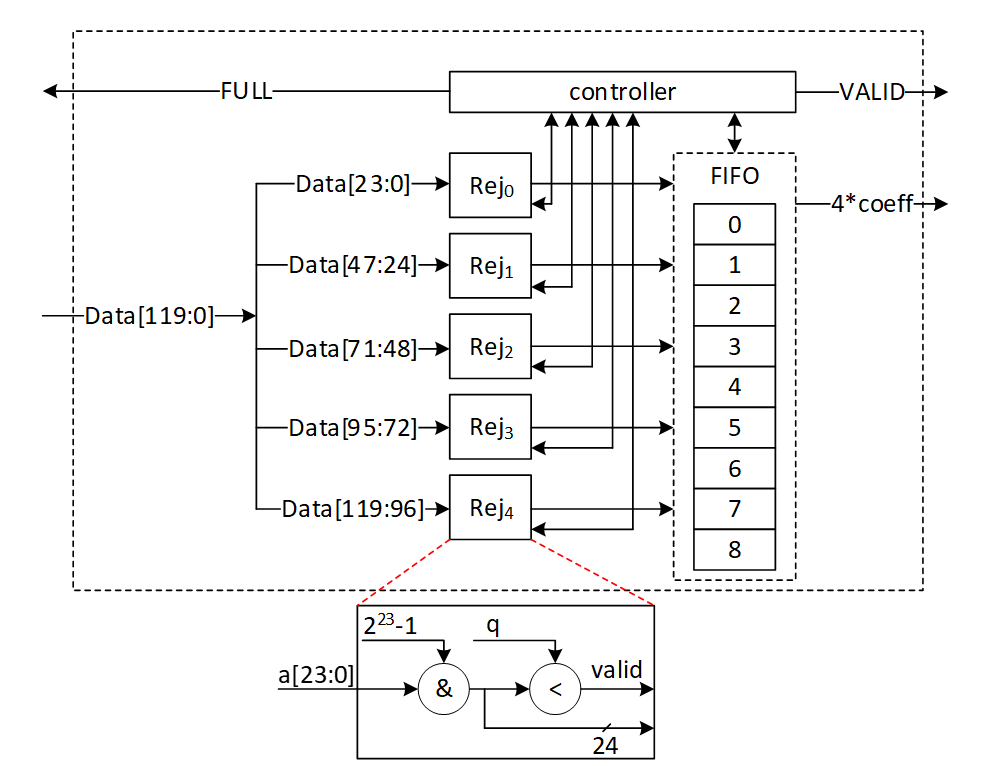
Image not present in this version
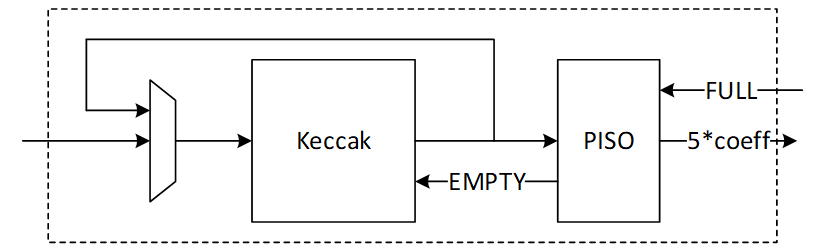
Image not present in this version
Image not present in this version
Image not present in this version
Image not present in this version
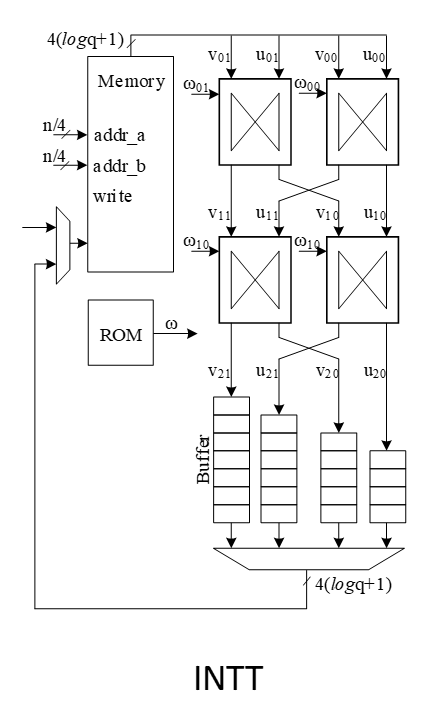
Image not present in this version
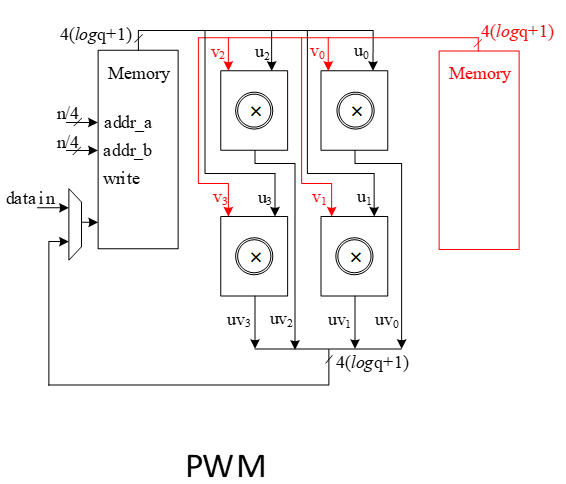
Image not present in this version
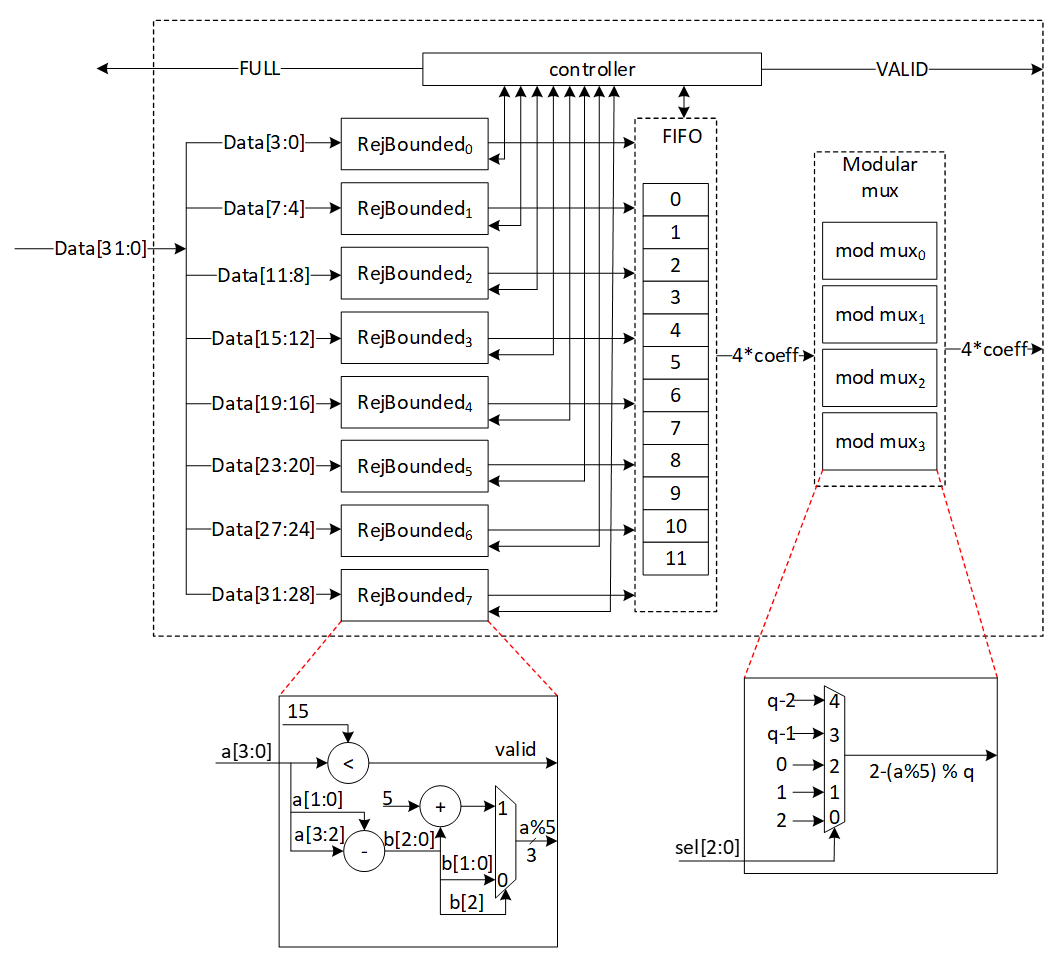
Image not present in this version
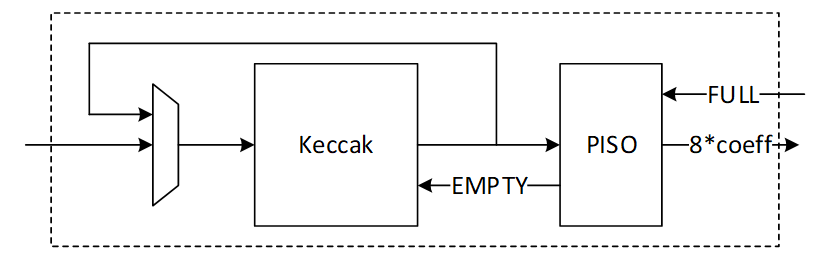
Image not present in this version
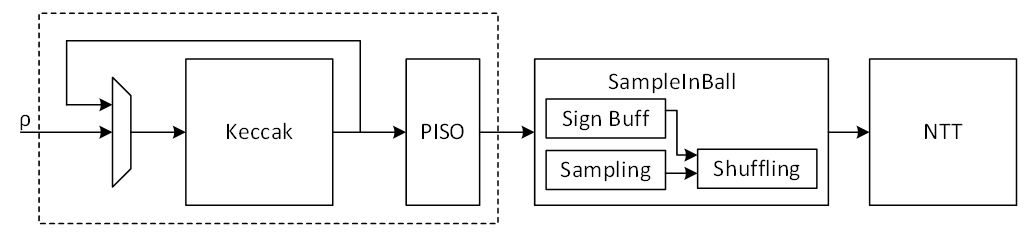
Image not present in this version
Image not present in this version
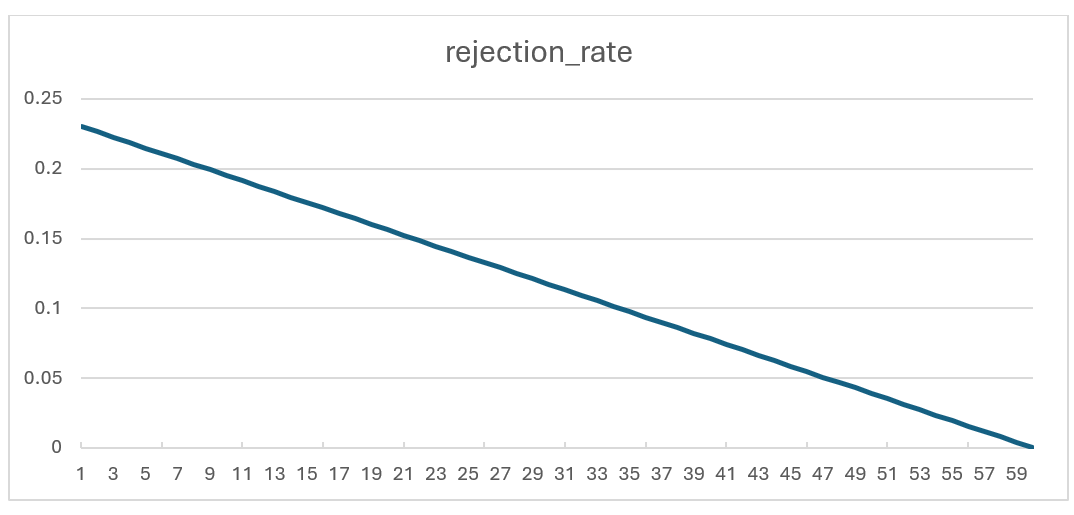
Image not present in this version
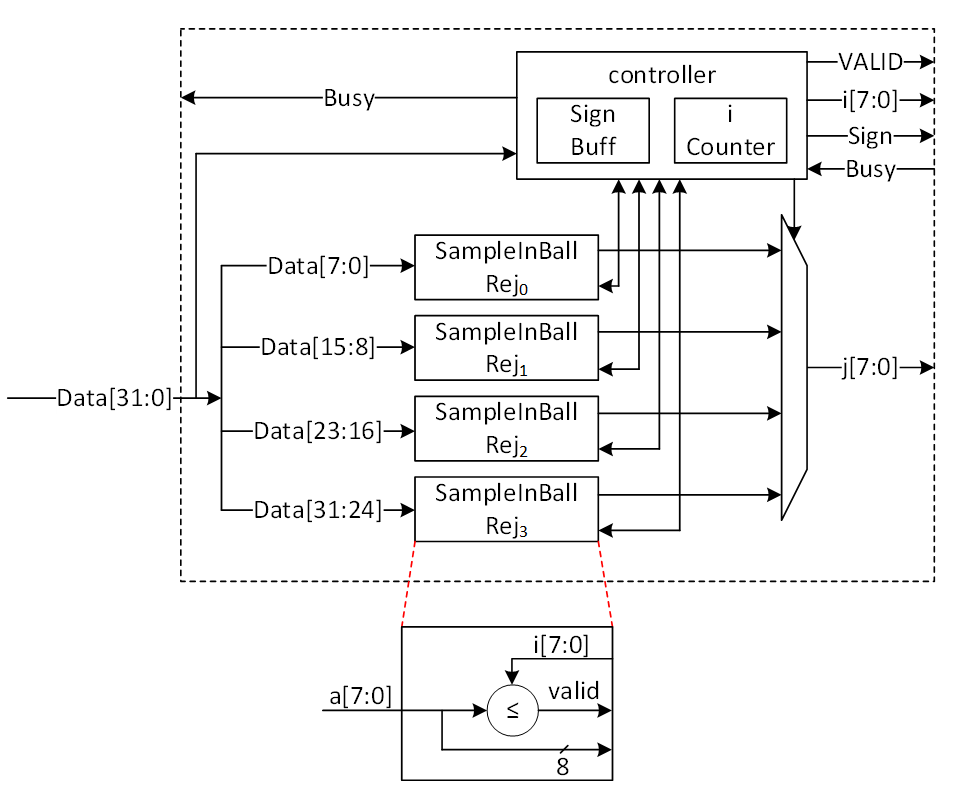
Image not present in this version
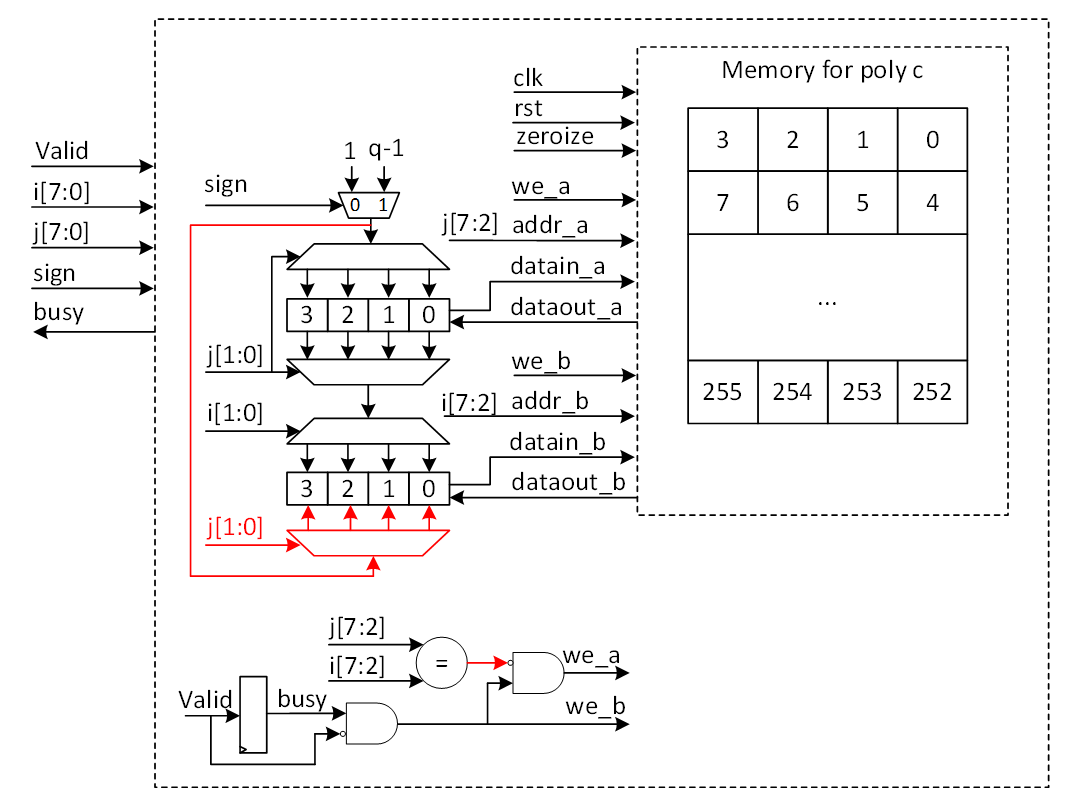
Image not present in this version
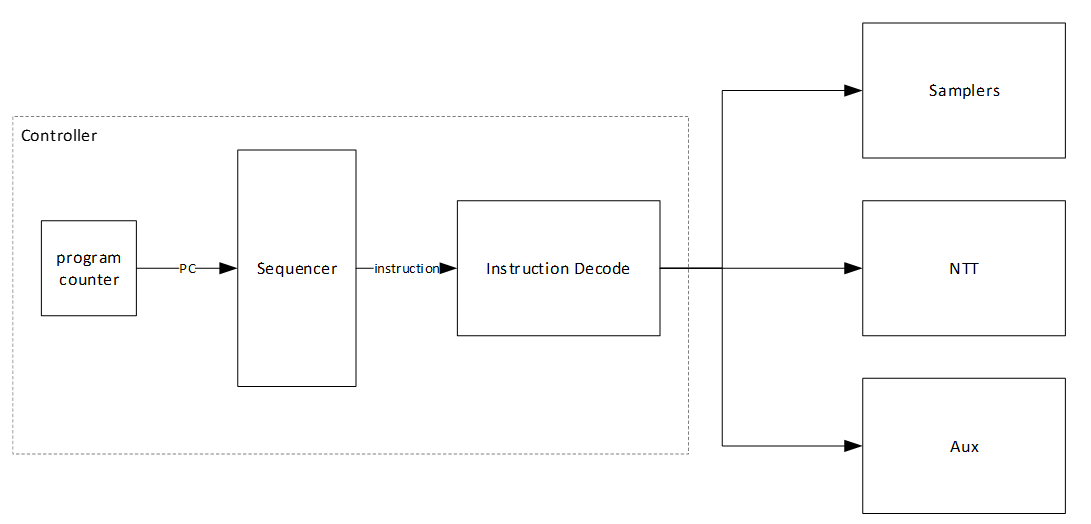
Image not present in this version
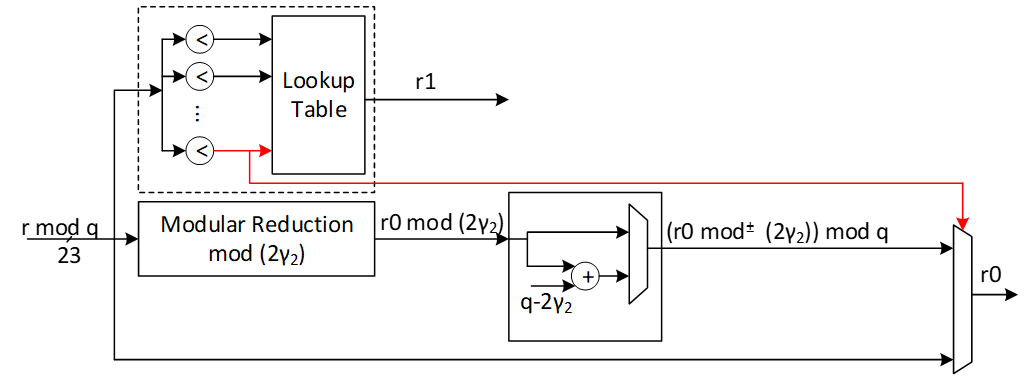
Image not present in this version
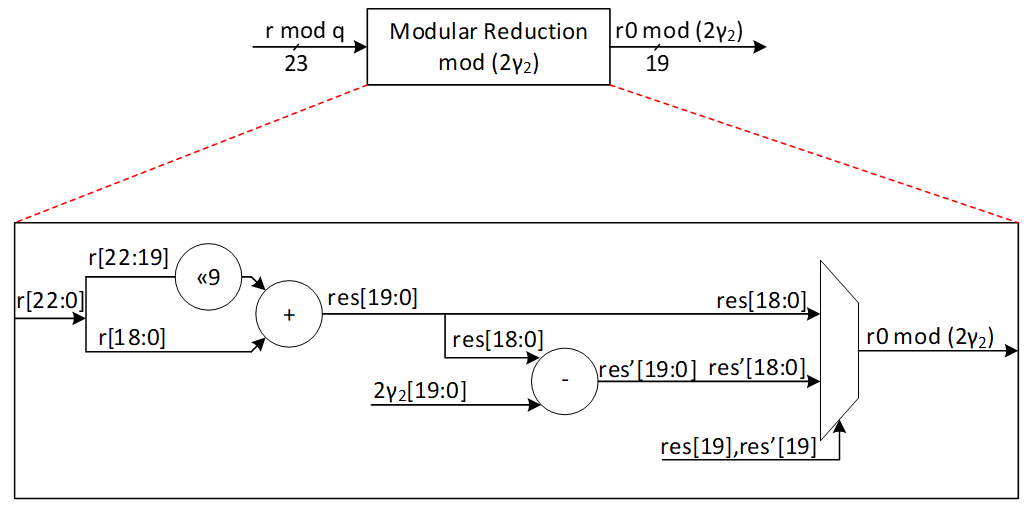
Image not present in this version
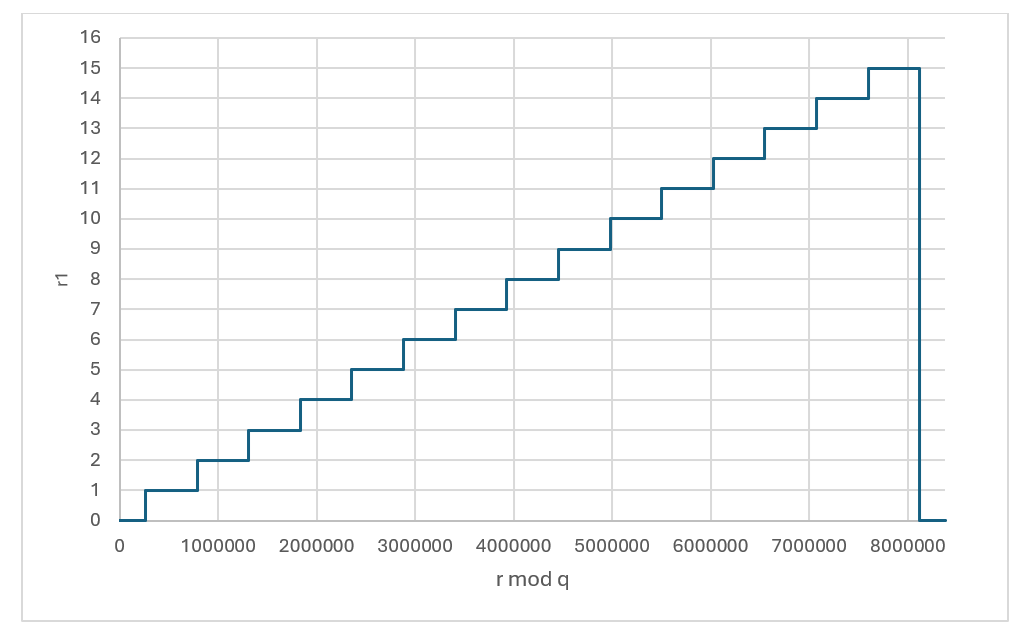
Image not present in this version
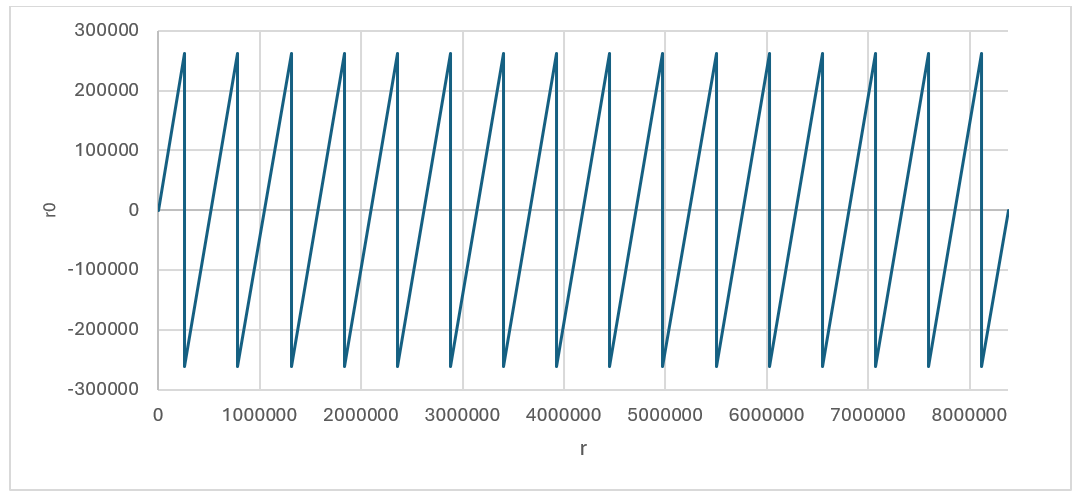
Image not present in this version
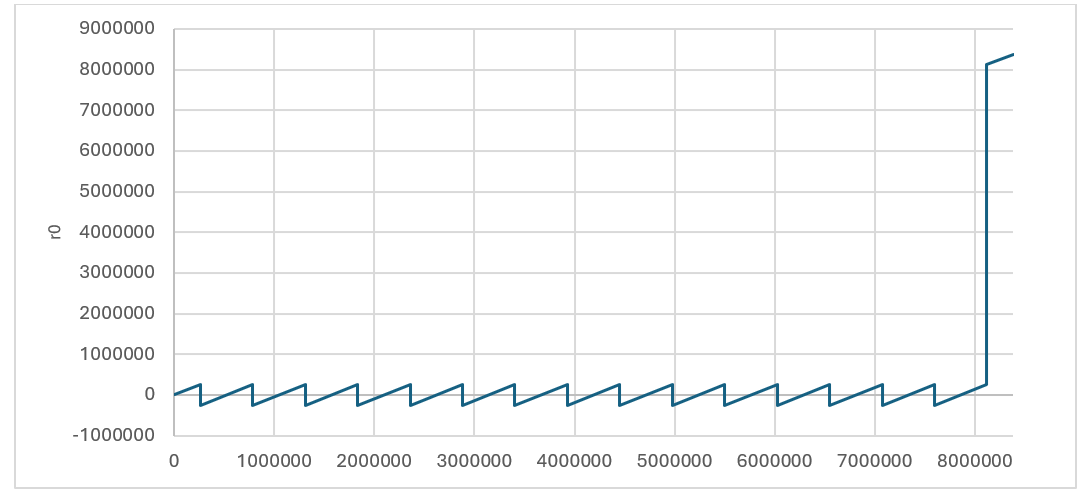
Image not present in this version
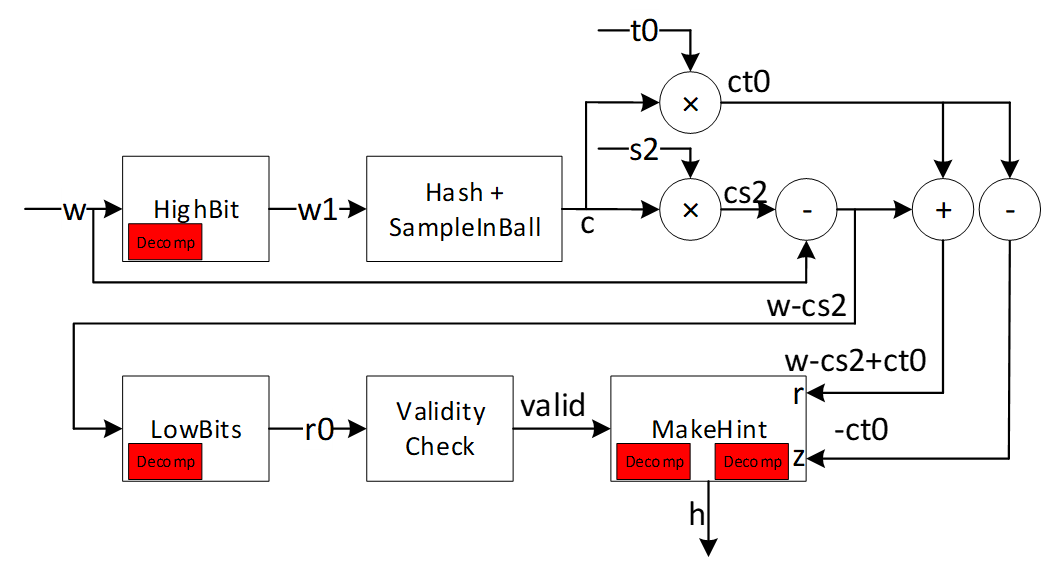
Image not present in this version
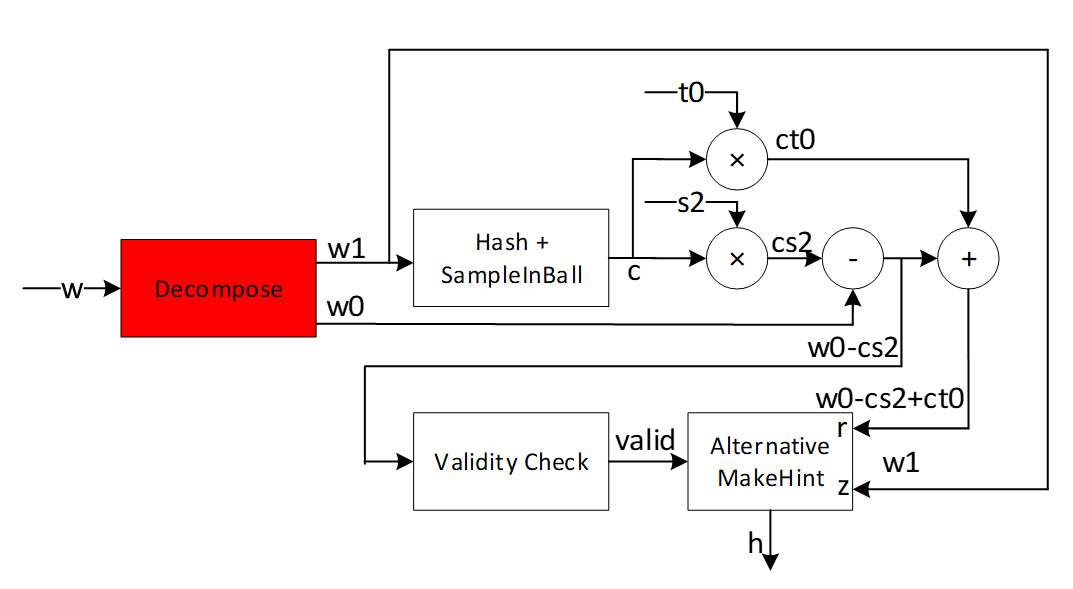
Image not present in this version
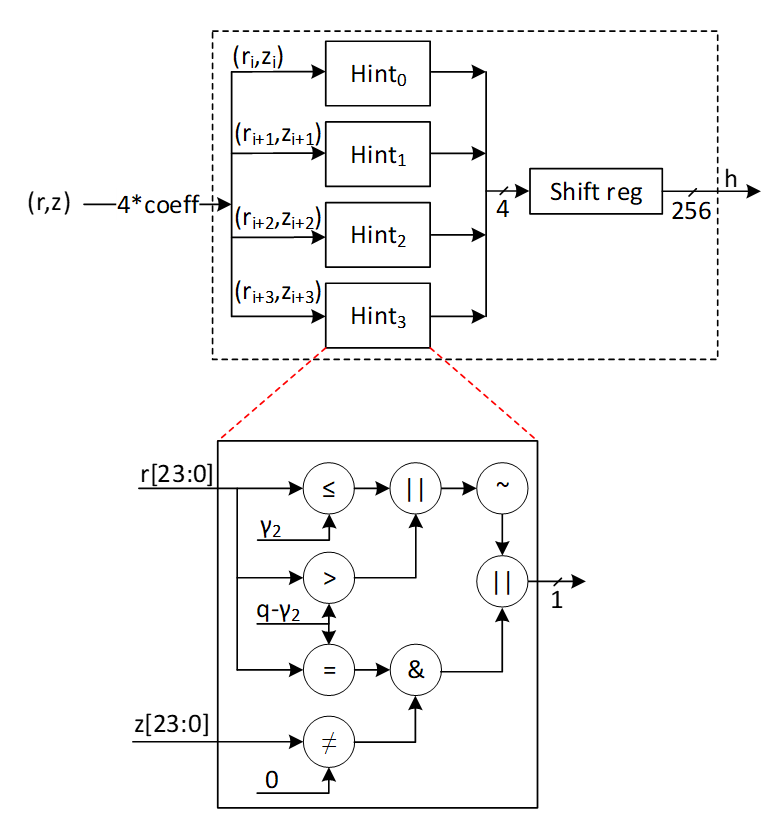
Image not present in this version
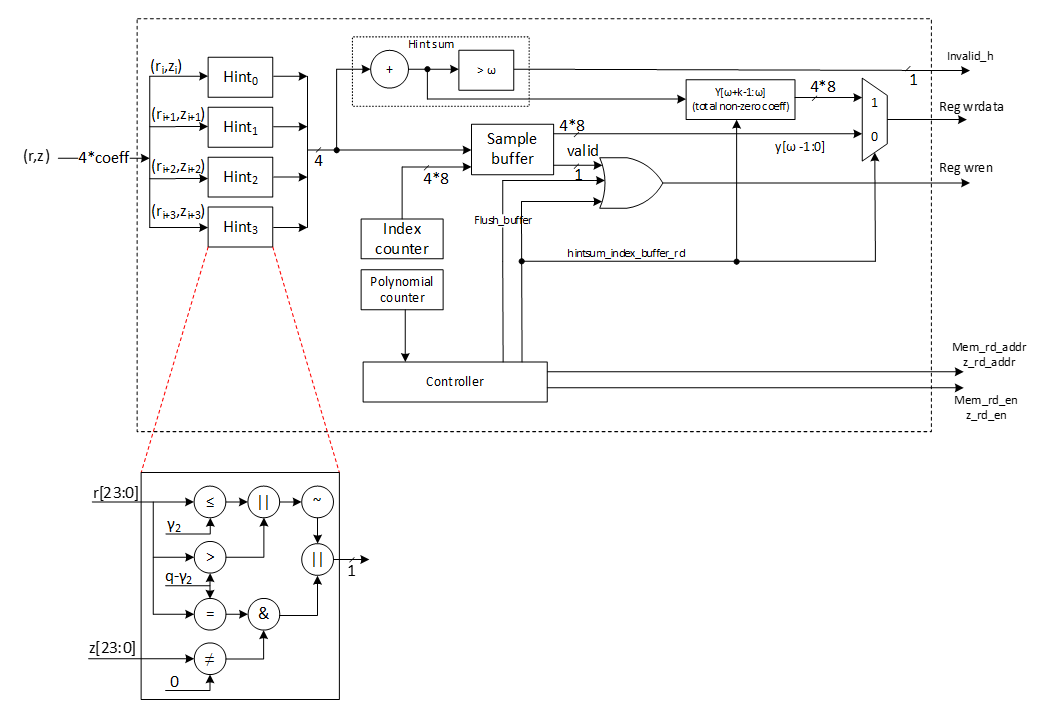
Image not present in this version
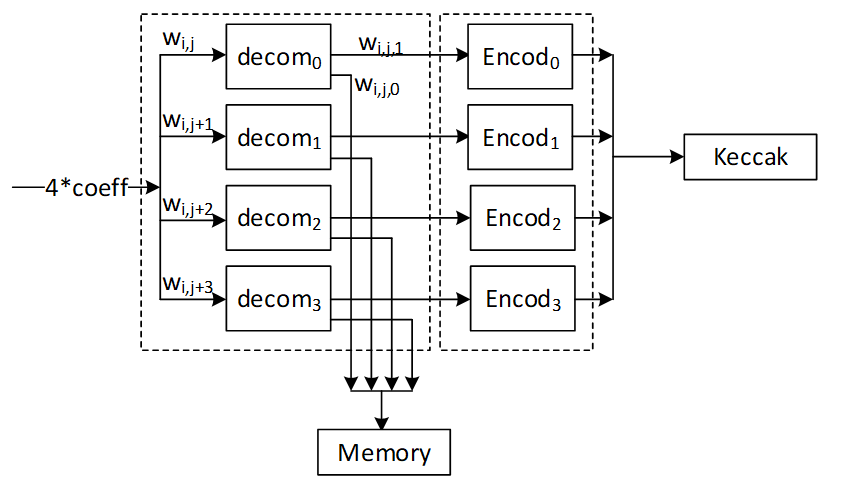
Image not present in this version
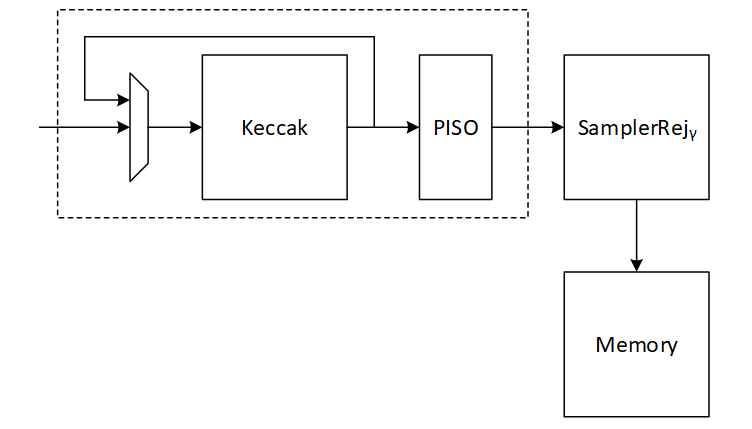
Image not present in this version
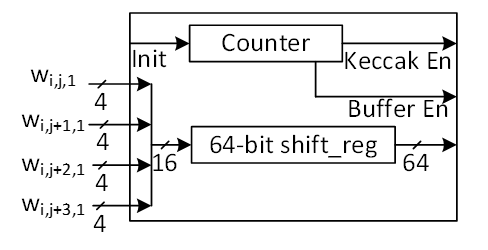
Image not present in this version
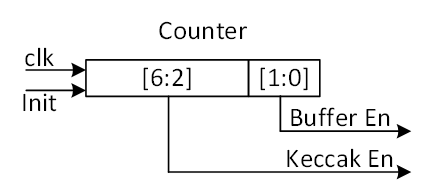
Image not present in this version
Image not present in this version
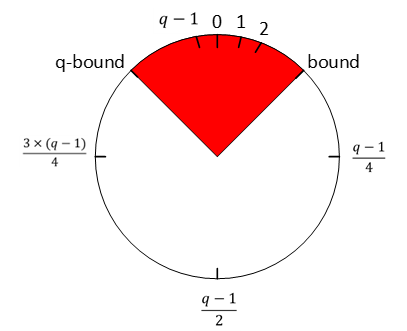
Image not present in this version
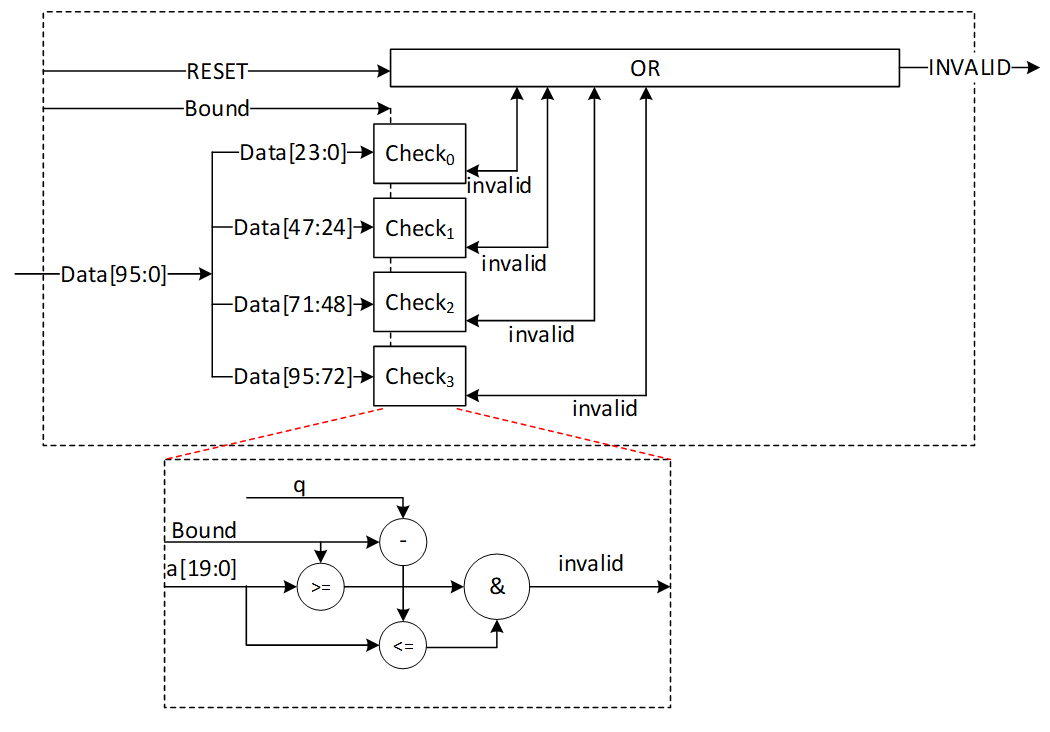
Image not present in this version
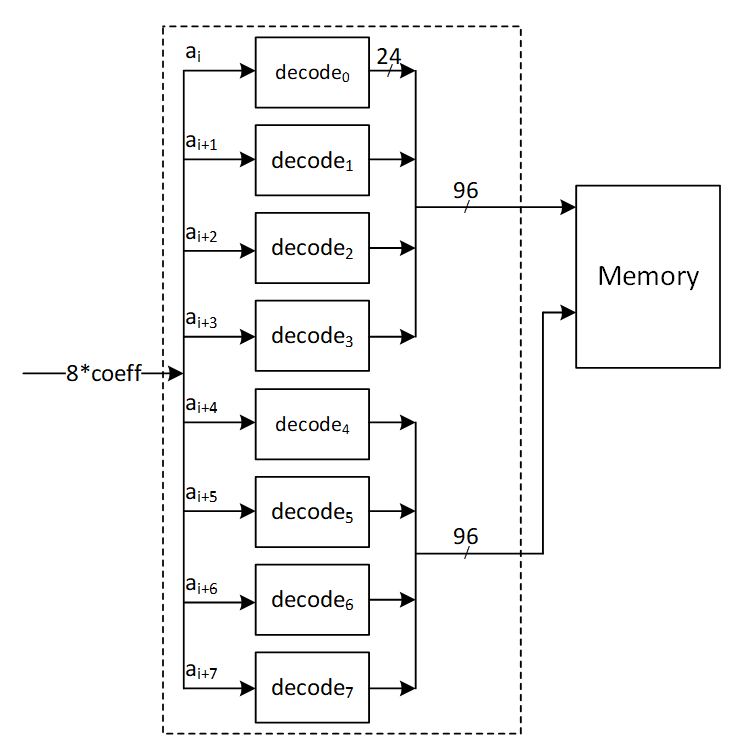
Image not present in this version
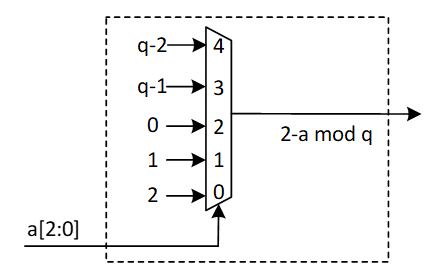
Image not present in this version
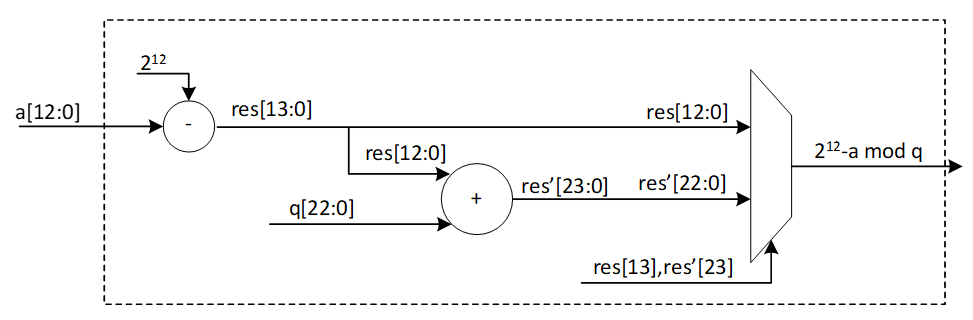
Image not present in this version
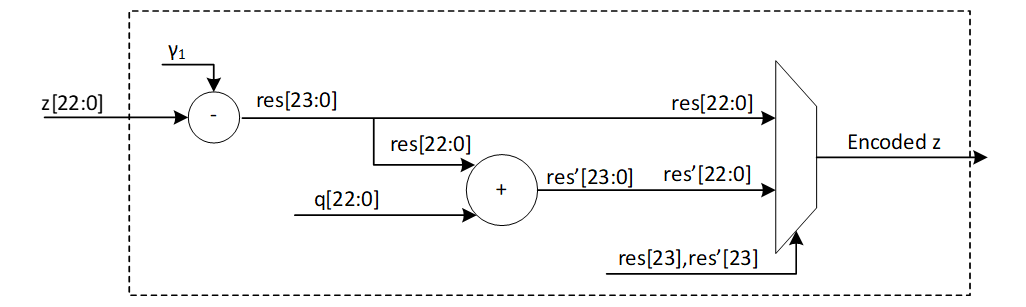
Image not present in this version
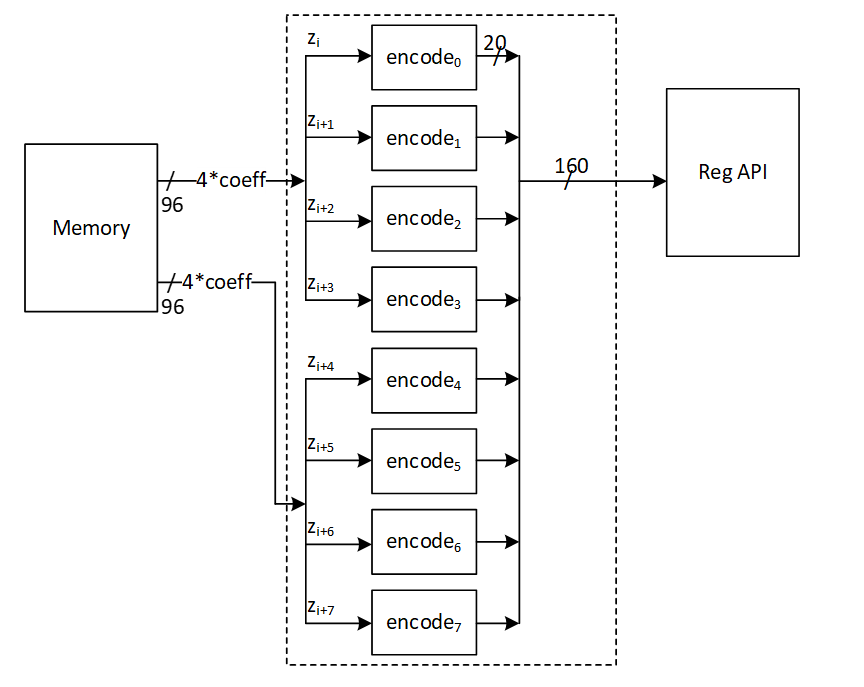
Image not present in this version
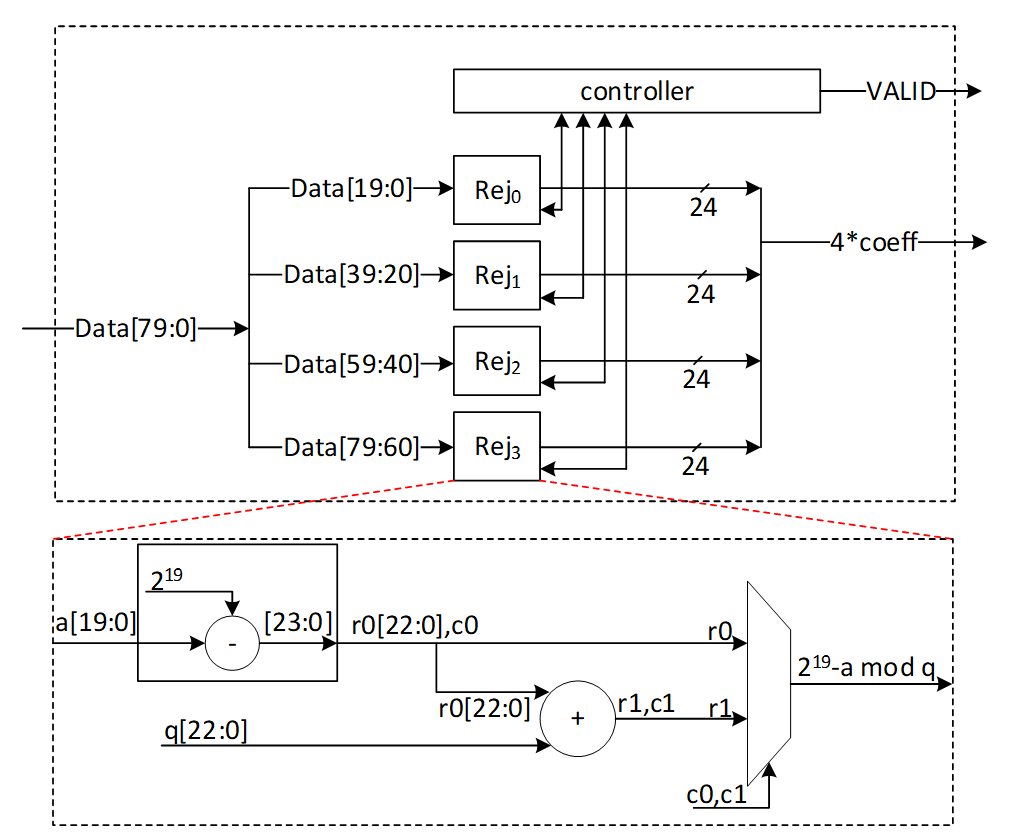
Image not present in this version

Image not present in this version
Image not present in this version
Image not present in this version
Image not present in this version
Image not present in this version
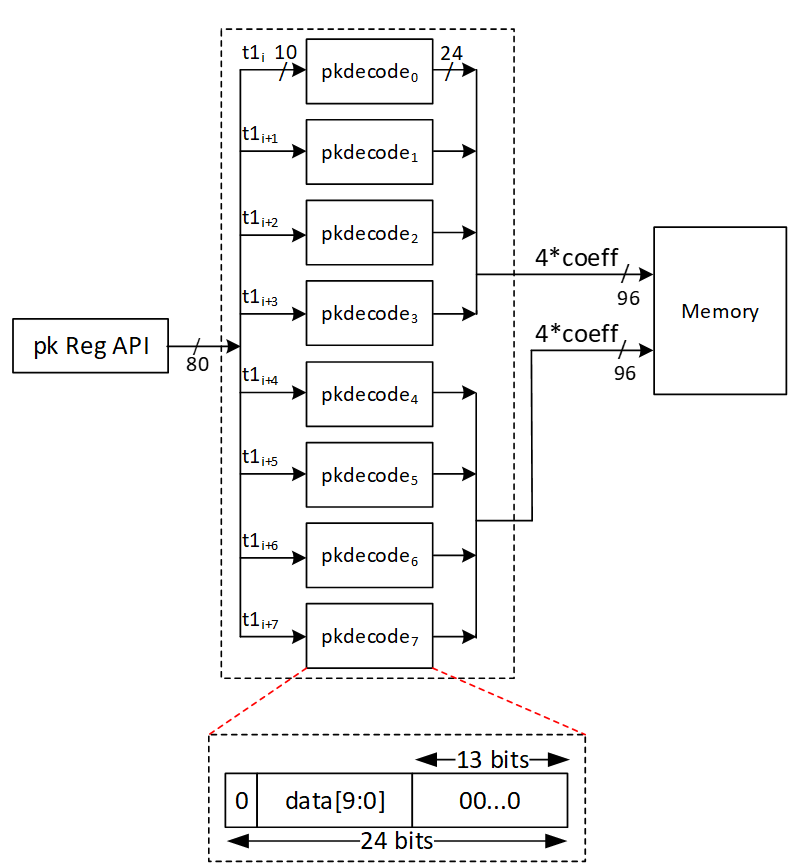
Image not present in this version
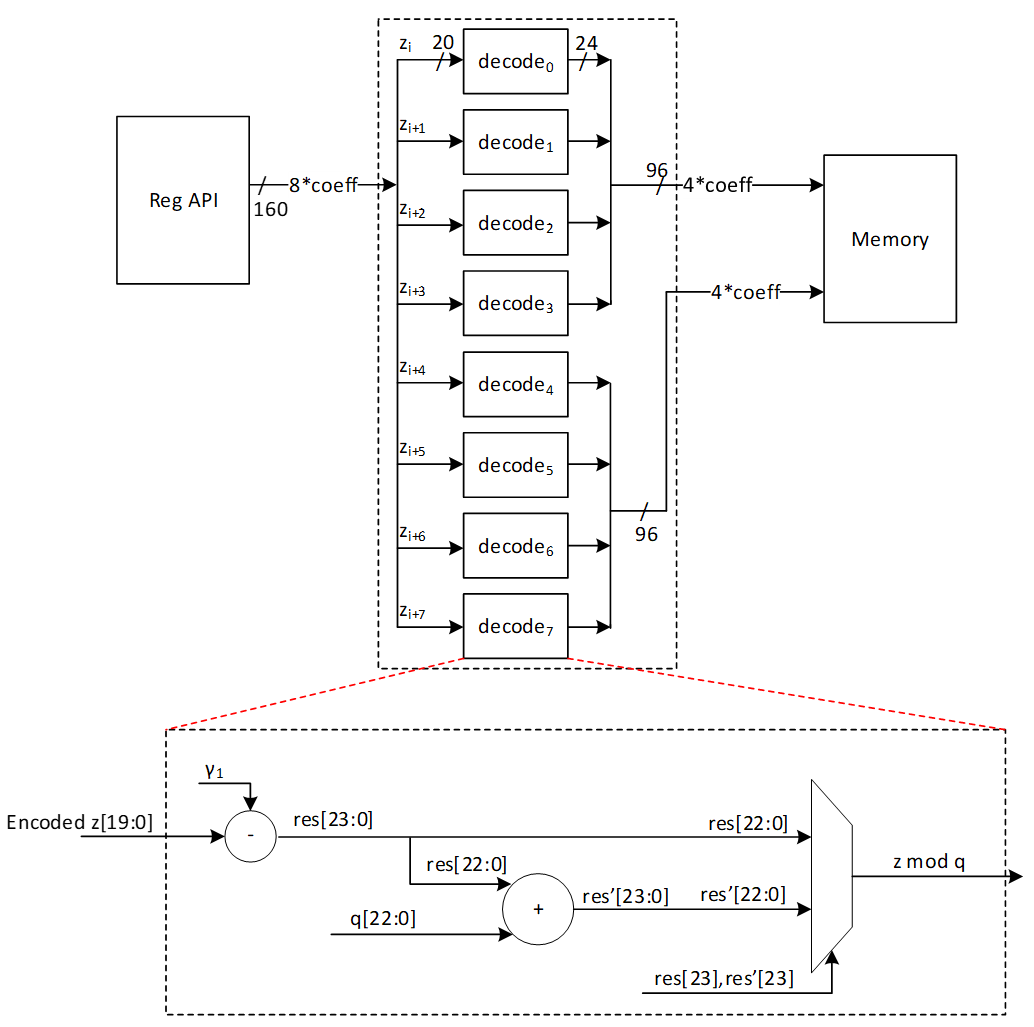
Image not present in this version
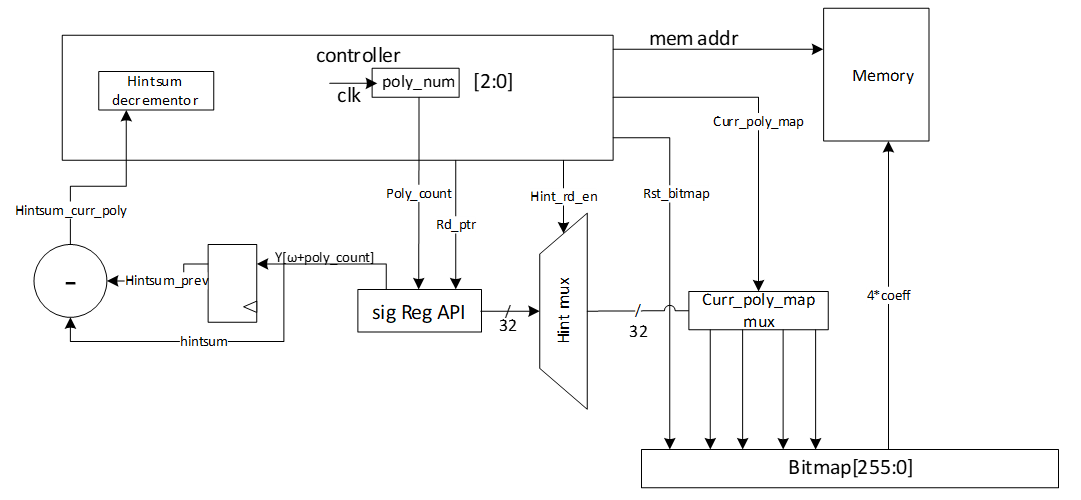
Image not present in this version
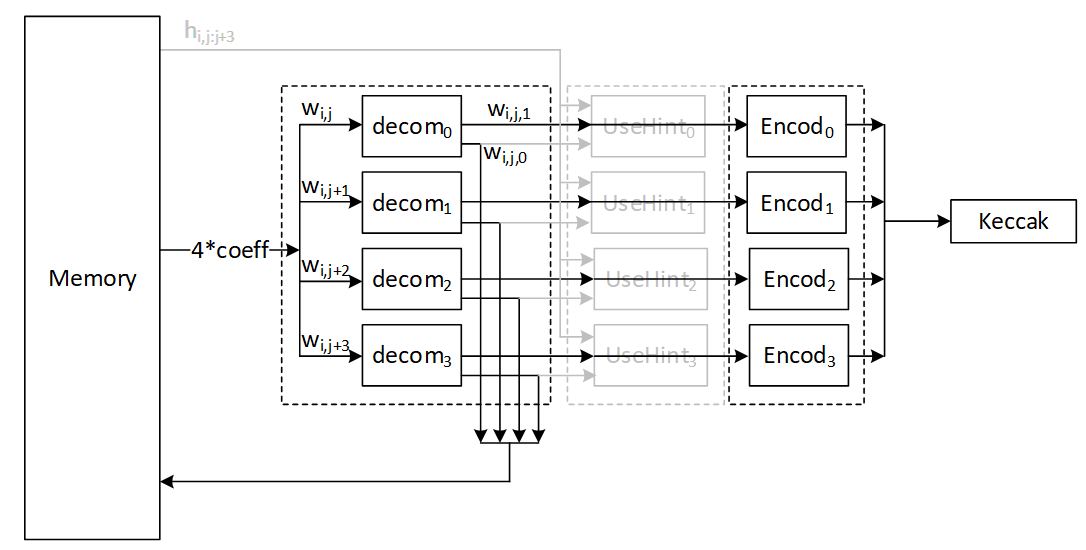
Image not present in this version
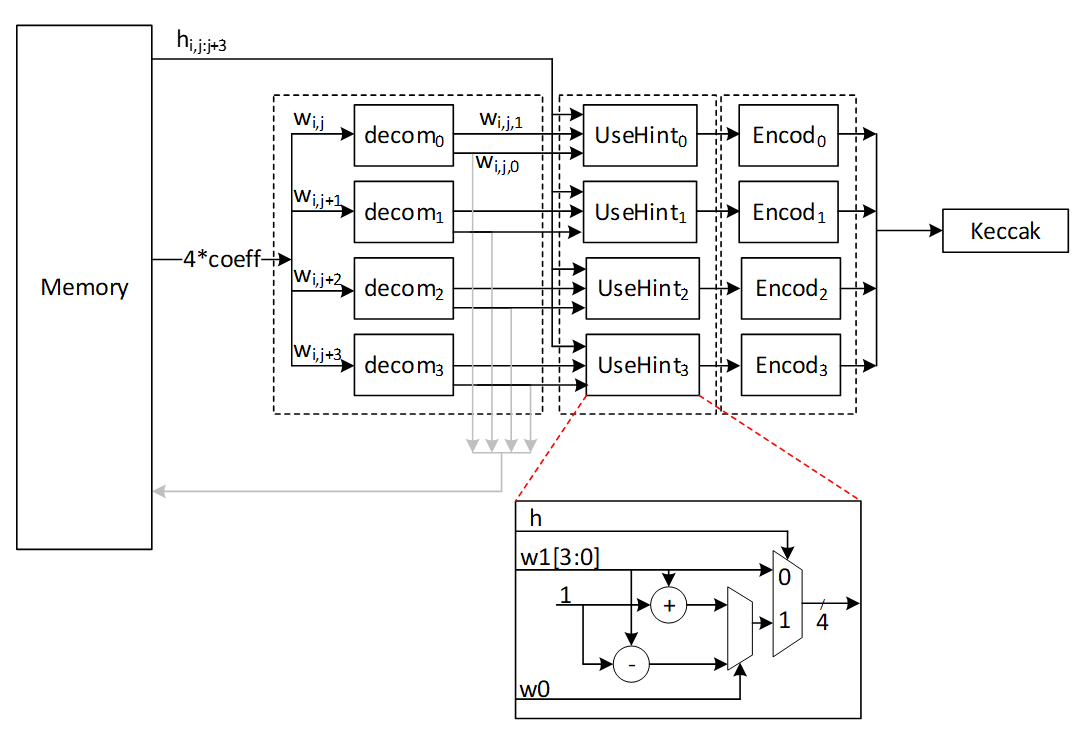
Image not present in this version
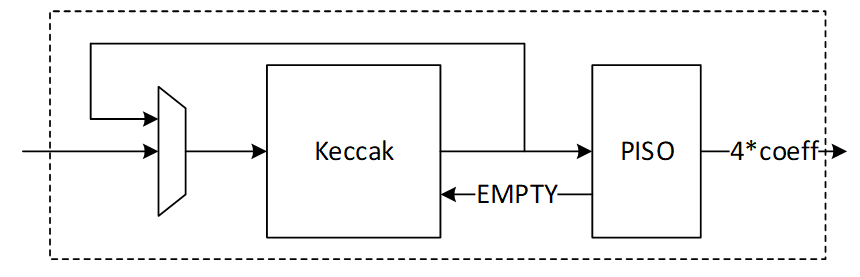
Image not present in this version

Image not present in this version
Image not present in this version

Image not present in this version

Image not present in this version
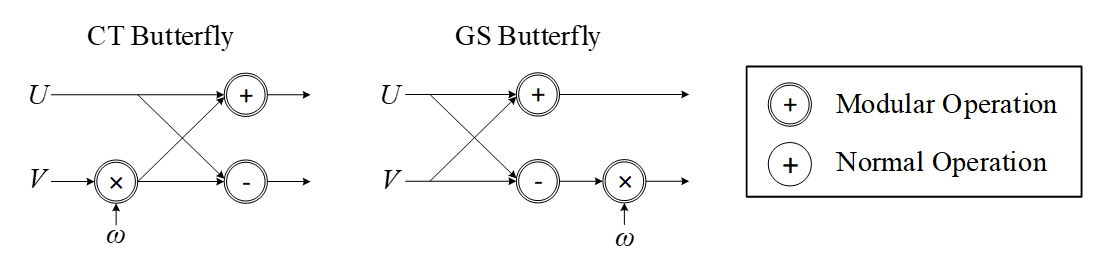
Image not present in this version
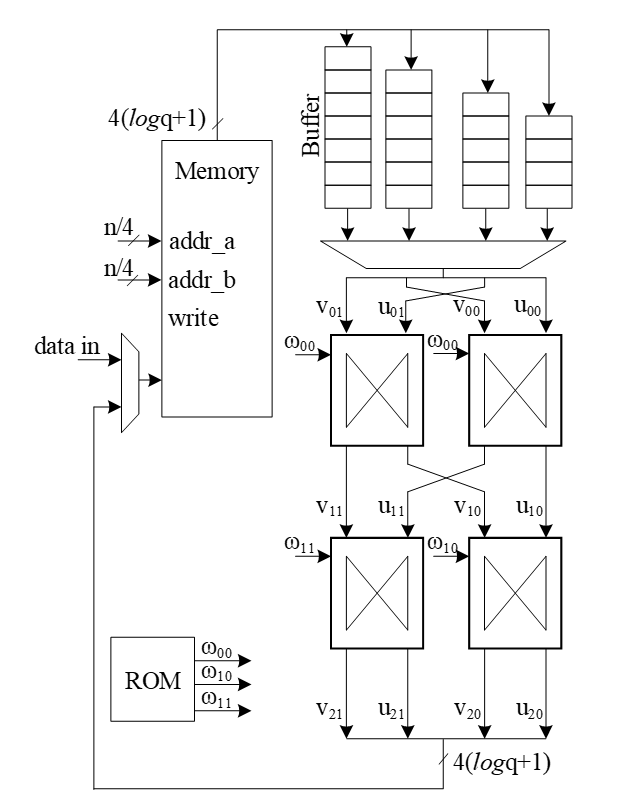
Image not present in this version
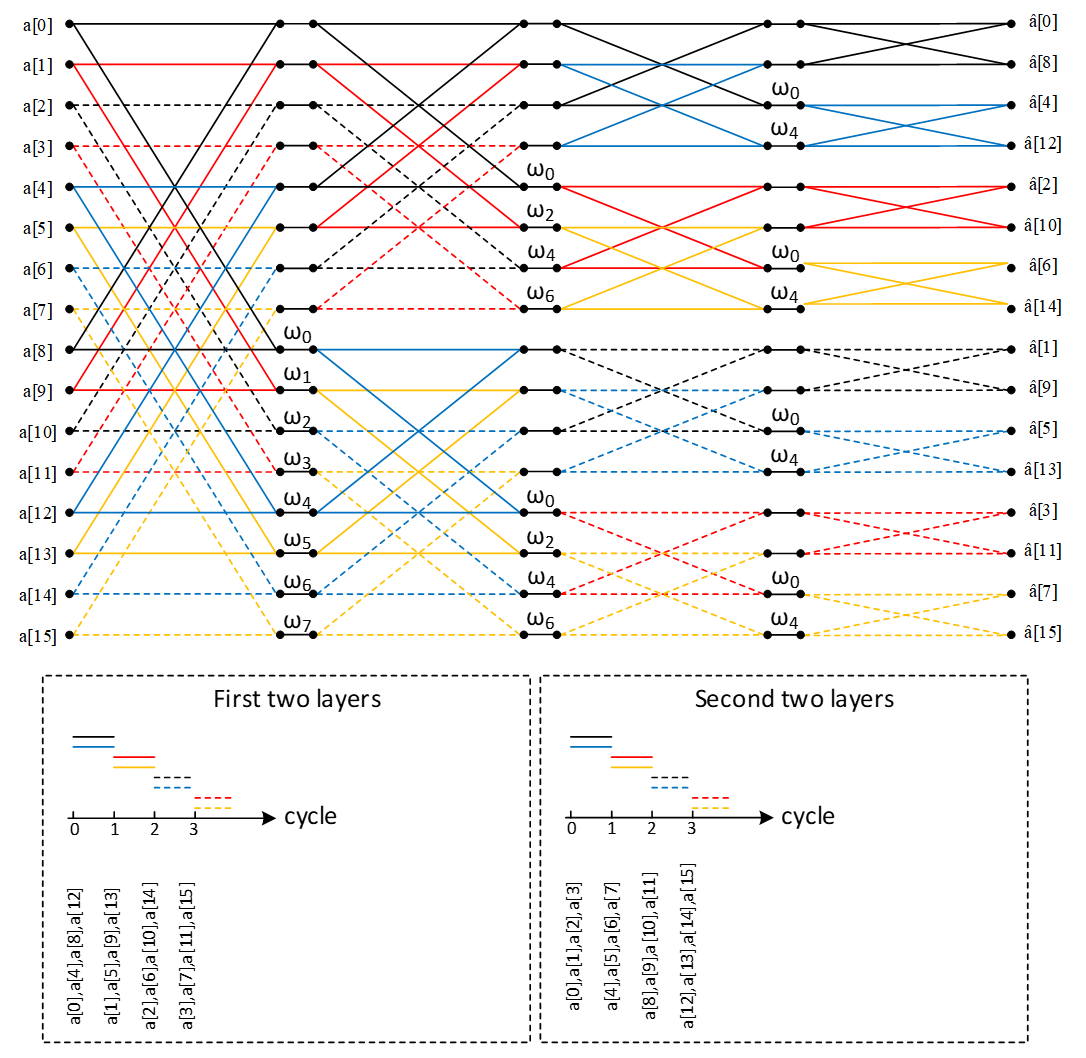
Image not present in this version